RAG(検索拡張生成)とは?LLMの精度を飛躍させる仕組みを解説
大規模言語モデル(LLM)が生成する情報の正確性に課題を感じていませんか?その解決策として注目されているのがRAG(検索拡張生成)です。RAGは、外部の最新データや社内文書を参照することで、LLMの弱点であるハルシネーションを防ぎ、回答の信頼性を飛躍的に高めます。本セクションでは、このRAGの基本原理に加え、2026年現在ではAIエージェントを支える中核技術へと進化した最新動向までを解説します。
検索拡張生成(RAG)の基本的な仕組みとは
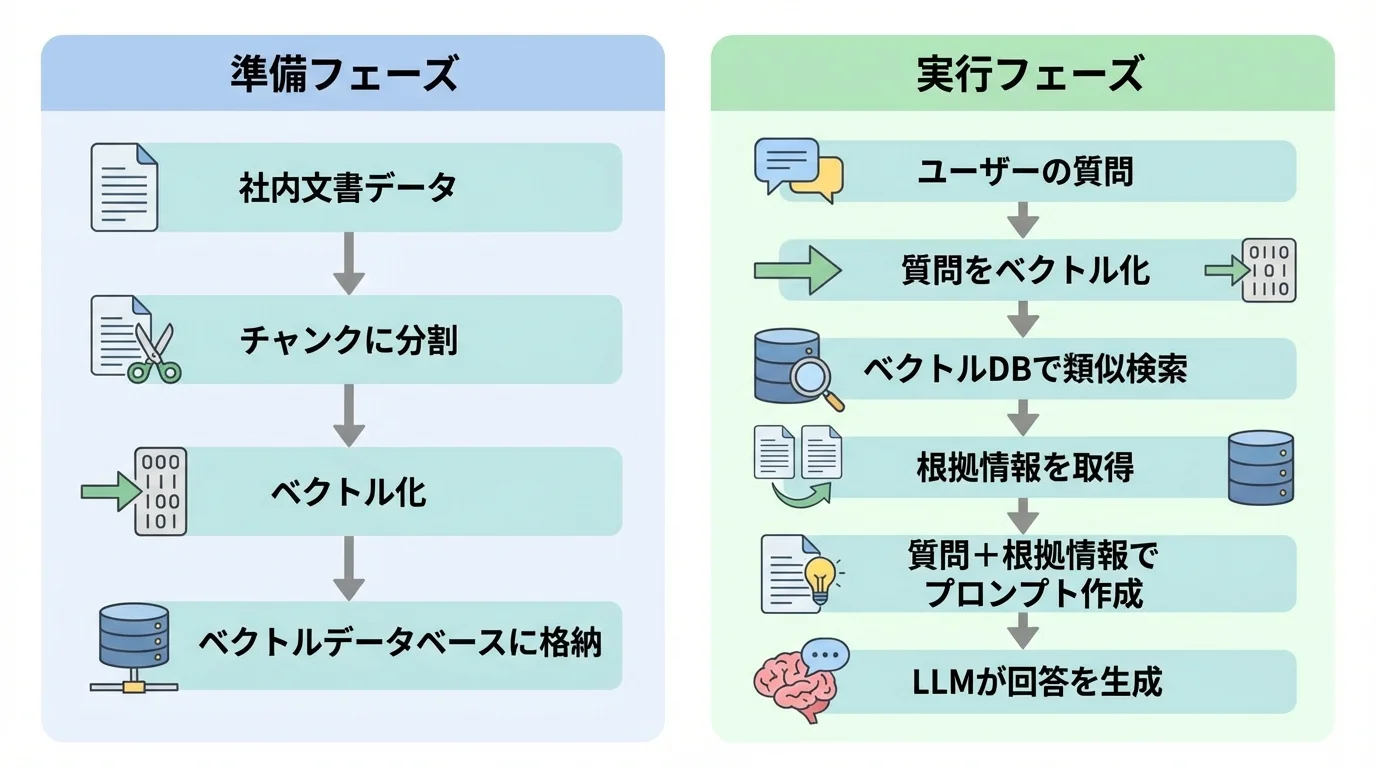
検索拡張生成(RAG)の仕組みは、大きく「準備」と「実行」の2つのフェーズに分かれています。まず準備フェーズでは、社内文書などのデータをLLMが処理しやすい小さな塊(チャンク)に分割し、それぞれの意味を数値の配列(ベクトル)に変換。このデータは、高速検索が可能なベクトルデータベースに保管されます。
次に実行フェーズでは、ユーザーからの質問も同様にベクトル化し、データベース内で意味的に最も近い情報を高速で検索します。そして、見つけ出した根拠情報(コンテキスト)と元の質問をLLMに渡し、正確な回答を生成させるのです。この一連のプロセスを正確に設計することが、プロジェクトがなぜ失敗するかを左右する鍵となります。
あわせて読みたい
物流 AI 導入 手順について、導入方法から活用事例まで詳しく解説します。
LLMのハルシネーションを防ぎ精度を高める役割
大規模言語モデル(LLM)が抱える最大の課題は、事実に基づかない情報を生成するハルシネーションです。RAGは、この問題を解決する上で中心的な役割を担います。LLMに回答を生成させる前に、社内文書やデータベースといった信頼できる外部情報源から関連データを検索し、根拠として提供します。これにより、LLMが不確かな内部知識だけで回答することを防ぎ、事実に基づいた正確な応答を促します。
2026年現在では、検索結果の品質を自己評価し再検索を行う「Self-RAG」や「Corrective RAG (CRAG)」といった高度な手法も登場しており、ハルシネーションをより能動的に抑制します。しかし、参照するデータ自体の品質が低いと誤った回答の原因となり、プロジェクトがなぜ失敗するかの要因にもなるため注意が必要です。
あわせて読みたい物流 AI 導入 手順について、導入方法から活用事例まで詳しく解説します。
2026年最新:AIエージェントを支える中核技術
RAGはもはや単なる検索技術ではありません。2026年現在、RAGは自律的に思考しタスクを実行するAIエージェントを支える中核技術へと進化を遂げています。従来のRAGが一方通行の処理だったのに対し、「Agentic RAG」はAIが自ら計画を立て、複数の情報源を検証・自己修正しながら最適な答えを導き出します。この自律性は、これまでなぜ失敗すると言われていた複雑なAIプロジェクトの成功率を高める鍵となります。さらに、検索品質を自己評価するSelf-RAGや、データ間の関係性を読み解くGraphRAGといった高度な手法も一般化し、LLMに与える情報を最適化する「コンテキストエンジニアリング」という概念が主流になりつつあります。
あわせて読みたい物流 AI 導入 手順について、導入方法から活用事例まで詳しく解説します。
RAG構築を始める前の準備|必要なツールとデータソースの選定
RAGの仕組みを理解したら、次はいよいよ構築の第一歩です。しかし、ツールの選択肢が増えた2026年現在、適切な準備なくして成功はありません。本セクションでは、目的の明確化から、LangChainとLlamaIndexの使い分けといったフレームワーク選定、そして回答精度の根幹をなすデータソースの準備まで、実践的な手順を解説します。
RAG構築の目的と解決したい課題の明確化
RAG構築を成功させる最初の、そして最も重要なステップは、技術選定の前に「何のために作るのか」を明確にすることです。目的が曖昧なままプロジェクトを進めることは、なぜ失敗するかの典型的なパターンです。まずは「社内問い合わせの対応工数を30%削減する」「新人でもベテラン並みの提案資料を迅速に探せるようにする」といった、具体的な業務目標を設定しましょう。
あわせて読みたい物流 AI 導入 手順について、導入方法から活用事例まで詳しく解説します。
解決したい課題が「情報がサイロ化している」「専門用語が多く検索しづらい」など明確になれば、取るべきアプローチも変わります。例えば、キーワード検索とベクトル検索を組み合わせるハイブリッド検索を導入すべきか、あるいは複数の情報源を自律的に横断検索するAgentic RAGが必要か、といった技術的な判断基準が明確になるのです。
必須フレームワークとベクトルデータベースの選定
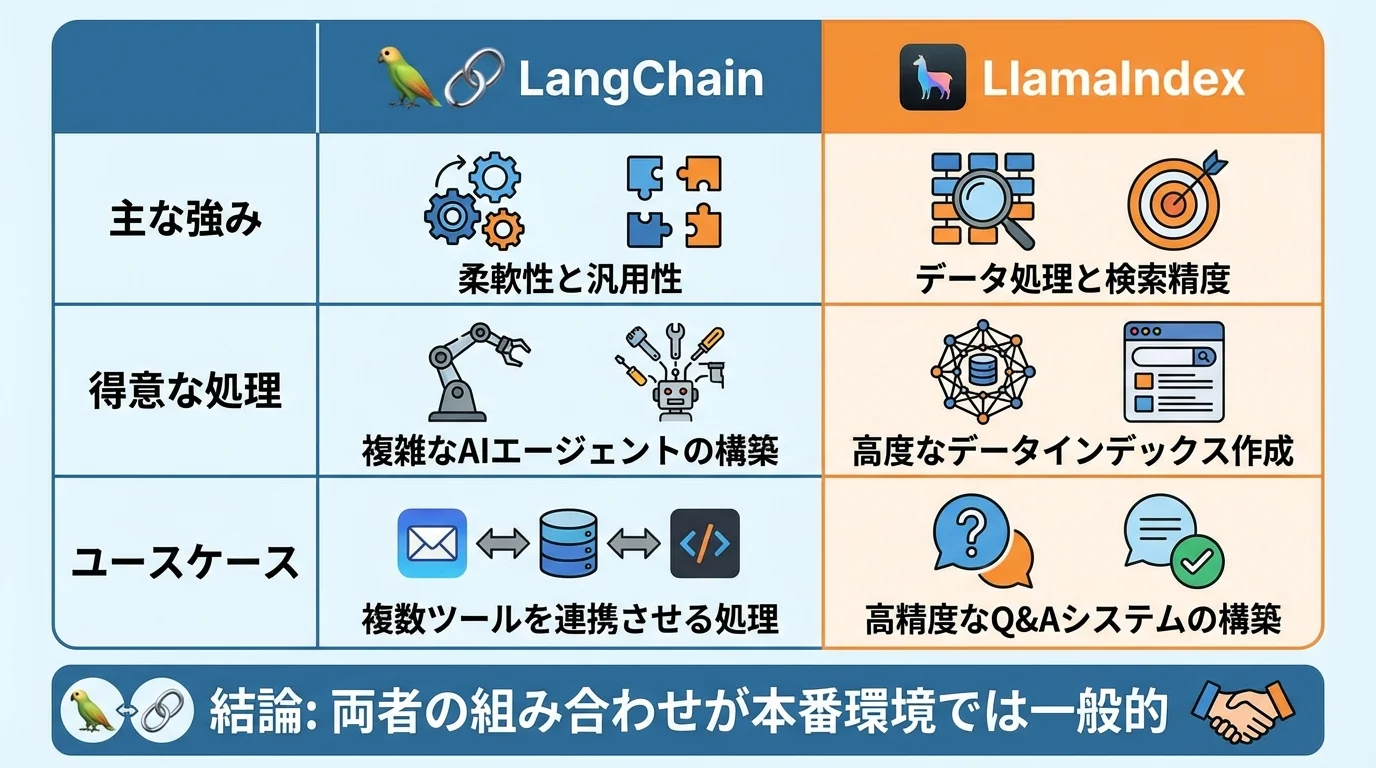
RAGシステムの心臓部となるのが、開発フレームワークとベクトルデータベースです。2026年現在、フレームワークはLangChainとLlamaIndexが主要な選択肢となっています。LangChainは複雑な処理フローを組むオーケストレーションに優れ、LlamaIndexはデータ取り込みとインデックス作成に強みを持つため、両者を組み合わせるハイブリッドな構成が本番環境では推奨されています。
ベクトルデータベースの選定では、単なる類似性検索だけでなく、キーワード検索も可能なハイブリッド検索機能が重要です。これにより、専門用語や固有名詞の検索精度が格段に向上します。ツール選定はプロジェクトの成否を分けるため、安易に決めるとプロジェクトがなぜ失敗するのか、その一因になりかねません。自社のデータ特性や将来的な拡張性を見据え、最適な組み合わせを選びましょう。
あわせて読みたい物流 AI 導入 手順について、導入方法から活用事例まで詳しく解説します。
回答の質を左右するデータソースの種類と準備
RAGシステムの回答精度は、参照するデータソースの質に完全に依存します。「ゴミを入れればゴミが出る」という原則は、RAG構築において最も重要な心構えです。PDFや社内文書といったテキストデータはもちろん、2026年現在では画像や表を含むマルチモーダルデータの活用も始まっています。さらに、データ間の関係性を構造化したナレッジグラフを用意することで、より複雑な問いにも対応可能です。プロジェクトが「なぜ失敗する」かの最大の要因は、不正確・古い情報の除去といった地道な前処理の軽視にあります。データ品質の管理こそが、高精度なRAGを実現する唯一の道筋です。
あわせて読みたい物流 AI 導入 手順について、導入方法から活用事例まで詳しく解説します。
初心者でもわかるRAG構築の基本5ステップ
RAGの仕組みと準備が整ったら、いよいよ構築の実践です。ここでは、データの取り込みからLLMが回答を生成するまでの一連の流れを、初心者にもわかりやすく5つのステップで解説します。2026年現在では、文脈を考慮してデータを分割するセマンティックチャンキングといった手法が重要です。各工程の役割を理解し、精度の高いRAGシステムを構築しましょう。
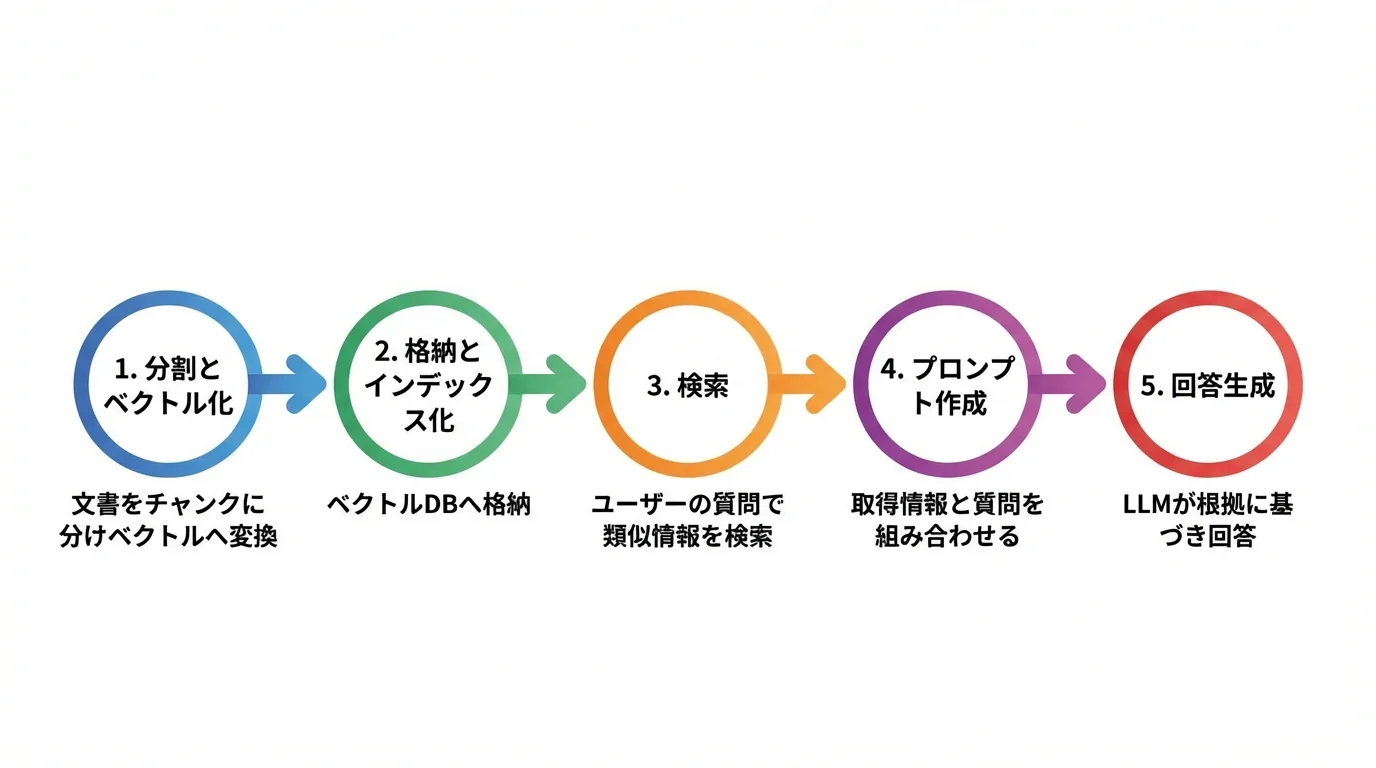
ステップ1:データソースの分割とベクトル化
RAG構築の最初のステップは、LLMが参照する知識の源泉となるデータソースを準備することです。まず、LangChainなどのフレームワークが提供するDocument Loader機能を使い、社内ドキュメントやWebページといった様々な形式のデータをプログラムに読み込みます。次に、読み込んだ長文データを意味のあるかたまり(チャンク)に分割します。2026年現在では、単に文字数で区切るのではなく、文脈を考慮して分割する「セマンティックチャンキング」が検索精度を高める鍵となります。
分割した各チャンクは、OpenAIのtext-embedding-3-smallといった埋め込みモデルを使って、意味的な特徴を持つ数値の配列(ベクトル)に変換します。このベクトル化されたデータを高速検索が可能なベクトルデータベースに格納し、インデックスを作成すれば準備は完了です。このデータ準備の質が、RAG全体の性能を左右するため、プロジェクトがなぜ失敗するのかを避ける上で最も重要な工程と言えます。
物流 AI 導入 手順について、導入方法から活用事例まで詳しく解説します。
ステップ2:ベクトルDBで関連情報を高速検索
ステップ1で準備したベクトルデータベースから、ユーザーの質問に最も関連性の高い情報を瞬時に引き出します。この検索プロセスの精度が、RAGシステム全体の性能を決定づけるため、極めて重要な工程です。
まず、ユーザーが入力した質問(クエリ)を、ステップ1と同じ埋め込みモデルを使ってベクトルに変換します。次に、そのクエリベクトルとデータベース内の全データベクトルを比較し、類似度が高い情報を複数取得します。2026年現在では、意味の近さで探すベクトル検索とキーワードで探す全文検索を組み合わせたハイブリッド検索が標準的です。
さらに、取得した情報群をより高性能なモデルで再評価し、質問との関連性が最も高い順に並べ替える再ランク付け(Re-ranking)を実行します。この検索コンポーネントの最適化を怠ると、プロジェクトがなぜ失敗するかの大きな原因となります。こうして厳選された情報が、次のステップでLLMに渡され、回答の質を支えるのです。
あわせて読みたい物流 AI 導入 手順について、導入方法から活用事例まで詳しく解説します。
ステップ3:取得情報を基にLLMで回答を生成
ステップ2で検索した関連情報を基に、いよいよLLMが最終的な回答を生成します。このステップの鍵は、取得した情報をいかに効果的にLLMに伝えるか、つまりプロンプトの設計にあります。
まず、検索で得られた複数の情報(チャンク)とユーザーの質問を、あらかじめ用意したプロンプトテンプレートに組み込みます。例えば、「以下の情報を参考に、次の質問に答えてください。情報: {取得した情報}, 質問: {ユーザーの質問}」という具体的な指示文を作成します。この指示の質が低いと、RAGプロジェクトがなぜ失敗するかという典型的な原因になり得ます。
あわせて読みたい物流 AI 導入 手順について、導入方法から活用事例まで詳しく解説します。
次に、この完成したプロンプトをLLMのAPIに送信して回答を生成させます。2026年現在では、取得した情報の関連度を再度評価し並べ替える「Re-ranking」という一手間を加えることで、回答精度をさらに高めるのが一般的です。LangChainのLCELなどを使えば、この一連の処理を柔軟に構築できます。
【2026年最新】Agentic RAGとは?自律的に思考する次世代技術
これまでの手順で基本的なRAGは構築できますが、2026年のトレンドはさらにその先を行きます。それが、AIが自ら思考し行動するAgentic RAG(エージェント型RAG)です。従来のRAGが一方向の処理だったのに対し、タスクを計画し自己修正しながら最適な答えを探求する、まさに自律的に思考する仕組みです。AIエージェント開発を加速させる、この次世代技術の原理を解説します。
従来のRAGを超える自律的思考の仕組み
従来のRAGが「質問→検索→回答」という一方向の処理だったのに対し、Agentic RAGはAI自身が思考する点が革新的です。具体的には、LLMがまずタスクを計画し、複雑な問いを複数のサブクエリに分解します。そして、得られた検索結果が不十分だと自ら判断した場合、検索クエリを修正して再検索を実行します。この「自己修正ループ」こそが、自律的思考の核となる仕組みです。さらに、LangGraphのようなフレームワークを活用することで、Web検索やデータベース検索など複数のツールを動的に使い分けるマルチステップ処理が可能となり、より高度な問題解決を実現します。
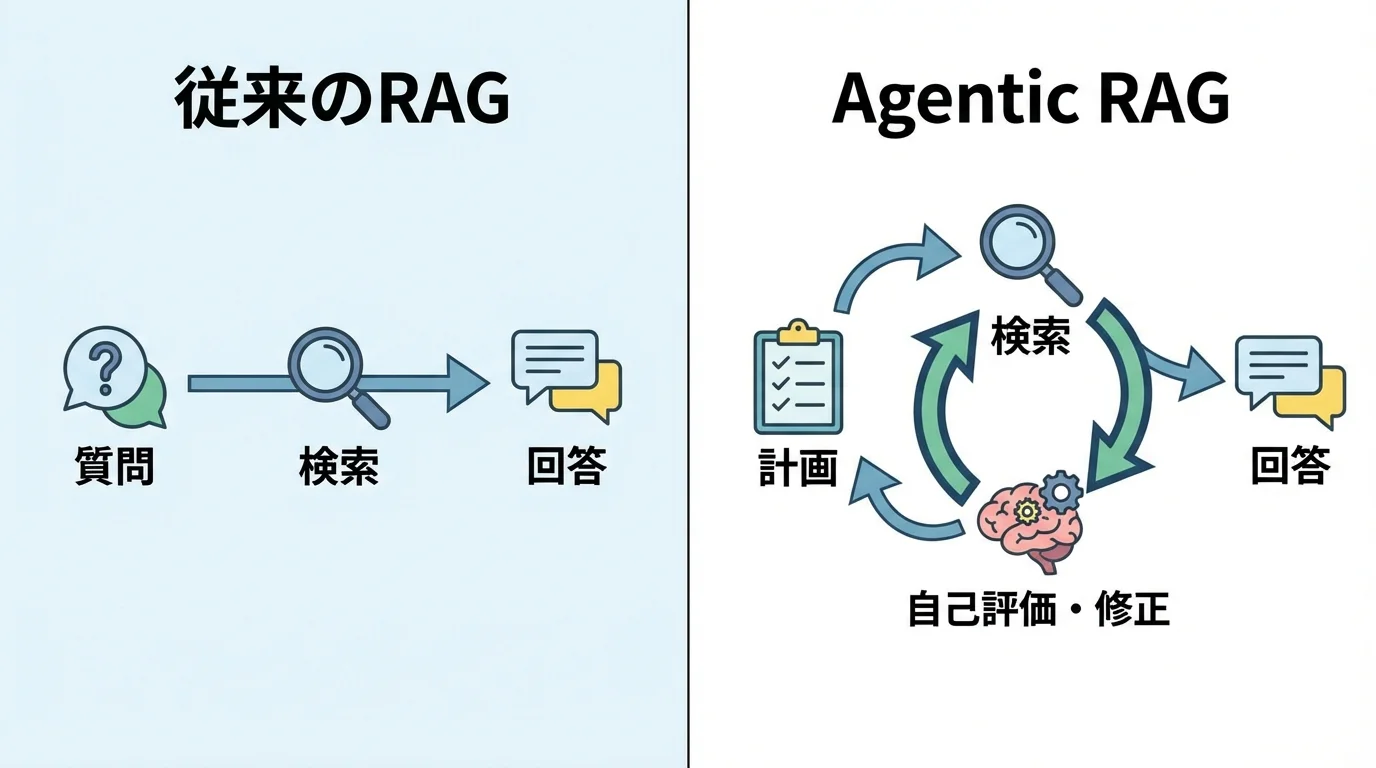
計画・検索・自己修正を繰り返す動作原理
Agentic RAGの核心は、人間のように試行錯誤する「計画・検索・自己修正」のループにあります。まずAIエージェントは、与えられた複雑なタスクを複数のサブタスクに分解し、どのツール(例: 社内DB検索、Web検索)を使うか計画します。次に計画に基づき情報を検索・実行しますが、ここで得た情報が不十分だと判断すると、自己修正のフェーズに入ります。検索クエリを改善したり、別のツールを試したりと、自らプロセスを見直して再度検索を実行するのです。この自律的なループ処理はLangGraphなどのフレームワークで実現され、従来のシステムがなぜ失敗するのか、その原因を自ら分析し、より精度の高い回答を導き出します。
物流 AI 導入 手順について、導入方法から活用事例まで詳しく解説します。
AIエージェント開発を加速させる新アプローチ
Agentic RAGは、AIエージェント開発のあり方を根本から変えています。2026年現在、エージェントフレームワークの進化が著しく、RAGとの統合が標準的なアプローチとなりました。例えばLangGraphやCrewAIといったツールを活用することで、自己修正しながら複数の情報源を使い分ける複雑なワークフローを効率的に構築できます。これにより、これまでなぜ失敗するのかが課題だった自律型エージェントの開発が加速し、市場分析や競合調査といった高度なタスクを担うAIの迅速なプロトタイピングが可能になっています。
物流 AI 導入 手順について、導入方法から活用事例まで詳しく解説します。
RAG構築で陥りがちな失敗例と成功のための3つの注意点
RAGの構築手順を学んでも、多くのプロジェクトが「期待外れ」に終わるのが現実です。本セクションでは、そんな失敗プロジェクトに共通する典型的な落とし穴を正直に解説します。データ品質の軽視や検索コンポーネントの最適化不足など、あなたが同じ轍を踏まないための、3つの重要な注意点を具体的に見ていきましょう。
データ品質の軽視が招く致命的な精度低下
RAG構築プロジェクトが頓挫する最大の原因、それは「優れたLLMを使えば元データの汚さは何とかなる」という致命的な勘違いです。はっきり言って、RAGの回答品質は参照させるデータ品質で9割決まります。2026年現在でも「ゴミを入れればゴミが出る」という原則は変わりません。更新されていない古い社内規定や、議論が発散しただけの議事録を無加工で投入すれば、AIはそれを「正解」として堂々と回答します。成功の鍵は、ベクトル化する前の地道なクレンジングと前処理です。この泥臭い作業を軽視し、最新のフレームワーク導入ばかりに目を奪われたプロジェクトは、例外なく「使えないAI」を量産する運命にあります。
検索コンポーネントの最適化不足による失敗
RAGの失敗原因をLLMのせいにするのは典型的な責任転嫁です。はっきり言って、プロジェクトの失敗の9割は、この検索コンポーネントの作り込みの甘さが原因です。特に、単純なベクトル検索だけで「検索機能は実装した」と満足しているケースは話になりません。専門用語や製品型番がヒットせず、無関係な情報ばかりが返ってくるのは当然の結果と言えるでしょう。2026年現在、キーワード検索を組み合わせたハイブリッド検索の実装はもはや最低条件です。
さらに致命的なのは、検索で取得した情報を無批判にLLMへ渡してしまう設計です。取得した文書群の中から、よりユーザーの意図に近いものを再評価する再ランク付け(Re-ranking)の工程を省略するのは怠慢としか言えません。この一手間を惜しむことで、LLMはノイズの多い情報を基に回答を生成する羽目になり、結果として精度が著しく低下するのです。
Agentic RAGの自律性を過信する設計ミス
「AIが自律的に思考する」というAgentic RAGの甘い言葉に騙されていませんか。この「自律性」を過信し、エージェントに全てを丸投げする設計は、プロジェクトが炎上する典型的なパターンです。曖昧な指示を与えた結果、エージェントが高コストなAPIを無駄に呼び続けたり、見当違いのサブクエリを延々と実行して無限ループに陥るケースは後を絶ちません。
はっきり言って、エージェントは魔法の杖ではなく、あくまでツールです。失敗の根本原因は、明確な制約とガードレールの欠如にあります。LangGraphのようなフレームワークで思考プロセスを厳密に定義し、利用可能なツールや実行ステップ数に上限を設けるといった人間による統制が不可欠。自律性を活かすには、まずその行動範囲を縛る設計が必須だと肝に銘じるべきです。
まとめ:RAG構築を成功させ、LLMの活用を次のレベルへ
本記事では、LLMの可能性を最大限に引き出すRAG構築の基本から、具体的な手順、成功の秘訣までを網羅的に解説しました。この記事を最後まで読んだあなたは、ハルシネーションを抑制し、信頼性の高いAIを構築するための知識とスキルを身につけたはずです。
成功の鍵は、データソースの選定から始まる準備と、「データ準備→チャンキング→エンベディング→インデックス作成→検索・生成」という基本5ステップを着実に実行することにあります。また、Agentic RAGのような先進技術も視野に入れつつ、構築後の評価と改善を継続することが、RAGを真のビジネス資産に変えるために不可欠です。
さあ、まずは自社のドキュメントを使って、小さなRAGの構築に挑戦してみましょう。より専門的な知見や、ビジネス要件に合わせた高度なRAG構築をご検討の場合は、ぜひ私たちOptiMaxにご相談ください。