なぜ今、LLMにRAG(検索拡張生成)が必須なのか?
ChatGPTをはじめとする大規模言語モデル(LLM)の回答に、「この情報は本当に正しいのか?」と不安を感じた経験はありませんか。LLMは、学習データが古かったり、もっともらしい嘘(ハルシネーション)を生成したりする致命的な弱点を抱えています。この信頼性の問題を解決し、LLMをビジネスで本格活用するための鍵こそがRAG(検索拡張生成)です。RAGは、最新の社内データやリアルタイム情報といった「根拠」をLLMに与え、信頼性の高い回答を生成させます。もはや単なる検索技術ではなく、企業の競争力を左右する必須の存在なのです。
ハルシネーションと古い知識というLLMの限界
大規模言語モデル(LLM)は非常に強力ですが、ビジネスで利用するには看過できない2つの大きな限界があります。一つは、事実に基づかないもっともらしい嘘を生成してしまう「ハルシネーション」です。これを顧客対応や資料作成に利用すれば、誤った情報提供によって企業の信頼を大きく損なうリスクがあります。もう一つの限界は、学習データが特定の時点のものであり、知識が古いという点です。最新の法規制や市場のトレンド、刻々と変わる社内ルールに対応できないため、古い情報に基づいた誤った意思決定を導きかねません。こうしたLLMとは何かを理解した上で、その限界を克服する仕組みが不可欠なのです。
あわせて読みたい
llm とはについて、導入方法から活用事例まで詳しく解説します。
根拠ある回答を生成し、ビジネスの信頼性を向上
RAGは、LLMの回答に明確な「根拠」を与えることで、ビジネス上の致命的なリスクであるハルシネーションを大幅に低減させます。例えば、顧客からの問い合わせには常に最新の製品マニュアルを、社内の業務報告にはリアルタイムの販売データを参照して回答を生成します。これにより、担当者の経験や知識に依存しない、均質で信頼性の高い情報提供が実現するのです。特に重要なのが、回答の典拠(引用元)を明示できる点です。生成AIが出した答えがどの文書に基づいているかを示すことで、ユーザー自身による事実確認が容易になります。この透明性の確保こそが、AIの回答に対する疑念を払拭し、ビジネスにおける意思決定の質を高める鍵となります。具体的に他社はどう使ってるのかを知ることで、その効果をより実感できるでしょう。
あわせて読みたい
生成 ai 活用 事例について、導入方法から活用事例まで詳しく解説します。
単純な検索を超え、自律的な知識処理基盤へと進化
RAGはもはや、検索した情報をLLMに渡すだけの受動的な仕組みではありません。2026年現在、RAGは企業のあらゆる情報を統合し、自律的に思考・判断する「知識処理基盤」へと進化しました。これは、AIにどの情報をどう与えるかを設計する「コンテキストエンジニアリング」という思想が背景にあります。例えば、自律的に思考するAIエージェントと生成AIの違いとはを組み込んだ「Agentic RAG」は、自ら問いを立てて検索を繰り返すことで、単一検索では得られない深い洞察を導き出します。このように、RAGは企業の知識資産を能動的に活用する「知識ランタイム」としての役割を担い始めているのです。
あわせて読みたい
ai エージェント 生成 ai 違いについて、導入方法から活用事例まで詳しく解説します。
LLMの弱点を克服するRAGの基本的な仕組み
LLMがなぜ根拠のある回答を生成できるのか、その心臓部となるRAGの仕組みを見ていきましょう。このプロセスは、大きく分けて「検索(Retrieve)」と「生成(Generate)」の2ステップで成り立っています。まず、社内文書などの外部データの中から「ベクトル検索」という技術で関連情報を正確に探し出します。次に、その抽出した情報だけを根拠としてLLMに渡し、回答を生成させるのです。このシンプルな仕組みが、LLMの弱点をいかにして克服するのか、その具体的な流れを解説します。
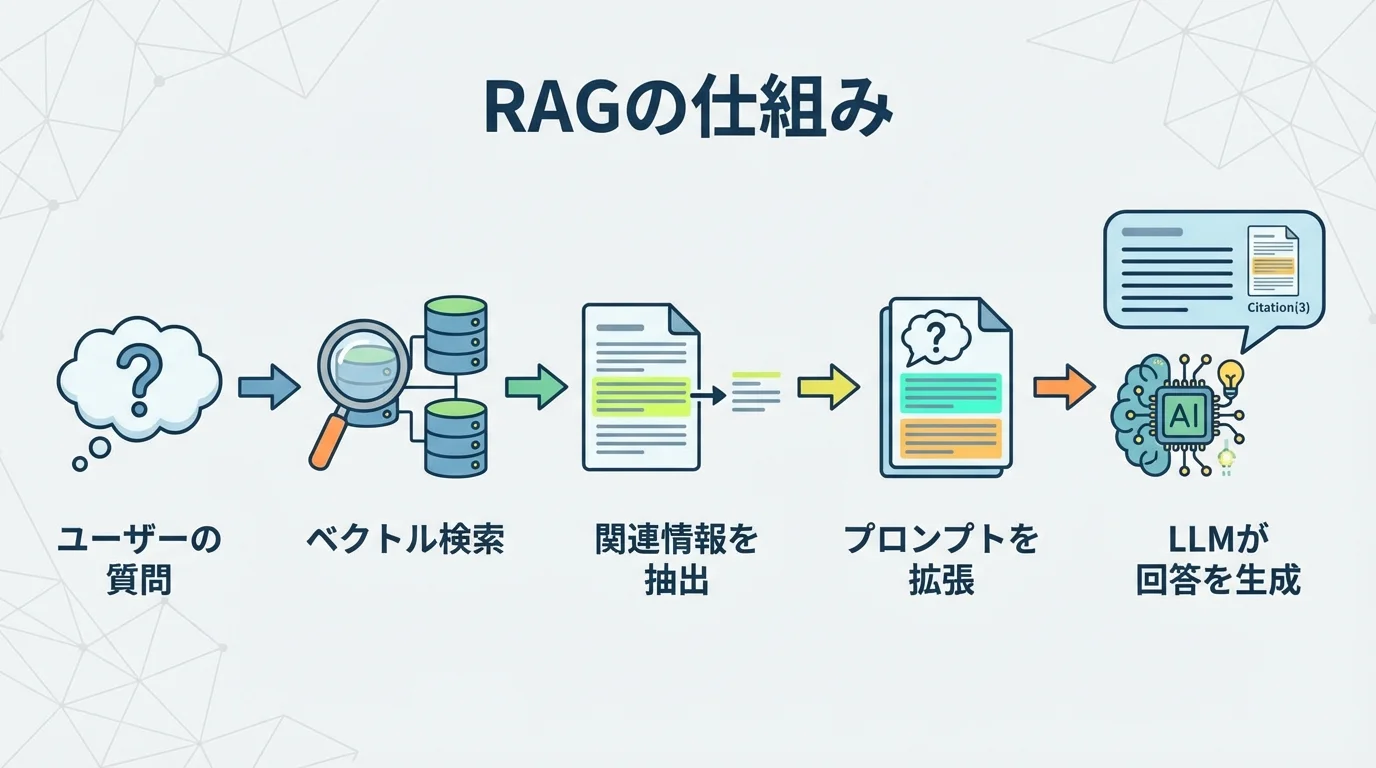
ベクトル検索で外部データから関連情報を抽出
RAGの検索プロセスは、まず社内文書などの外部データをAIが扱える形に変換する「インデックス作成」から始まります。具体的には、マニュアルや議事録といった長文のドキュメントを、意味のある塊(チャンク)に細かく分割します。次に、各チャンクの意味を数値の羅列である「ベクトル」に変換し、専用のベクトルデータベースに格納するのです。ユーザーから質問が来ると、その質問文もベクトル化し、データベース内で意味が最も近いチャンクを瞬時に探し出します。2026年現在では、この手法に加え、製品型番などの固有表現に強いキーワード検索を組み合わせたハイブリッド検索が主流です。さらに、抽出した候補の中から関連性の高いものだけを厳選する「リランカー」という技術で、LLMに渡す情報の精度を最大限に高めています。
抽出した情報を基にLLMが根拠ある回答を生成
ベクトル検索で選び抜かれた情報は、次に回答生成の材料としてLLMに渡されます。このプロセスでは、元の質問と抽出した情報を「この情報だけを根拠に回答してください」という特別な指示(プロンプト)と共にLLMへ渡します。これにより、LLMは学習データ全体からではなく、与えられた限定的な情報源のみを参照するため、事実に基づかないハルシネーションを劇的に抑制できるのです。さらに、ビジネスで不可欠なのが、回答と共に典拠(引用元)を明示する機能です。どの文書を参考にしたかを示すことで、ユーザーは即座に事実確認を行え、回答の信頼性が担保されます。そもそも生成AIとは何かを考える上で、この根拠を示す能力は極めて重要です。
あわせて読みたい
生成AIについて、基礎知識から活用事例・比較・導入方法まで包括的に解説するガイドです。
リアルタイム情報で常に知識をアップデート
LLM本体の知識を更新するには、膨大なコストと時間を要する再学習が必要です。しかしRAGは、この問題を根本から解決します。LLMを再学習するのではなく、参照先の外部データベースを更新するだけで、常に最新情報に基づいた回答を生成できるのです。例えば、新しい社内規定や製品情報が追加された場合、その文書をデータベースに取り込み、インデックスを再作成する「データインジェスト」というプロセスを実行するだけで済みます。この仕組みがあるからこそ、日々変化する法規制や市場動向にも迅速に対応可能であり、参照するデータソースの品質と鮮度を維持することが、回答の信頼性を担保する上で最も重要になります。
2026年の最新動向:Naive RAGからAdvanced RAGへの進化
2026年現在、単に情報を検索してLLMに渡すだけの「Naive RAG(ナイーブ・ラグ)」の時代は終わりを告げました。現代のRAGは、自ら回答精度を高める自己修正能力や、自律的に思考し検索する「Agentic RAG」などを組み込んだ「Advanced RAG(アドバンスト・ラグ)」へと進化しています。これは、AIが受動的な検索ツールから、企業の知識を能動的に処理する「知識ランタイム」へと質的に変化したことを意味するのです。ここでは、その最先端の動向を紐解いていきます。
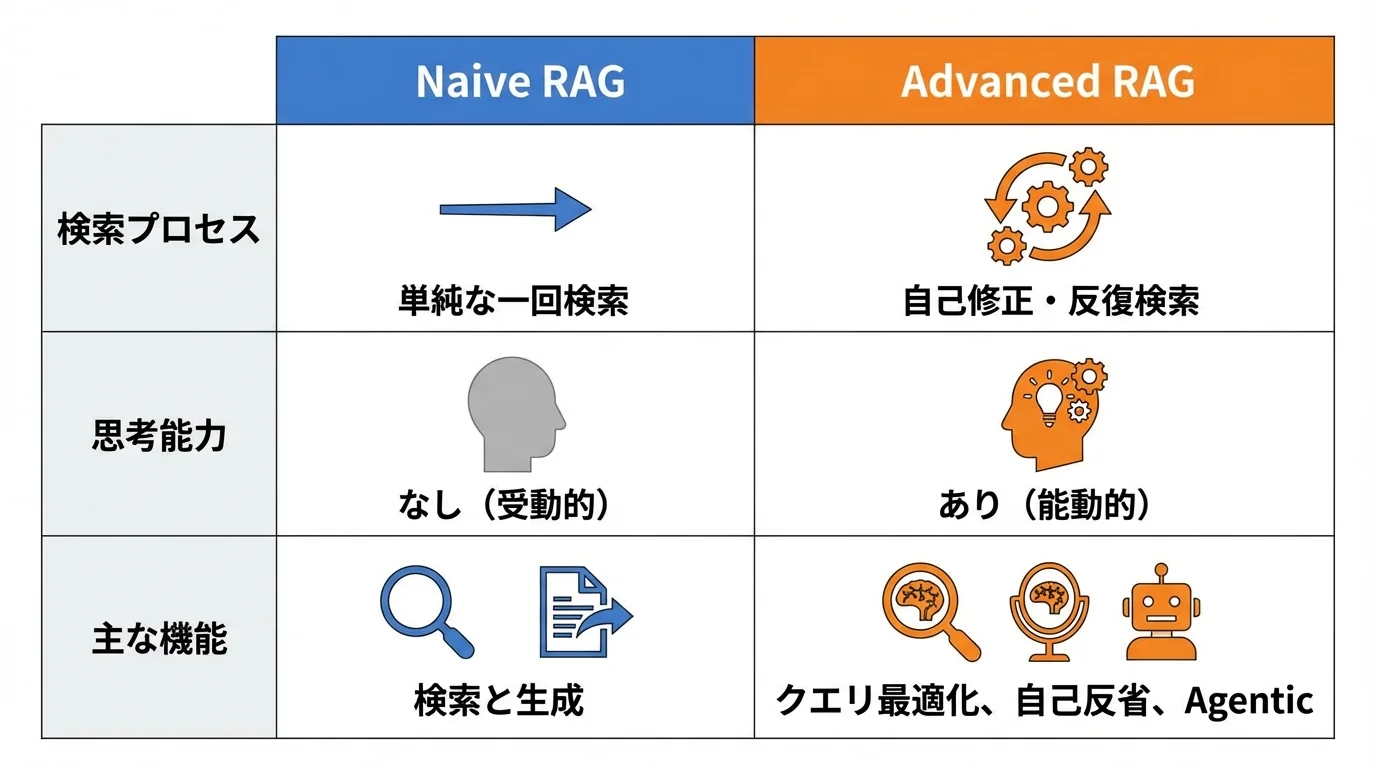
単純な検索から高度な知識処理の時代へ
従来のRAGは、ユーザーの質問に近い情報を探し出す「検索補助」の役割が中心でした。しかし、2026年現在のRAGは、AIが自ら思考し、情報の質を高める「知識処理エンジン」へと根本的に変化しています。
例えば、ユーザーの曖昧な質問を検索に最適な形へ自動で書き換える「クエリ最適化」や、抽出した情報が不十分なら自ら問いを立て直し再検索する「自己修正能力」は、もはや標準的な機能です。さらに、文書間の関係性を読み解く「GraphRAG」のような技術も実用化され、単体の情報だけでなく、データ全体の文脈を捉えた深い洞察が可能になりました。これは、AIエージェントと生成AIの違いとはで解説されるような自律性が検索プロセス自体に組み込まれ、受動的な情報検索の時代が終わりを告げたことを意味します。
あわせて読みたいai エージェント 生成 ai 違いについて、導入方法から活用事例まで詳しく解説します。
回答精度を自ら高める自己修正・反省能力
Advanced RAGを象徴するのが、AIが自ら回答の品質を評価し改善する「自己反省(Self-Reflection)」の能力です。これは、検索した情報が質問の意図と合っているか、生成した回答に矛盾がないかをLLM自身がチェックする仕組みを指します。もし品質が低いと判断すれば、質問の表現を自動で最適化して再検索を実行したり、回答を生成し直したりします。この「評価→修正」のループにより、AIは人間が介在せずとも自律的に回答精度を高めていくのです。単に検索するだけでなく、その結果を吟味し、より良い答えを追求するこの能力は、まさにAIエージェントと生成AIの違いとはで解説される自律的な思考プロセスそのものです。
あわせて読みたいai エージェント 生成 ai 違いについて、導入方法から活用事例まで詳しく解説します。
自律的に思考し検索するAgentic RAGの登場
2026年のRAG進化を象徴するのが「Agentic RAG(エージェンティック・ラグ)」です。これは、AIが単なる検索ツールではなく、自律的な「エージェント」として振る舞うアーキテクチャを指します。ユーザーからの曖昧な指示に対し、「何を」「どのように」調べるべきかをAI自らが計画し、Web検索や社内データベース検索といった複数のツールを使い分けます。この「思考・行動・修正」のループを自律的に繰り返すことで、一度の検索では到底たどり着けない、複合的な課題に対する深い洞察を導き出すのです。この動きは、AIエージェントと生成AIの違いとはで解説されるような、より能動的なAIの役割を体現しています。
あわせて読みたいai エージェント 生成 ai 違いについて、導入方法から活用事例まで詳しく解説します。
自律的に思考し検索を繰り返す「Agentic RAG」の台頭
これまでのRAGが「一度の検索で情報を探す」仕組みだったのに対し、2026年の主流である「Agentic RAG」は、AI自身が自律的なエージェントとして思考し続けます。ユーザーの曖昧な指示に対し、「何を」「どう調べるべきか」を自ら計画。Web検索やデータベース検索といった複数のツールを使い分け、「思考・行動・修正」のループを繰り返すことで、単一検索では決して解けない複雑な課題への答えを導き出すのです。ここでは、その具体的な仕組みと能力を深掘りします。
AIが自律的に問いを立て、最適な検索を実行
Agentic RAGの最大の特徴は、ユーザーからの曖昧な質問をそのまま検索しない点にあります。まずAIが質問の意図を深く分析し、「何を」「どのように」調べるべきかを自ら計画するのです。例えば、「競合A社の最新動向を教えて」という指示に対し、AIは自律的に「最新のプレスリリースは何か?」「直近の決算報告の要点は?」「関連する業界ニュースは?」といった複数のサブクエスチョンに分解します。さらに、それぞれの問いに対し、プレスリリースはWeb検索、決算報告は社内データベースへのSQLクエリ実行といったように、最適なツールを使い分けるのです。この自律的な計画と実行能力は、まさにAIエージェントと生成AIの違いとはで解説される能動的な思考プロセスそのものです。
あわせて読みたいai エージェント 生成 ai 違いについて、導入方法から活用事例まで詳しく解説します。
「思考・行動・修正」のループで回答精度を向上
Agentic RAGの真価は、一度の検索で終わらない自己改善能力にあります。まずAIは、抽出した情報が質問の意図と合致しているか、回答を生成するのに十分かを自ら評価(思考)します。もし情報が不足している、あるいは矛盾があると判断すれば、検索キーワードを自動で最適化して再検索したり、別のデータベースに問い合わせたりする(修正・行動)のです。この「評価→修正」のループを人間が介在せずとも自律的に繰り返すことで、AIは粘り強く最適解を探し続けます。この自律的な改善サイクルは、AIエージェントと生成AIの違いとはで解説されるような、能動的な問題解決能力そのものです。
あわせて読みたいai エージェント 生成 ai 違いについて、導入方法から活用事例まで詳しく解説します。
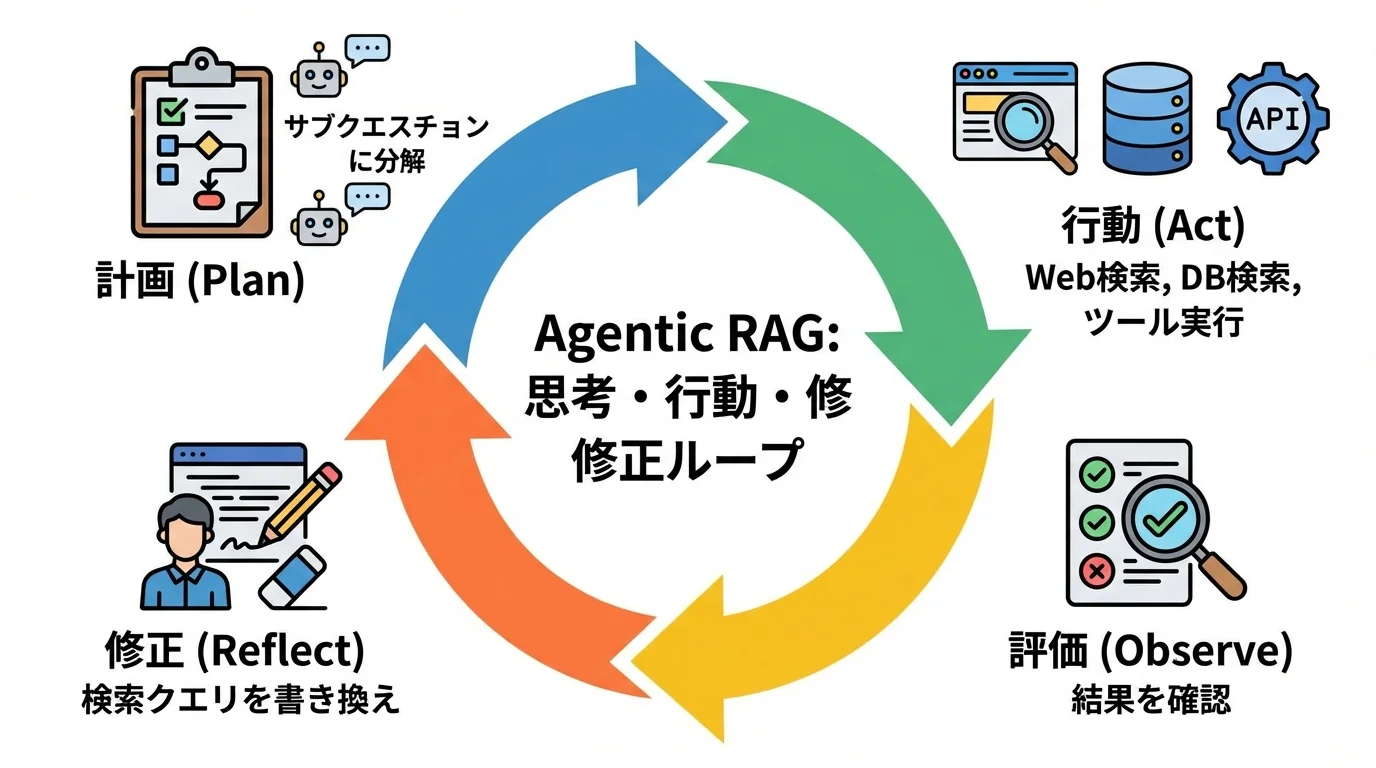
単一検索では解けない複雑な課題を解決に導く
従来のRAGが「この製品のマニュアルはどこ?」という単一の問いに答えるのが得意だったのに対し、Agentic RAGは「競合A社の新製品発表に対し、過去の自社製品Bの販売データと顧客フィードバックを基に、マーケティング戦略の草案を作成して」といった複合的な課題に対応できます。AIはまずこの指示を「競合の製品情報収集」「社内DBから販売データ抽出」「顧客フィードバックの分析」といった複数のサブタスクに自律的に分解。それぞれのタスクに最適なツール(Web検索、SQLクエリ、文書検索)を使い分け、得られた情報を統合して最終的な回答を生成するのです。さらに、GraphRAGのような技術と連携すれば、「Cプロジェクトに関与し、現在D部門にいる技術者は誰か?」といった、文書を横断した関係性の把握も可能になります。これは、もはや検索ではなく、高度な分析と推論の領域です。
データの関係性を読み解く新技術「GraphRAG」の実用化
これまでのRAGが主に用いてきたベクトル検索は、似た文書を見つけるのは得意ですが、文書間の「関係性」までを捉えるのは困難でした。この限界を突破する新技術が、マイクロソフトリサーチが提唱する「GraphRAG」です。これは、文書から人や組織といった要素とそのつながりを抽出し、知識グラフを自動で構築する技術。これにより、データ全体の文脈を構造的に理解し、「AプロジェクトとB技術の両方に関わった人物は誰か」といった、より深い洞察を導き出すのです。
ベクトル検索を超え、データ間の文脈を捉える
従来のベクトル検索は、文書の内容が「似ているかどうか」を判断するのは得意ですが、文書を横断した関係性を捉えることはできませんでした。例えば、「Aプロジェクトに参加した人物」と「B技術に詳しい人物」はそれぞれ見つけられても、「Aプロジェクトに参加し、かつB技術に詳しい人物は誰か」という複合的な問いには答えられません。
GraphRAGは、この課題を知識グラフの構築によって解決します。文書から「人」「組織」「技術」といった要素(エンティティ)とその関係性を自動で抽出し、データ間のつながりを可視化するのです。これにより、個別の文書に埋もれていた関係性が明らかになり、より深い洞察を直接導き出せるようになります。これは単なる検索ではなく、高度なChatGPTデータ分析の活用法にも通じるアプローチだと言えます。
あわせて読みたい
ChatGPT データ分析 活用について、導入方法から活用事例まで詳しく解説します。
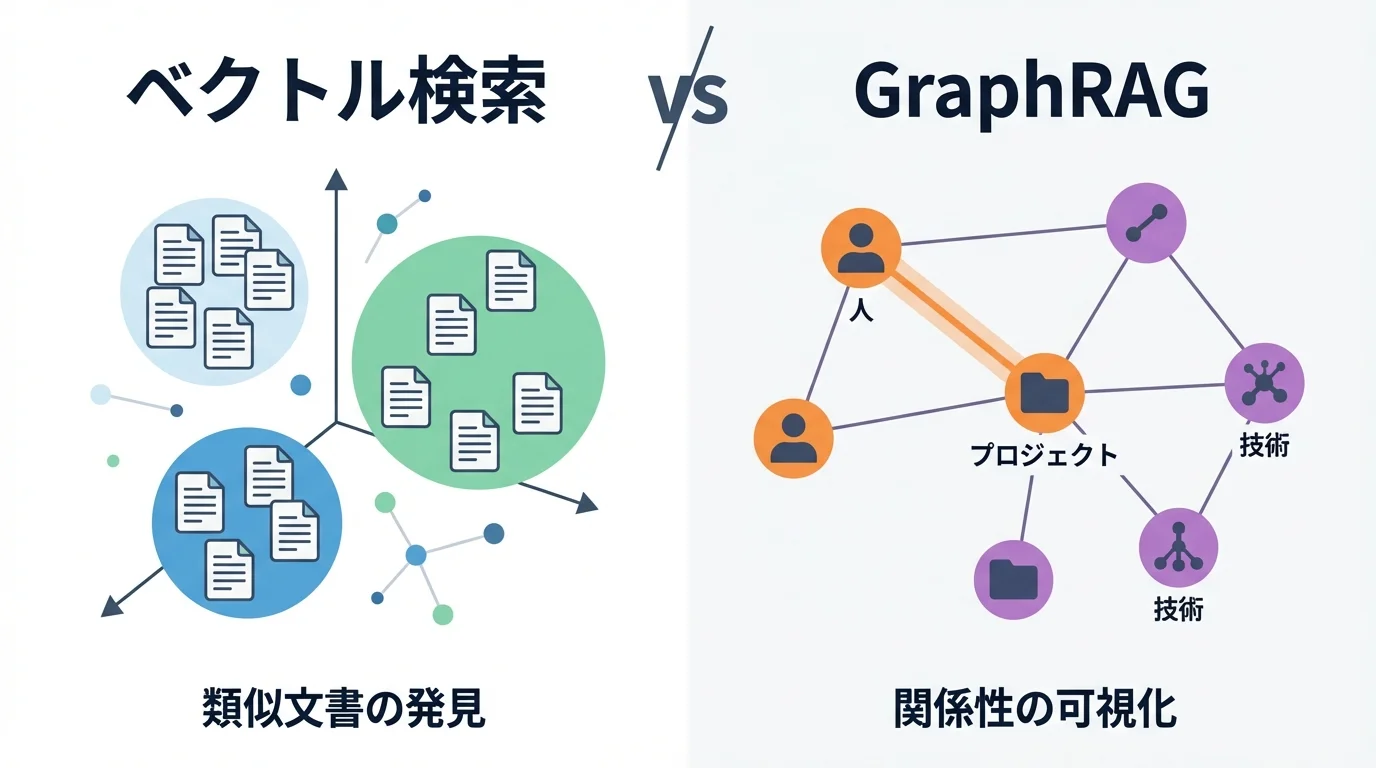
データの全体像を把握し、深い洞察を導き出す
GraphRAGが構築した知識グラフは、いわば企業内データの「相関図」です。これにより、個別の文書を点で見るのではなく、データ全体のつながりを構造的に捉えることが可能になります。例えば、「Aプロジェクトに関与し、かつB技術の専門知識を持つ人物は誰か」といった、複数の情報を横断して関係性をたどる複雑な問いに瞬時に回答できるのです。これは単なる情報検索ではなく、これまで埋もれていたインサイトを掘り起こす「知識のマイニング」と言えます。高度なChatGPTデータ分析の活用法にも通じるこのアプローチは、データ全体の構造を可視化することで、潜在的なリスクや新たなビジネスチャンスといった深い洞察を導き出し、企業の競争力を高める強力な武器となります。
あわせて読みたいChatGPT データ分析 活用について、導入方法から活用事例まで詳しく解説します。
複雑なナレッジを構造化し、企業の資産へ昇華
GraphRAGは、組織内に散在する「暗黙知」を、誰もが活用できる「形式知」へと転換する強力な触媒です。考えてみてください。過去のプロジェクト資料、技術メモ、議事録などに点在する情報は、単体ではただの記録に過ぎません。しかしGraphRAGは、これらの文書から「誰が」「何に」「いつ関わったか」という関係性を抽出し、知識グラフとして構造化します。これにより、熟練技術者の退職と共に失われがちだったノウハウや意思決定の背景が、組織全体の知的資産として恒久的に蓄積されるのです。これは、単なる検索の効率化を超え、技術継承やイノベーション創出の基盤を築くことに他なりません。
【業界別】最新RAG技術を活用した企業の導入事例
ここまで解説してきたAgentic RAGやGraphRAGは、もはや概念上の技術ではありません。金融、製造、顧客サポートといった様々なビジネスの現場で、すでに具体的な成果を生み出し始めています。市場動向を自律的に分析するAIや、複雑な技術文書の関係性を可視化するシステムなど、最先端のRAGがビジネスをどう変革しているのか。具体的な企業の導入事例を詳しく見ていきましょう。
金融業界:Agentic RAGによる市場動向の自律分析
金融業界では、情報の速さと正確さが企業の収益に直結します。刻々と変化する市場データ、各国の経済ニュース、規制当局の発表といった膨大な情報をリアルタイムで分析するため、Agentic RAGが「自律的なAIアナリスト」として活用されています。例えば、「特定の銘柄に影響を与えうる地政学リスク」といった曖昧な指示に対し、AIが自らWeb検索、社内レポート分析、データベース照会といった最適なツールを使い分け、情報を収集・統合します。さらに、単に情報を集めるだけでなく、AIエージェントと生成AIの違いとはで解説されるような自律性で、情報間の因果関係を推論し、投資戦略の草案まで作成するのです。これにより、人間のアナリストは単純な情報収集から解放され、より高度な戦略的意思決定に集中できます。
あわせて読みたいai エージェント 生成 ai 違いについて、導入方法から活用事例まで詳しく解説します。
製造業:GraphRAGで技術文書の相関関係を可視化
製造業では、設計図や仕様書、過去のトラブル報告書といった膨大な技術文書が部門ごとに散在し、ベテラン技術者のノウハウが属人化しやすいという根深い課題を抱えています。GraphRAGは、これらの文書から部品、担当者、プロジェクトといった要素とその「関係性」を抽出し、知識グラフとして可視化します。これにより、「過去のA部品の不具合報告と、その設計変更に関わった技術者」といった、複数の文書を横断しなければ分からない問いに瞬時に回答できるようになるのです。このデータ間の相関を読み解くアプローチは、高度なChatGPTデータ分析の活用法にも通じ、これまで埋もれていた暗黙知を組織全体の知的資産へと昇華させ、迅速なトラブル解決や技術継承を強力に後押しします。
あわせて読みたいChatGPT データ分析 活用について、導入方法から活用事例まで詳しく解説します。
顧客サポート:自己修正RAGで回答精度を自動で向上
顧客サポートの現場では、曖昧な問い合わせや頻繁に更新されるFAQへの対応がオペレーターの大きな負担となっています。この課題を解決するのが、AIが自ら回答の品質を評価・改善する「自己修正RAG」です。この技術は、検索した情報が顧客の質問意図に合わないと判断した場合、質問を検索に適した形に自動で書き換え、再検索を実行します。この「評価→修正」のループを自律的に繰り返すことで、新人オペレーターでもベテラン並みの正確な回答を提示できるようになるのです。まさに、自律的に思考するAIエージェントと生成AIの違いとはで解説される能動的な問題解決プロセスであり、顧客満足度の向上と業務負荷の軽減を両立させます。
あわせて読みたいai エージェント 生成 ai 違いについて、導入方法から活用事例まで詳しく解説します。
RAG導入時の課題と知っておくべき注意点
ここまでAgentic RAGやGraphRAGといった最新技術の華々しい側面を解説してきたが、これらの高度な仕組みは決して魔法の杖ではない。導入後に「こんなはずではなかった」と後悔しないため、この章では敢えてその負の側面にメスを入れる。自律的な検索が招く想定外の運用コストや、回答精度を根本から揺るがす参照データの品質問題など、RAG導入の理想と現実のギャップを埋めるために、避けては通れない課題を正直に解説していこう。
自律検索が招く想定外の運用コスト
Agentic RAGの「自律思考」という言葉に騙されてはならない。AIが一度「思考」し、検索を「修正」するたびに、裏ではLLMのAPIが呼び出され、確実にコストが発生するのだ。簡単な質問のつもりが、AIの自己修正ループによって裏で何十回も検索と推論を繰り返し、月末に届く請求書を見て愕然とするのが典型的な失敗パターンである。この想定外のAPIコール数の爆発は、小規模なPoC(概念実証)段階では決して見えてこない。さらに、問題発生時に「AIがなぜその判断をしたのか」を追跡する監視コストは、単純なRAGの比ではない。ほとんどの社内FAQ検索レベルの課題に大げさな自律エージェントを導入するのは、近所の買い物にF1マシンを使うようなものであり、費用対効果が全く見合わないことを肝に銘じるべきだ。
高度化するシステムの複雑性と専門人材の不足
Agentic RAGやGraphRAGといった言葉の響きに惑わされてはいけない。これらはもはや単一の技術ではなく、クエリ最適化、ハイブリッド検索、リランカー、自己修正ループといった無数の部品を組み合わせる「システム開発」そのものである。問題は、この複雑なシステム全体のアーキテクチャを設計し、運用できる専門人材が市場にほぼ存在しないという厳しい現実だ。結果、流行りのライブラリを導入しただけで精度が出ずに「PoC(概念実証)死」するプロジェクトが後を絶たない。ほとんどの社内文書検索レベルの課題であれば、高度なRAGを導入するより、堅実な全文検索エンジンを改善する方がよほど費用対効果に優れることを知っておくべきだ。
回答精度を左右する参照データの品質問題
どんなに高性能なエンジンを導入しようと、参照させるデータがゴミなら出てくる答えもゴミだ。これはGarbage In, Garbage outという情報処理の鉄則に他ならない。更新されず放置された古い社内規定、部署ごとにフォーマットがバラバラな報告書、文字化けしたスキャンPDFといった「デジタルゴミ」をAIに放り込み、「期待した精度が出ない」と嘆くのが典型的な失敗パターンである。AIは情報の正誤を判断しない。矛盾した情報源があれば平気で矛盾した回答を生成し、結果として誰も使わないシステムがまた一つ増えるだけだ。RAG導入の成否は、技術選定ではなく、地味で泥臭いデータガバナンスを構築できるかにかかっている。
まとめ
本記事では、LLMの弱点を克服し、その可能性を最大限に引き出すRAGの重要性と最新動向を解説しました。RAGはもはや、単に外部情報を参照するだけの技術ではありません。自律的に思考と検索を繰り返す「Agentic RAG」や、データ間の複雑な関係性を読み解く「GraphRAG」の登場により、より高度な業務自動化や高精度な意思決定支援が可能になっています。
この記事で紹介した事例を参考に、あなたのビジネスでRAGをどう活用できるか具体的に検討してみましょう。まずは、社内ドキュメント検索や顧客対応の自動化など、身近な課題解決からPoC(概念実証)を始めるのが成功への近道です。
もし、自社に最適なRAGの構築や導入プロセスの策定でお困りでしたら、専門知識を持つ弊社OptiMaxまでお気軽にご相談ください。