画像認識AIとは?生成AIがもたらす「見る」から「理解する」知能への進化
画像認識AIと聞いて、単に「画像に写っているものを当てる技術」を想像していませんか?2026年現在、その常識は大きく覆されつつあります。変化の核にあるのが生成AIとの融合であり、AIは物体を「見る」だけでなく、その画像が持つ意味や文脈を深く「理解する」知能へと進化を遂げました。特に、テキストや音声など複数の情報を同時に扱うマルチモーダルAIの登場は、この変革を決定づけています。本章では、この質的転換が具体的に何を意味するのか、その本質に迫ります。
単なる「目」ではない!AIが画像の意味を理解する仕組み
従来のAIが画像をピクセルの集合体として捉え「これは犬」と分類していたのに対し、現代のAIは根本的に異なるアプローチをとります。その核心にあるのが、マルチモーダルAIの技術です。例えば、Googleが発表した「Gemini Embedding 2」は、画像、テキスト、音声といった異なる情報を「共通のベクトル空間」と呼ばれる数学的な座標上で扱います。これにより、「楽しそうに走る犬」の画像と「喜び」というテキストが、空間上で近い位置に配置されるのです。この関連付けこそが、AIが画像の持つ雰囲気や文脈といった抽象的な「意味」を理解する仕組みであり、自律的に行動するAIエージェントの本質にも繋がる重要な一歩だ。
あわせて読みたい
ai エージェント とはについて、導入方法から活用事例まで詳しく解説します。
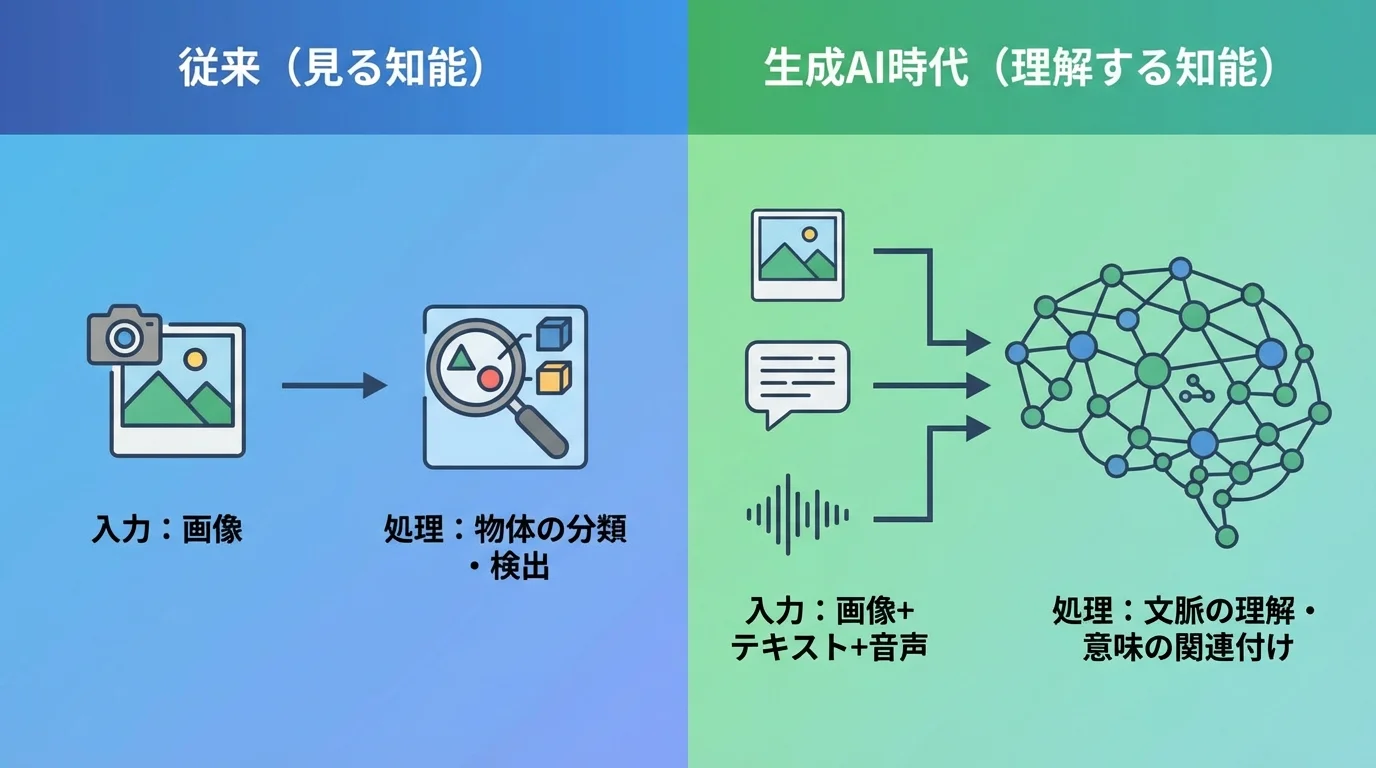
生成AIとの融合で加速する「文脈理解」という新潮流
生成AIとの融合は、この文脈理解の流れを劇的に加速させます。単に状況を理解するだけでなく、その文脈に基づいて「次の一手」を自ら生み出したり、物理的な行動を起こしたりする段階へと進化しているのです。例えば、2026年に発表されたLuma AIの「Uni-1」は、画像理解と生成能力を一つのモデルに統合しました。これにより、AIは不足している学習データをシンセティックデータとして自ら生成し、自身の認識精度を高めるという自己進化のサイクルを生み出す。さらに重要なのが、物理世界での行動へと繋がるフィジカルAIへの展開だ。Vision-Language-Action (VLA) モデルは、カメラ映像から状況を理解し、ロボットアームを動かすといった具体的な行動を実行する。これは、現実世界の問題解決に直接貢献する知能であり、自律的にタスクをこなすAIエージェントの本質とも深く関わっています。
あわせて読みたいai エージェント とはについて、導入方法から活用事例まで詳しく解説します。
画像と言葉を繋ぐマルチモーダル化が拓く新たな地平
画像とテキストが融合することで、私たちの情報検索や現実世界との関わり方は根底から変わります。例えば、Googleの「かこって検索」機能は、画像内のシャツと靴を同時に認識し、バーチャル試着まで提案する段階に到達しました。これは、単なる物体認識を超え、ユーザーの意図を汲み取ったインタラクティブな体験の提供です。さらに、AIの認識対象は2Dの平面から3Dの空間知能へと拡大しています。LiDAR等のセンサーと連携し、物体間の関係性や距離を正確に把握するこの能力は、自動運転やロボティクス分野で進化する画像認識AIの応用を加速させるだろう。こうした高度な処理をスマートフォン等のエッジAIでリアルタイムに実行する技術も進化しており、デジタルと物理世界を繋ぐ新たな地平が、今まさに拓かれつつあるのです。
あわせて読みたい
画像 認識 ai 活用 事例について、導入方法から活用事例まで詳しく解説します。
進化する画像認識AIの現状と、社会実装が直面する新たな課題
AIの「目」は、ついに物理世界へとその視線を向け始めました。単に画像を理解するだけでなく、ロボットを動かし現実空間でタスクを実行するフィジカルAIが登場するなど、その能力は新次元に達しています。しかし、その輝かしい可能性の裏側で、社会実装は「技術とコスト」という根深い壁に直面しているのが現実です。高度化する知能を、私たちはどうすれば社会の隅々まで安全に届けられるのでしょうか?その最前線と、乗り越えるべき葛藤を深掘りします。
精度向上だけじゃない!マルチモーダルAIが拓く新次元
画像認識の競争軸は、もはや認識率の小数点以下の数値を競う段階にはありません。マルチモーダルAIは、テキストや音声、センサーデータといった異種の情報を組み合わせることで、単眼的な認識を超えた「状況理解」という新次元を拓きました。例えば、「この画像に似ていて、かつ『サステナブル』なコンセプトの商品」といった、抽象的な意図を汲んだ検索が可能になるのです。これは単なる機能向上ではなく、ユーザーの購買行動や情報収集のあり方を根底から変える体験の質的変化だ。
さらに、この統合的な理解力はエッジデバイス上でのリアルタイム処理と結びつき、現実世界に直接作用し始めています。HCLTechとNVIDIAが共同で発表した「VisionX 2.0」は、映像・音声・LiDARデータをエッジ側で統合解析する好例である。工場の生産ラインで微細な製品の傷と稼働音の異常を同時に検知し、事故を未然に防ぐといったなぜ製造業の現場での活用が現実のものとなった。これは、AIがデジタル空間の分析者から、物理世界の安全を守るパートナーへと進化している証左に他ならない。
あわせて読みたい
製造 画像認識 AIについて、導入方法から活用事例まで詳しく解説します。
高度化するAI、社会実装を阻む「技術とコスト」の壁
高度なAIには、人間には見えない脆弱性が潜んでいます。例えば、わずかなノイズでAIを誤認識させる敵対的攻撃は、自動運転車が道路標識を見間違えるといった致命的な事故に直結しかねない、深刻な技術的障壁です。さらに、AIの判断根拠を人間が理解できないブラックボックス問題は、医療診断のような失敗が許されない領域での社会実装を阻む。
経済的な壁もまた大きい。最新モデルの学習に必要な莫大な計算リソースと電力消費は、一部の巨大テック企業以外には手が届かないレベルに達しつつある。特に、AIの進化を支えてきた高品質な学習データが枯渇する「2026年問題」も顕在化しており、これは生成AIの開発コストをさらに押し上げる要因となる。技術的信頼性と経済合理性の両立こそが、今まさに直面している本質的な課題だ。
あわせて読みたい
ai 開発 と はについて、導入方法から活用事例まで詳しく解説します。

物理世界へ進出するAI、その可能性と立ちはだかる障壁
AIが物理的なロボットと結びつき、現実世界で行動するフィジカルAIが本格化しています。これは、カメラ映像から状況を理解し、ロボットアームを動かすといった具体的な行動を可能にするVision-Language-Action (VLA) モデルによって実現されたものです。もはやAIは分析ツールではなく、物流倉庫で商品を仕分けるなど、物理タスクを自律的にこなす労働力へと変貌しつつある。
しかし、その能力は諸刃の剣でもある。わずかなノイズでAIを誤作動させる敵対的攻撃は、自動運転車が道路標識を見間違うなど、人命に関わる事故に直結する深刻な技術的障壁だ。加えて、AIの判断根拠が不明なブラックボックス問題は、失敗が許されない医療分野などでの社会実装を阻害する。さらには、AIの進化を支えてきた高品質な学習データが枯渇する「2026年問題」も顕在化しており、今後の生成AI開発の持続可能性そのものが問われているのである。
あわせて読みたいai 開発 と はについて、導入方法から活用事例まで詳しく解説します。
なぜ今、画像認識AIが変革期を迎えているのか?生成AIとマルチモーダル化が拓く新時代
画像認識AIは、単なる精度向上ではない、根本的な質的転換の時代を迎えています。その原動力こそ、生成AIとの融合であり、画像と言葉の壁を溶かすマルチモーダル化です。AIは物を見るだけの「目」から、対話し、創造する知能へと進化しようとしています。この二つの潮流が、具体的にどのような革命を引き起こしているのか、その本質を解き明かしましょう。
「認識」の限界を突破!生成AIがもたらす質的転換
従来の画像認識が「これは何か?」という問いに答える技術だったとすれば、生成AIとの融合はその問い自体を過去のものにしました。今やAIは、自らが認識した世界を基に「これをどう変えるか?」「ここに何を加えるか?」という創造の領域に踏み込んでいます。その核心にあるのが、AI自身が学習データを生成するシンセティックデータの活用です。これにより、データ不足を自ら克服し、自己進化するサイクルが生まれました。さらに、Luma AIが発表した「Uni-1」のように、理解と生成を統合したモデルは、単に状況を分析するだけでなく、その文脈に沿った新たな画像を創出する。これは、生成AIとは何かという概念を再定義する動きであり、画像認識が「解答」から「創造」へと質的転換を遂げた証左だ。
あわせて読みたい
生成 ai とはについて、導入方法から活用事例まで詳しく解説します。
画像とテキストの壁を溶解、マルチモーダル化の衝撃
かつて画像と言葉は、AIにとって別々の世界に存在する情報でした。しかし、マルチモーダルAIの登場がその壁を完全に溶かしてしまったのです。もはやAIは、画像を見て「これはシャツだ」と答えるだけの存在ではありません。「このシャツと靴を組み合わせたい」という人間の意図を汲み取り、次のアクションを提案する対話型のパートナーへと変貌しました。その象徴が、2026年に強化されたGoogleの「かこって検索」機能だ。画像内のシャツと靴を同時に認識し、検索するだけでなく、自身の写真に合成して試着イメージを確認できるバーチャル試着まで実現する。これは、AIが画像(モノ)とテキスト(ユーザーの意図)をシームレスに往復し、現実世界の問題解決に直接貢献している証拠に他ならない。この画像と言葉の融合は、自律的にタスクをこなすAIエージェントの本質にも直結します。視覚情報から状況を理解し、言語で指示を受け、次の行動を計画する。この一連の流れは、進化する画像認識AIが私たちの創造性を拡張する、新たな時代の幕開けを告げています。
あわせて読みたいai エージェント とはについて、導入方法から活用事例まで詳しく解説します。
画像 認識 ai 活用 事例について、導入方法から活用事例まで詳しく解説します。
「見る」から「対話し創造する」知能への大転換
もはやAIは、画像に何が写っているかを一方的に答えるだけの存在ではない。「この画像をどうしたいですか?」と問いかけ、人間の創造活動に直接介入するパートナーへと変貌しました。例えば、Adobe Photoshopに搭載された「AIアシスタント」は、「背景を宇宙に変えて」といった自然言語での対話を通じて、専門的な編集作業を瞬時に実行する。これは、AIがユーザーの意図を深く理解し、新たなビジュアルを創造する能力を獲得した証拠だ。この変化は、単なるツールとしての進化ではなく、私たちの創造プロセスそのものを変革するものであり、自律的にタスクをこなすAIエージェントの本質にも繋がる大きな一歩である。
あわせて読みたいai エージェント とはについて、導入方法から活用事例まで詳しく解説します。
2026年最新動向:マルチモーダル化と物理世界への進出が加速する画像認識AIの最前線
画像認識AIは、もはや実験室の技術ではありません。2026年、その知性は画像やテキストの壁を越え、音声や動画をも統合的に理解するマルチモーダルの領域へ到達しました。さらに重要なのは、その知能がクラウドから飛び出し、エッジAIとして物理世界でリアルタイムに行動を開始したという事実です。「認識」から「実行」へ。私たちの生活空間で動き始めたAIの最前線では、今、何が起きているのでしょうか。
画像だけじゃない!音声・動画も統合処理するAI最前線
AIの認識能力は、ついに「耳」を獲得し、時間軸を持つデータ、すなわち音声や動画の領域へと拡大しました。もはやAIは静止画を解読するだけの存在ではありません。動画内の人物の表情と声のトーンを同時に分析し、その感情を読み取るなど、マルチモーダルAIは映像と音声を統合して「文脈」を捉える段階にあります。この能力は、単に動画検索を便利にするだけでなく、現実世界の問題解決に直結するのだ。例えば、HCLTechとNVIDIAが共同開発した「VisionX 2.0」は、工場の生産ラインで製品の微細な傷(映像)と機械の異常音(音声)をエッジデバイス上でリアルタイムに検知する。これは、なぜ製造業の現場で予知保全を劇的に変える力を持つ技術である。静的な「モノ」の認識から、動的な「コト」の理解へ。進化する画像認識AIは、私たちの世界をより深く、多角的に捉える知能へと進化を遂げています。
あわせて読みたい製造 画像認識 AIについて、導入方法から活用事例まで詳しく解説します。
画像 認識 ai 活用 事例について、導入方法から活用事例まで詳しく解説します。
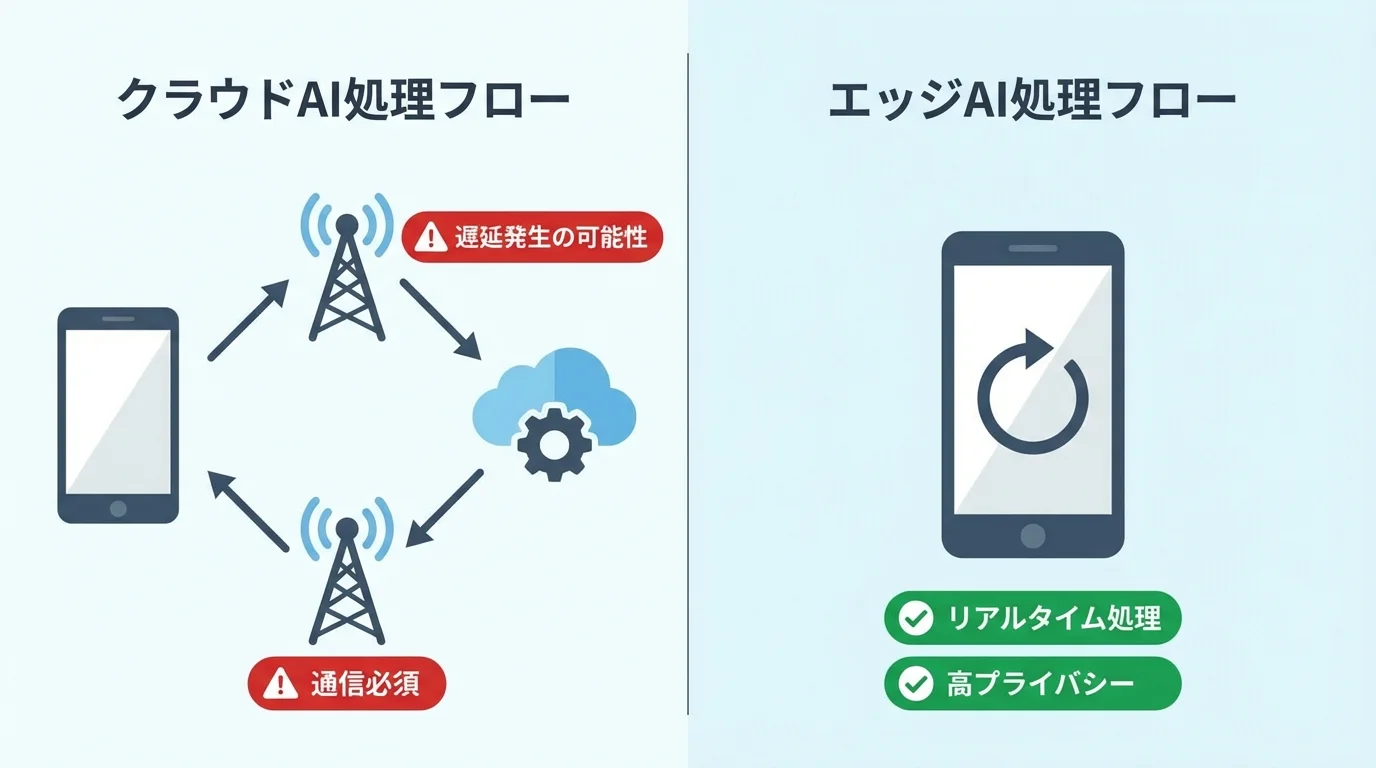
エッジAIが鍵、物理世界とリアルタイムに連携する新次元
クラウドの巨大な頭脳に頼る時代は、終わりを告げようとしています。物理世界でAIが本当に役立つためには、コンマ数秒の通信遅延すら許されない場面があるからです。例えば自動運転を考えてみてください。前方の歩行者を認識してからブレーキを判断するまで、クラウドにデータを送受信する猶予はありません。この「時間」と「場所」の制約を打ち破るのがエッジAIだ。
デバイス自体が高度な判断能力を持つことで、通信を介さずにリアルタイムで状況を理解し、行動できる。さらに、顔認証データのような機密情報をデバイス内で完結させることは、プライバシー保護の観点からも決定的に重要である。この即時性と安全性こそが、進化する画像認識AIが私たちの生活空間に溶け込むための必須条件であり、AIがデジタル空間の分析者から物理世界の実行者へと変わる、真の新次元を切り拓く鍵なのです。
あわせて読みたい画像 認識 ai 活用 事例について、導入方法から活用事例まで詳しく解説します。
「認識」から「実行」へ、AIの社会実装が迎えた新局面
画像認識AIは、もはや単なる分析ツールではない。カメラ映像から状況を理解し、ロボットを動かすVision-Language-Action (VLA) モデルの登場により、AIは物理的なタスクを自らこなす「実行者」へとその役割を変えた。例えば、物流倉庫では、ロボットが商品の形状や状態をリアルタイムで判断し、最適な掴み方でピッキングする。これは、決められた動きを繰り返す従来の自動化とは一線を画す、状況判断を伴う自律的な「実行」だ。こうした動きこそ、物流のAI画像認識はなぜ進むのかという問いへの明確な答えである。この変化は、AIが人間と協働し、あるいは代替する労働力として社会に実装される新時代の到来を告げている。
あわせて読みたい
物流 画像認識 AIについて、導入方法から活用事例まで詳しく解説します。
画像認識AIの未来予測:あらゆる産業を再定義する「統合知能」への道
画像やテキスト、音声、そして物理的な行動までを繋ぎ始めたAI。しかし、この進化の終着点は、単なる機能の寄せ集めなのでしょうか。私たちは今、個別の認識技術が融合し、真の統合知能が誕生する時代の入り口に立っています。この新たな知性は、製造や医療といった業界の壁を溶かし、専門家の仕事を根底から再定義する。本章では、AIと人が共創する未来の具体的な姿を考察していきましょう。
テキスト・音声を越え、真の統合知能が誕生する日
画像、テキスト、音声といった個別の能力をAIが獲得した今、次なる焦点はそれらの「統合」にあります。しかし、それは単なる機能の足し算ではありません。異なる知覚情報を有機的に結合させ、人間のように複雑な文脈を理解する統合知能の誕生です。例えば医療現場を想像してみてください。統合知能は、MRI画像から腫瘍の形状を読み解くだけでなく、同時に患者の電子カルテ(テキスト)と心音データ(音声)を解析します。これにより、単一の専門医では見逃しかねない、複数の要因が絡み合った疾患の予兆を捉えることが可能になる。これはもはや診断支援ではなく、新たな医学的知見の発見に近い。専門分野の壁を越えて知識を関連付ける能力こそが統合知能の本質であり、自律的に思考し行動するAIエージェントの本質が、産業構造そのものを再定義する未来の姿に他ならないのです。
あわせて読みたいai エージェント とはについて、導入方法から活用事例まで詳しく解説します。
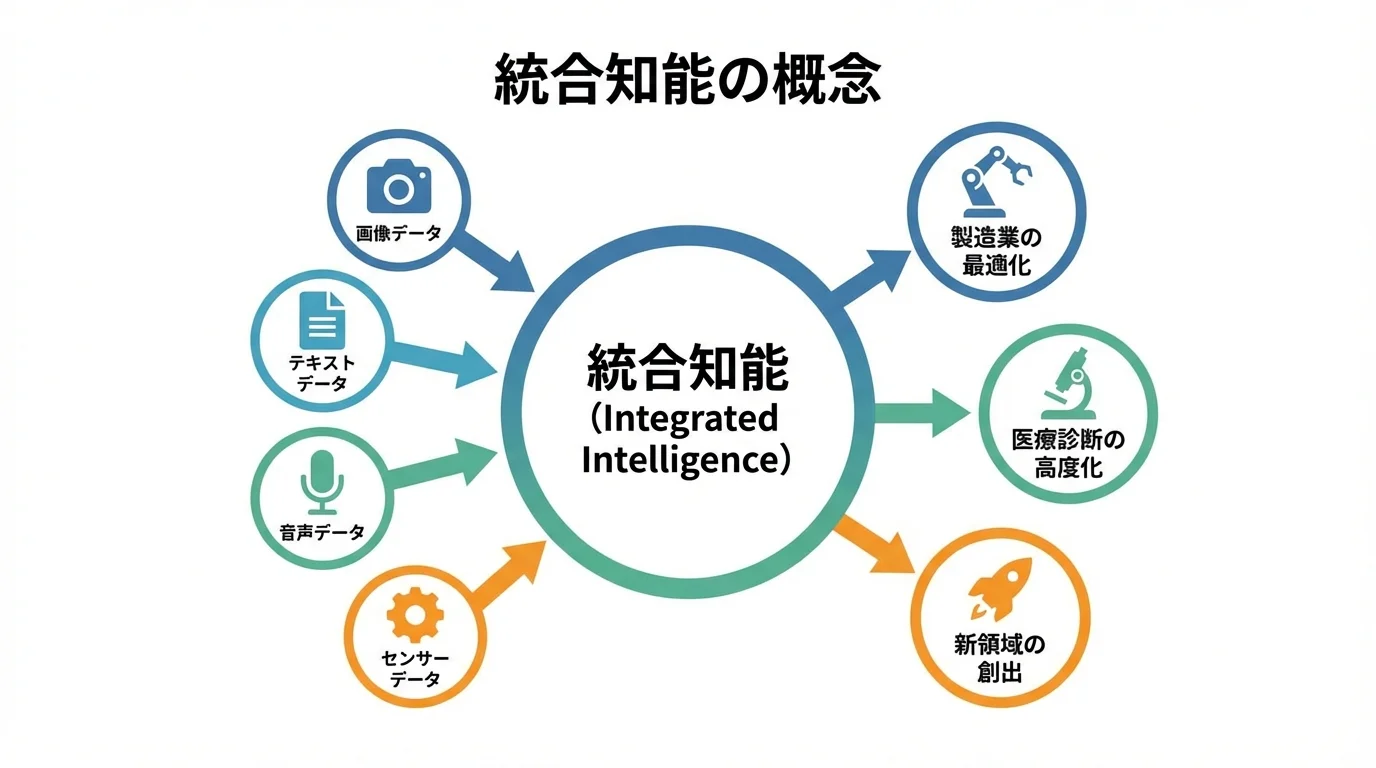
製造から医療まで、業界の壁を溶かすAIの未来像
AIが可能にするのは、単一業務の自動化ではありません。業界ごとにサイロ化された専門知識の壁を破壊し、全く異なる分野の知見を結びつける「知識の越境」です。例えば、製造業で培われた新素材の分子構造データと、医療分野の創薬におけるタンパク質解析データを統合知能が解析したとしましょう。AIは、人間では気づき得ない構造上の類似性から、新素材が特定の疾患に対する治療薬の候補となり得る可能性を発見するかもしれない。これはもはや製造でも医療でもない、新たな融合領域の誕生だ。このように、進化する画像認識AIは専門家の知性を拡張し、異分野のデータを触媒として未知のイノベーションを生み出す起爆剤となるのである。
あわせて読みたい画像 認識 ai 活用 事例について、導入方法から活用事例まで詳しく解説します。
専門家の仕事を再定義、AIと人が共創する新時代
AIは専門家の仕事を奪うのではなく、その役割を根本から書き換える共創パートナーへと進化しました。例えば建築家は、もはやゼロから図面を描く必要はありません。「周囲の景観に溶け込むようなデザイン」といった曖昧な指示をAIに与え、膨大な過去の建築データから生成された複数の設計案を基に、より創造的な検討に時間を割くことが可能だ。これは、AIが分析や作図といった定型業務を担い、人間は最終的な美的判断やコンセプトの磨き込みという、本質的な価値創造に集中する新しい協業の形である。これからの専門家に求められるのは、答えを出す能力以上に「正しい問いを立てる能力」だ。どのデータを分析させ、何を創り出させるか。その戦略的な対話こそが、AIエージェントの本質を最大限に引き出し、専門性を次の次元へと高める鍵となる。
あわせて読みたいai エージェント とはについて、導入方法から活用事例まで詳しく解説します。
生成AI時代の波に乗る!ビジネスで画像認識AIを活用するための実践的アプローチ
これまでの章で解説した画像認識AIの驚異的な進化は、もはや他人事ではありません。今、問われているのは、その力をいかにして自社のビジネスに組み込み、具体的な利益へと転換するかという「実践知」です。マルチモーダルAIで既存の業務プロセスをどう再定義するのか?顧客体験を革新するための最初の着眼点はどこにあるのか?本章では、理想論で終わらない、AI導入プロジェクトを成功に導くための具体的なアプローチと必須条件を探ります。
マルチモーダルAIで業務プロセスを再定義する第一歩
マルチモーダルAIの導入を検討する際、多くの企業が壮大な全社改革から構想し、結果として頓挫します。真の第一歩は、既存業務の中に隠れた「複数の情報(モダリティ)」が交差する点を見つけ出すことです。例えば、顧客サポート部門が受け取る画像付きの問い合わせメールを考えてみましょう。従来は担当者が画像とテキストを目で見て判断していましたが、ここにマルチモーダルAIを適用します。Googleの「Gemini Embedding 2」のような技術は、製品の破損状況を写した画像と「至急交換してほしい」というテキストの緊急度を統合的に理解し、瞬時に対応の優先順位を判断することが可能です。これは単なる自動化ではなく、顧客体験を向上させる業務プロセスの再定義に他なりません。大切なのは、最初から完璧を目指すのではなく、AI PoCとは単なる実験に終わらない、測定可能な小さな成功を積み重ねていく姿勢なのです。
あわせて読みたい
ai poc とはについて、導入方法から活用事例まで詳しく解説します。
顧客体験の革新から始める、AI活用プロジェクトの着眼点
AI導入プロジェクトが技術の実証実験で終わってしまう原因は、往々にして「何ができるか」から発想する点にあります。しかし、真に成功するプロジェクトの着眼点は、常に顧客体験(CX)の革新から始まります。例えば、2026年に強化されたGoogleの「かこって検索」は、単に物体を認識する技術ではありません。画像内のシャツと靴を認識し、バーチャル試着まで提案することで、「店舗に行かずにコーディネートを試したい」という顧客の根本的な欲求に応えているのです。あなたのビジネスにおいて、顧客はどこで「面倒だ」と感じ、何に「迷って」いるでしょうか。その具体的なペインポイントこそが、AIを適用すべき最適な場所です。高度な技術を追い求める前に、まず顧客の「不満」を起点に考えること。それが、進化する画像認識AIを単なるコストではなく、確実な利益へと繋げるための最も重要な第一歩である。
あわせて読みたい画像 認識 ai 活用 事例について、導入方法から活用事例まで詳しく解説します。
ツール選定と費用対効果、AI導入を成功させる必須条件
AI導入を成功させる鍵は、最新技術を追いかけることではなく、自社の課題とリソースに最適なツールを選び、冷静に費用対効果を見極めることにあります。手軽に始めるならGoogle Cloud Vision AIのようなAPIを利用する選択肢がある一方、独自の強みを築くなら既存モデルを調整するファインチューニングが有効だ。しかし、見落とされがちなのが、アノテーション(正解ラベル付け)といったデータ準備にかかる人件費や時間コストである。投資対効果を正しく測るには、こうした隠れた費用まで含めて、AI PoCとは単なる実験ではない事業計画を立てる必要がある。さらに、医療や金融など判断の根拠が問われる分野では、AIの結論を人間が理解できる説明可能性(XAI)の確保が、社内外の信頼を得るための必須条件となる。
あわせて読みたいai poc とはについて、導入方法から活用事例まで詳しく解説します。
画像認識AIの限界と批判的視点:利便性の裏に潜む倫理的リスクと社会的課題
ここまでAIがもたらす輝かしい未来を語ってきたが、その光が強ければ影もまた濃くなる。アルゴリズムは決して中立ではなく、そこに潜むバイアスは社会の分断を助長しかねない。便利さの代償として、私たちの日常が常に監視される社会を許容するのか。本章では、こうした技術礼賛の風潮に冷や水を浴びせ、AIがもたらす倫理的リスクと責任の所在という、不都合な真実に切り込む。
アルゴリズムは中立ではない?AIに潜むバイアスの危険性
「AIは客観的で中立だ」という技術者たちの寝言を、いつまで信じ続けるつもりだろうか。アルゴリズムとは所詮、偏見に満ちた過去のデータを学習し、開発者の無意識な価値観をコードに埋め込まれた代物に過ぎない。例えば、過去の採用実績から「特定の大学出身者」を優遇したり、犯罪統計から「特定の地域住民」を危険人物だとラベリングしたりする。これは単なるバグではない。人間社会に存在する構造的差別を、AIという装置が効率的に増幅・再生産しているだけの話だ。その判断根拠はブラックボックスの闇の中。私たちは、なぜ自分がシステムに排除されたのかを知る術もなく、ただその「客観的な」決定を受け入れるしかない。便利さの代償に、声なき人々が切り捨てられる社会を、本当に望んでいるのか?
便利さの代償か?監視社会を加速させるAI技術の功罪
「安全」という大義名分の下、街中のカメラが私たちの顔をスキャンし、行動をデータ化する。これが2026年の日常だ。便利さと引き換えに、私たちは常に評価され、選別される「透明な檻」に入れられたことに、一体いつ気づくのだろうか。AIは単に不審者を検知するだけではない。購買履歴やSNSと結びつき、個人の思想信条までプロファイリングするのだ。誰が、どのような目的でそのデータを利用するのか。明確なAIガバナンスが不在のまま、私たちのプライバシーは切り売りされていく。無自覚な「同意」の先に待つのは、巨大テック企業や国家に管理されたディストピアに他ならない。
AIが判断を誤った時、その責任は誰が負うのか?
自動運転車が人身事故を起こし、医療AIが致命的な誤診を下した時、一体誰が法廷に立つというのか。開発者は「予見不可能な事態」と逃げ、サービスを導入した企業は「AIの判断に従っただけ」と責任を転嫁するだろう。結局、誰もが「自分ではない」と主張する中で、被害者だけが泣き寝入りする責任の空洞化が起きるだけだ。EUが「AI Act」で規制を試みたところで、判断根拠が不明なブラックボックスを前に、どうやって過失を立証するというのか。技術者たちが掲げる「説明可能性」などというお題目は、訴訟を有利に進めるための言い訳作りに過ぎない。責任の所在という根本的な議論を先送りしたまま進む社会実装は、あまりに無責任である。
まとめ:画像認識AIと共創する未来へ - 私たちが今、考えるべきこと
画像認識AIは、生成AIとの融合によって、単に物体を「見る」技術から、文脈を「理解し、対話する」パートナーへと劇的な進化を遂げました。これはもはや特定分野の専門ツールではなく、マルチモーダルAIとして私たちの仕事や生活に深く関わる、新たな社会インフラの始まりです。この大きな変革の波の中で、私たちはただ技術の恩恵を受けるだけでなく、プライバシーやバイアスといった倫理的課題にどう向き合うのか、主体的に考えることが不可欠だ。あなたのビジネスでは、この進化するAIとどのように共創しますか?そして、どのような未来を築きたいでしょうか?具体的な活用戦略や導入に関するご相談は、ぜひOptiMaxまでお寄せください。