AI学習禁止とは?クリエイターの権利を守る新たな意思表示
生成AIが私たちの創造性を日々拡張する一方で、あなたの作品が知らないうちに学習データとして利用されているとしたらどうでしょうか。この「無断学習」のリスクに対し、クリエイターが自らの権利を守るために行う具体的なアクション、それが「AI学習禁止」という新たな意思表示です。robots.txtによる制御から、専門知識不要のワンクリック遮断機能まで登場した今、この動きは世界的な潮流となりつつあります。なぜ今この意思表示が重要なのか、その背景にある著作権問題と世界の動向を紐解いていきましょう。
クリエイターの新常識、AI学習禁止という意思表示とは?
生成AI時代において、作品をウェブに公開することは、意図せず学習データを提供することと同義になりつつあります。この状況に対し、クリエイターが自らの創作物を守るための「AI学習禁止」という意思表示が新たな常識となっています。具体的には、サイトにrobots.txtを設定してAIクローラーをブロックする方法や、レンタルサーバーが提供するワンクリック遮断機能の利用が挙げられます。さらに、イラストレーターなどはAIの学習を妨害する「Glaze」や「Nightshade」といったツールを導入し、AI学習禁止の切り札かとも言える能動的な防御策を講じています。こうした対策は、EUのAI法でオプトアウトの尊重が求められるなど法的な意味も帯び始めており、単なる自衛策に留まらない、自身の創作物の価値を主張する重要なアクションなのです。
生成AIの進化が生む「無断学習」リスクと著作権問題
生成AIの進化がもたらす利便性の裏側で、クリエイターの作品が意図せず学習される「無断学習」は、深刻な著作権問題へと発展しています。日本の著作権法第30条の4では、AI開発のための学習が原則として許容される一方、「著作権者の利益を不当に害する場合」の解釈が大きな争点となっています。さらに、高品質な学習データが枯渇する「AIの2026年問題」は、許諾を得ていないコンテンツの不正利用リスクを一層高めると専門家は指摘します。こうした中、学習データの透明性確保やオプトアウトの尊重を求めるEUのAI法が国際的な潮流となりつつあり、robots.txtでの意思表示に加え、AI学習禁止の切り札かとも言える能動的な防御技術も登場。法と技術の両面から、公正なルール形成が急がれています。
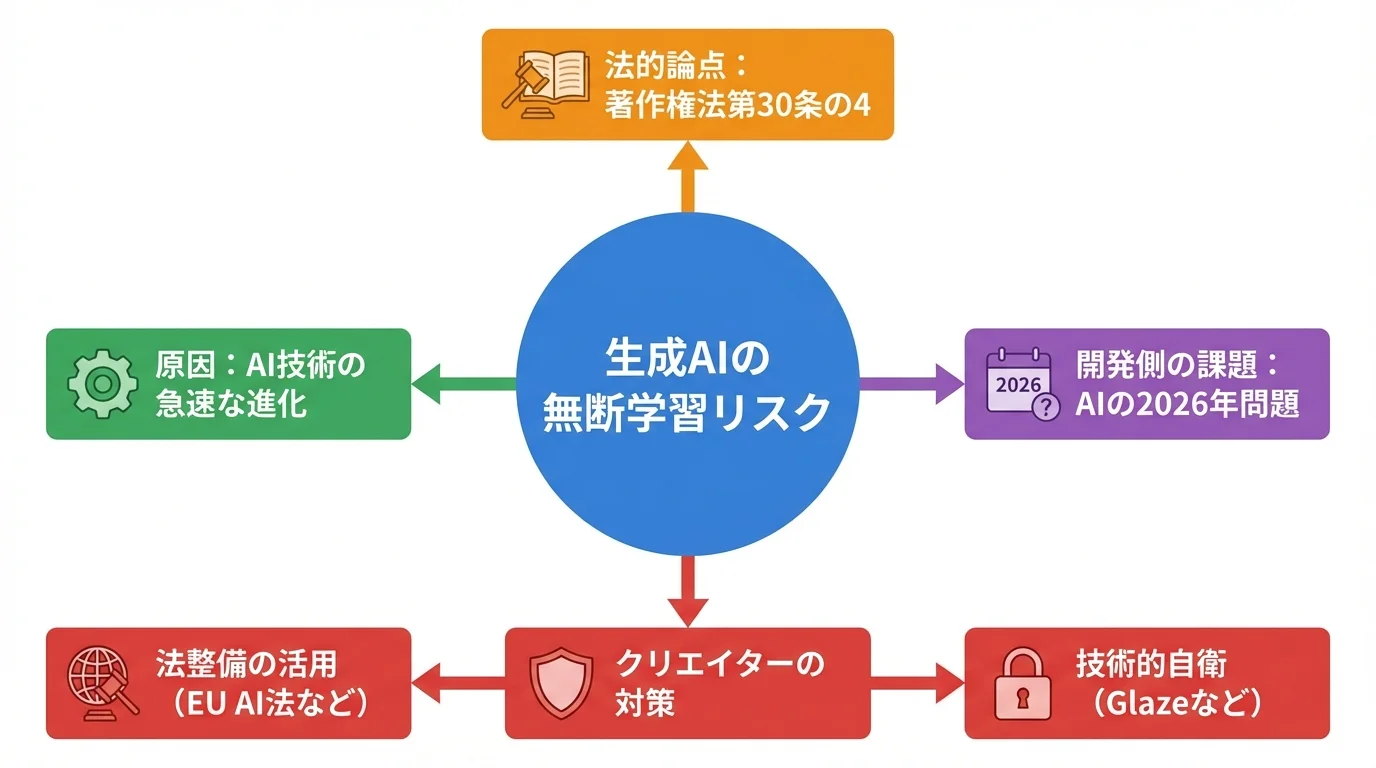
世界標準へ、作品を守る「学習させない」という新たな選択肢
「学習させない」という意思表示は、もはや個人の防衛策にとどまりません。世界的なルールと技術が、クリエイターの選択を後押しする新たな潮流を生み出しています。その象徴が、2026年に全面施行される「EU AI法」です。この法律は、AI開発者に対し、ウェブサイトに示された学習拒否の意思を尊重するよう義務付けており、クリエイターの権利保護が国際的なスタンダードとなりつつあることを示しています。同時に、サーバー側でAIクローラーを一括遮断する新機能や、画像自体に特殊な加工を施すAI学習禁止の切り札かと目されるツールも登場。高品質なデータが枯渇する「AIの2026年問題」が目前に迫る中、こうした法と技術の両輪が、公正な創作エコシステムを築くための新たな選択肢を提示しているのです。
AI学習禁止をめぐる現状と「AIの2026年問題」という新たな課題
クリエイターによる「AI学習禁止」の意思表示は、世界的なルール作りへと急速に発展しています。2026年の全面施行が迫るEUのAI法が著作権保護の新たな基準を示す一方、ワンクリックでAIクローラーを遮断する機能も登場し、自衛手段はより身近なものになりました。しかしその裏側では、高品質な学習データが枯渇する「AIの2026年問題」という、AI開発そのものを揺るがしかねない新たな課題が浮上しています。ここでは、世界の最新動向と、権利保護と技術進化の間に生まれた新たなジレンマを深掘りします。
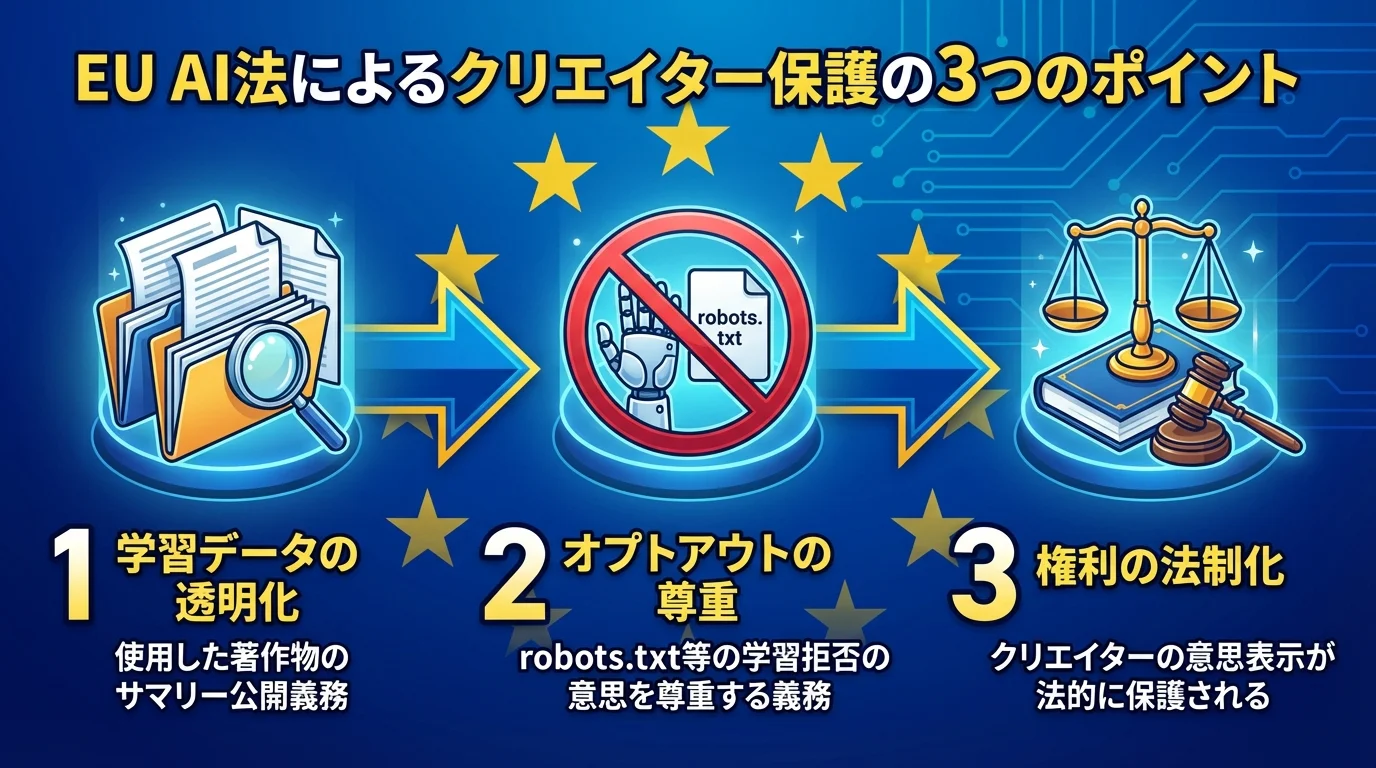
世界標準となるか?EUのAI法が示す著作権保護の現在地
AIと著作権の対立に、EUが一石を投じました。2026年までに全面施行されるEUのAI法は、AI開発者に対し、学習に用いた著作物データのサマリー公開と、クリエイターによる学習拒否(オプトアウト)の意思を尊重する義務を課します。これにより、これまで紳士協定に過ぎなかったrobots.txtなどによる意思表示が、EU市場では法的な意味を持つことになります。日本の著作権法では解釈が曖昧な部分が残る中、巨大市場であるEUの明確なルールは、事実上の「世界標準」となる可能性を秘めています。技術的な自衛策も進化しており、AI学習禁止の切り札かと期待される電子透かし技術もその一つですが、それを支える法整備の重要性をEUの動向は明確に示しているのです。
ワンクリックで意思表示、AIクローラー遮断機能の普及
これまでrobots.txtの編集など専門知識が必要だったAI学習の拒否が、技術の普及により誰でも手軽に意思表示できる時代へと移行しています。象徴的なのは、エックスサーバーといったレンタルサーバー事業者が提供を開始したワンクリック遮断機能です。これにより、専門知識がないサイト運営者でも管理画面から主要AIクローラーのアクセスを一括で拒否できるようになりました。
さらに、アクセスを拒むだけでなく、画像データに人間には見えない加工を施し、AIの学習を内側から混乱させる「Glaze」や「Nightshade」のような能動的な防御技術も登場しています。こうしたAI学習禁止の切り札かともいえるツールの普及は、クリエイターが自らの権利を守るための強力な武器となり、AI開発企業に適正なデータ利用を促す圧力にもなっています。
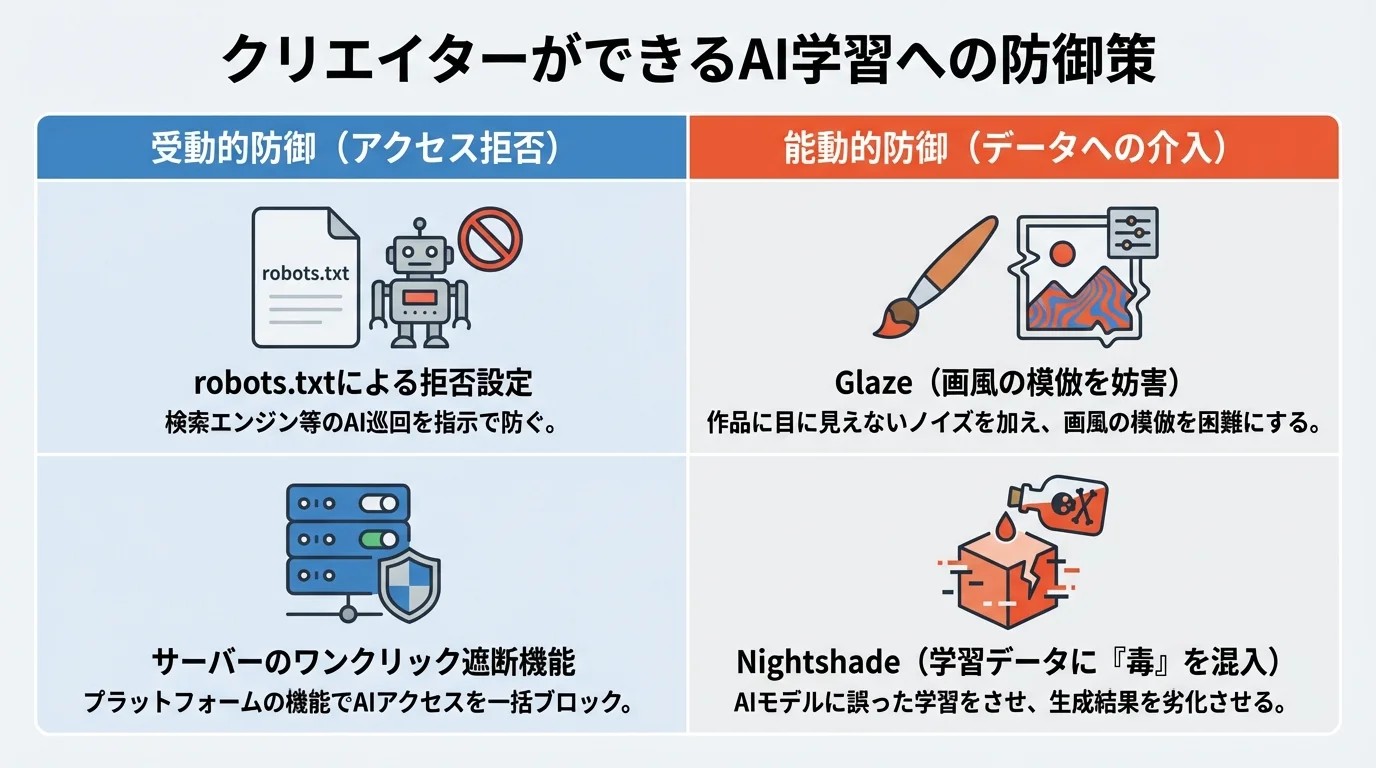
AI開発の壁、データ枯渇が招く「AIの2026年問題」とは?
AI開発の急速な進歩の裏で、新たな課題が浮上しています。それが、高品質な学習データが2026年頃に枯渇すると予測される「AIの2026年問題」です。大規模言語モデル(LLM)の性能向上にはインターネット上の膨大なテキストデータが不可欠ですが、信頼性の高いデータは有限です。このデータ枯渇は、AI開発者が学習禁止の意思表示を無視し、著作物や個人情報を無断で利用するインセンティブを高める危険性をはらんでいます。結果としてクリエイターの権利侵害が深刻化するだけでなく、AIの倫理的な問題も加速しかねません。この問題は、AIの持続可能な発展のためには、正当な対価を払ってデータを確保するライセンス市場の整備や、AI学習禁止の切り札かと期待される新たな権利保護技術の確立が急務であることを示唆しています。
なぜ今「AI学習禁止」が重要なのか?生成AIの進化と著作権保護の狭間で
AI技術の進化は、もはや誰にも止められません。EUのAI法などルール作りは進むものの、法整備はまだ技術の猛スピードに追いついていないのが現状です。一方でAI開発側は、学習データの枯渇が予測される「AIの2026年問題」に直面し、新たなデータを求めています。このような状況で、自らの意思表示がなぜ作品の価値を守る最後の砦となりうるのか。その本質的な重要性を、多角的な視点から解き明かしていきます。
止まらないAIの進化、あなたの作品価値を守る最後の砦
AIの進化という濁流に対し、法整備という堤防の完成をただ待つだけでは、あなたの作品価値は押し流されてしまうかもしれません。もはやrobots.txtのような受動的な意思表示だけでは不十分です。今、クリエイターが注目すべきは、シカゴ大学が開発した「Nightshade」のような能動的な防御ツールの存在です。これは、画像に特殊な加工を施し、AIが画風を模倣するのを防ぐだけでなく、学習データに「毒」を混ぜてモデルを内部から混乱させる技術。まさに、これはAI学習禁止の切り札かもしれません。こうした技術的自衛こそが、止まらないAIの進化の波から、あなたの創造性と作品価値を守る最後の砦となるのです。
法整備はまだ過渡期、著作権保護の最前線は自己防衛から
EUのAI法が2026年に全面施行されるなどルール作りは進むものの、日本の著作権法第30条の4の解釈は依然として曖昧で、法的な保護は万全とは言えません。この法整備の過渡期において、クリエイターや企業の権利保護は、国やプラットフォームの対応を待つ「受け身」の姿勢では不十分です。むしろ、積極的に権利を守る「自己防衛」こそが最前線となっています。実際に、robots.txtの指示を無視する事業者も指摘されており、紳士協定に頼るだけではリスクが残ります。幸い、エックスサーバーなどが提供するワンクリックでの「AIクローラー遮断機能」や、画像に特殊な加工を施す「Glaze」「Nightshade」など、AI学習禁止の切り札かとも言える能動的な防御技術も登場しています。学習データ枯渇が懸念される「AIの2026年問題」を前に、こうした技術的対策を講じることが、自身のコンテンツ価値を守るための現実的な第一歩となるのです。
データ枯渇と権利保護のジレンマ、今こそ意思表示が鍵に
AI開発の現場では、高品質な学習データが2026年頃に枯渇するという「AIの2026年問題」が現実味を帯びています。このデータの枯渇は、許諾を得ていないコンテンツの無断利用を加速させるリスクをはらんでおり、クリエイターの権利保護とのジレンマを一層深刻化させています。このような状況で待ったなしとなっているのが、クリエイターによる明確な意思表示です。EUのAI法がオプトアウトの尊重を義務付けるように、robots.txtなどによる学習拒否の表明は、もはや単なる「お願い」ではありません。さらに「Nightshade」のようなAI学習禁止の切り札かと期待される能動的な防御技術も登場しています。こうした意思表示と自衛の積み重ねが、健全なライセンス市場の形成を促し、AI開発者との新たな関係性を築く第一歩となるのです。
【2026年最新動向】EUのAI法施行とワンクリック遮断機能の登場
クリエイターによる「学習させない」という意思表示が、ついに具体的なルールとツールを手に入れようとしています。2026年の全面施行が迫るEUのAI法は、あなたのオプトアウトに法的な意味を与え、レンタルサーバーが提供を開始したワンクリック遮断機能は、専門知識の壁を取り払います。法整備と技術革新がもたらす、権利保護の新時代を詳しく見ていきましょう。
EUのAI法施行で新時代へ、学習データの透明化が義務に
2026年に全面施行が予定されているEUのAI法は、これまで紳士協定に過ぎなかった「学習させない」という意思表示に、法的な実効力をもたらす画期的なルールです。この法律の核心は、AI開発者に対して課される学習データの透明化義務にあります。具体的には、AIのトレーニングに使用した著作物の「詳細なサマリー」を公開することが求められるため、クリエイターは自らの作品が利用されたかどうかを事後的に検証する道が開かれます。
さらに、robots.txtなどで示されたオプトアウトの意思を尊重することも義務化されます。これにより、クリエイターの意思表示は単なる「お願い」ではなく、EU市場においては法的に保護される権利へと昇華するのです。こうした法整備と並行して、AI学習禁止の切り札かと期待される技術的な自衛策も進化しており、クリエイターの権利保護は新たな時代を迎えようとしています。
専門知識は不要に?ワンクリックAI遮断機能がついに登場
これまで「AI学習禁止」の意思表示は、robots.txtファイルの編集など、ある程度の専門知識を要する作業でした。しかし2026年に入り、その状況は一変します。エックスサーバーをはじめとする一部のレンタルサーバー事業者が、管理画面からワンクリックで主要なAIクローラーを遮断できる機能の提供を開始したのです。
この機能を使えば、サイト運営者は専門知識がなくても、自身の文章や画像が意図せずAIの学習データとして利用されるのを手軽に防げます。技術的なハードルが劇的に下がったことで、個人のブロガーから中小企業のウェブ担当者まで、誰もが当たり前にオプトアウト(学習拒否)を選択できる時代が到来しました。画像を守るためのAI学習禁止の切り札かと期待される技術も登場しており、クリエイターが自衛する手段は、かつてないほど身近なものになっています。
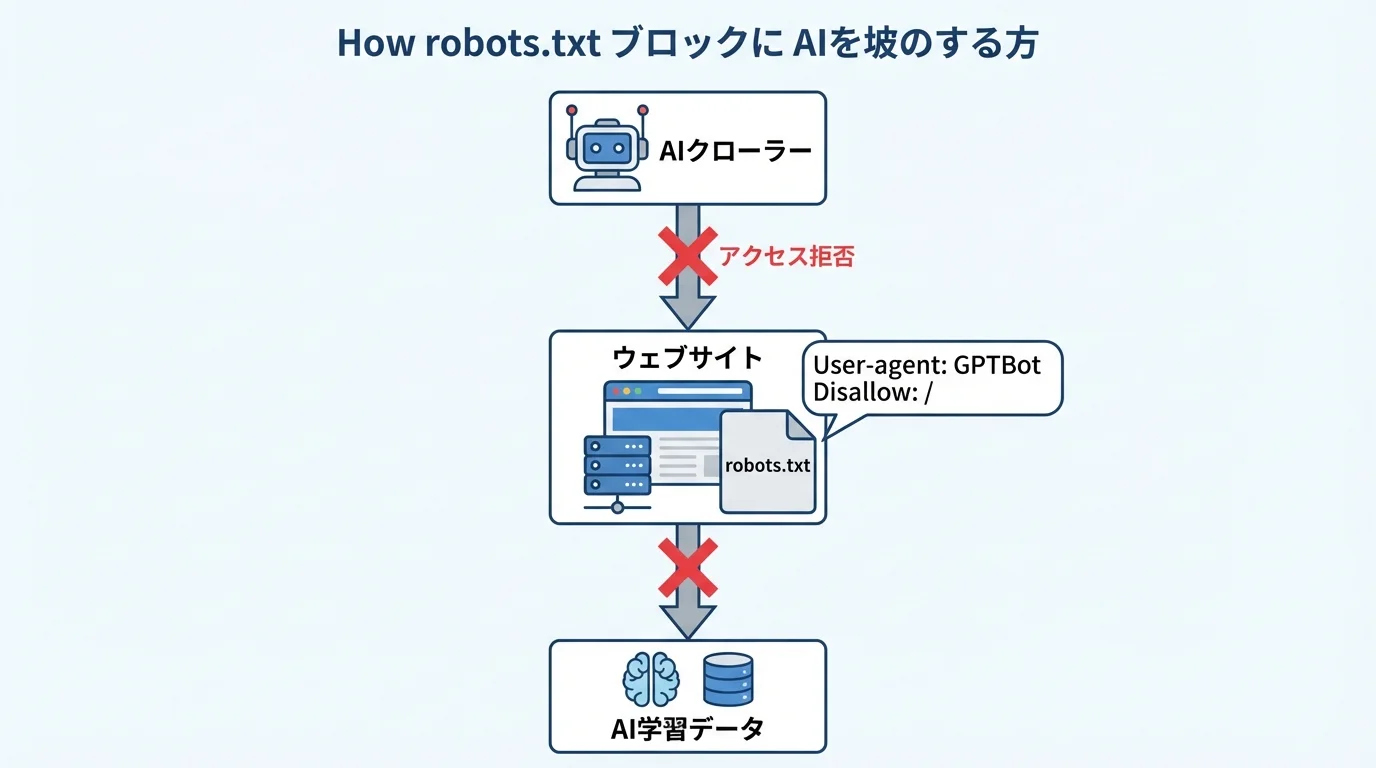
意思表示の標準化進む、機械が読むオプトアウトとは?
「AIに学習させない」というクリエイターの意思を、どうすれば開発者に確実に伝えられるのでしょうか。その答えが、人間だけでなく機械が直接読み取れる形式で意思表示を行う「機械可読なオプトアウト」です。具体的には、ウェブサイトのルールブックであるrobots.txtファイルに、「User-agent: GPTBot」や「User-agent: Google-Extended」といった記述を追加し、特定のAIクローラーのアクセスを拒否する方法が標準となっています。
これまで紳士協定に過ぎなかったこの意思表示は、2026年のEU AI法施行により、法的な意味合いを帯び始めています。しかし、検索用とAI学習用のクローラーが分離されていないなど課題は残っており、日本新聞協会をはじめとする業界団体は、より実効性のあるプロトコルの標準化を求めているのが現状です。robots.txtを補完する技術として、画像に直接情報を埋め込むAI学習禁止の切り札かといったアプローチも注目されています。
AI学習禁止の未来は?クリエイターとAIが共存する社会への展望
「AI学習禁止」の動きは、単なる防御策や対立の構図で終わるのでしょうか。むしろ、2026年の施行が迫るEUのAI法に代表されるルール作りは、クリエイターとAIが共存するための新たな土台です。学習データの枯渇が叫ばれる「2026年問題」を乗り越え、無断利用ではなく適正な対価が支払われるライセンス契約など、敵対から共創へと向かう動きも始まっています。ここでは、尊重から生まれる新しい創作のかたちと、AIと共に歩む未来の社会像を探ります。
法整備が拓く未来、クリエイターとAIの新たなルール作り
技術的な対策だけでは、AIによる無断学習を防ぐには限界があります。robots.txtなどの意思表示は事業者の「良識」に依存するため、法的な裏付けが不可欠です。その試金石となるのが、2026年に全面施行されるEUのAI法です。これは学習データの透明性確保やクリエイターのオプトアウト(学習拒否)の尊重を義務付け、意思表示に法的な実効性を与えます。一方、日本では著作権法の解釈が課題であり、NAFCA(創作文化を守る未来の会)などが新たな「生成AI法」の検討を提言しています。AI学習禁止の切り札かと期待される技術と法整備が両輪となることで、クリエイターが安心して創作できる、持続可能な共存関係が築かれるのです。
敵対から共創へ、尊重から生まれる新しい創作のかたち
「AI学習禁止」の動きは、単なる拒絶や技術への反発ではありません。むしろ、AI開発側とクリエイターが健全な関係を築くための対話の始まりと捉えるべきです。実際に、AP通信がOpenAIと提携してニュース記事のライセンス契約を結んだように、コンテンツの価値を認め、適正な対価を支払って学習データを確保する「ライセンス市場」が形成されつつあります。これは、無断利用という敵対関係から、互いの価値を認め合う共創関係への重要な転換点と言えるでしょう。
クリエイター側も、AI学習禁止の切り札かと期待される「Glaze」のようなツールで創作の主導権を握り、AIと人間の創作を区別する「C2PA」のような技術で自身の作品の価値を証明する時代に入っています。これからの創作とは、AIを一方的に拒絶するのではなく、尊重とルールを基盤に、AIを新たな表現を生み出すパートナーとして活用する、新しいかたちへと進化していくのです。
「2026年問題」を越えて、適正な対価が巡る未来へ
AI開発における「2026年問題」、すなわち高品質な学習データの枯渇は、逆説的にクリエイターにとっての好機となり得ます。これまで問題視されてきた無断利用、いわゆる「フリーライド」がビジネスモデルとして限界を迎え、AI開発側は質の高いデータを確保するため、適正な対価を支払う方向へと舵を切り始めています。OpenAI社がAP通信とライセンス契約を結んだのはその象徴です。これは、クリエイターの作品が単なる素材ではなく、AIの進化を支える「資産」として正当に評価される市場が形成されつつあることを示唆しています。「学習させない」という意思表示は、最終的に創造性が報われる健全な経済圏を築くための、重要な第一歩と言えるでしょう。
クリエイター必見!今日からできるAI学習禁止の具体的な設定方法
理論や背景を理解した今、次なる関心は「具体的にどうすれば?」という点でしょう。ご安心ください。もはや専門知識は必須ではありません。レンタルサーバーが提供するワンクリック遮断機能から、ウェブサイトの意思表示の基本となるrobots.txtの設定、利用者の多いSNSでの対応まで、今すぐ実践できる具体的な方法が存在します。あなたの作品を守るための最初の一歩を、ここから始めましょう。
レンタルサーバーの新機能!ワンクリックでAI学習を遮断
これまでrobots.txtファイルの編集といった専門知識が障壁となっていたAI学習の拒否設定が、劇的に身近なものになりました。2026年に入り、エックスサーバーなどの主要レンタルサーバーは、管理画面からワンクリックでAIクローラーを遮断できる新機能を提供開始。これにより、技術的な知識がないクリエイターやサイト運営者でも、自身の文章や画像がChatGPTやGeminiの学習データとして無断利用されるのを簡単に防ぐことが可能になったのです。
この手軽な設定は、クリエイターが自衛する上で大きな武器となります。ただし、この機能も万能ではなく、あくまでルールを守るクローラーにのみ有効な「紳士協定」である点は忘れてはなりません。より能動的な防御策として、画像データそのものに働きかけるAI学習禁止の切り札かといった技術も登場しており、複数の対策を組み合わせる視点が今後ますます重要になるでしょう。
全サイトに適用!robots.txtによるAIクローラー拒否設定
レンタルサーバーの新機能が使えない環境でも、自身のサイト全体をAIの学習から守る、最も基本的かつ国際標準の方法がrobots.txtファイルによる設定です。これは、AI開発者に対し「機械可読な形式」で学習拒否の意思を伝えるためのプロトコルであり、2026年施行のEUのAI法でも尊重が求められる重要な意思表示となります。
具体的には、サイトのルートディレクトリにあるrobots.txtに、以下のように特定のAIクローラーを拒否する記述を追加します。
Google-Extendedを指定すれば、Google検索への表示は維持しつつ、GeminiなどAIモデルへの学習を防ぐことが可能です。ただし、この設定はクローラー側の良識に依存する紳士協定であり、ルールを無視する事業者には効果がありません。そのため、robots.txtは必須の第一歩と捉えつつ、AI学習禁止の切り札かと期待される別の防御策も視野に入れる必要があります。
SNSや投稿サイトは?プラットフォームごとの設定最新動向
自身のサイトと異なり、SNSや投稿サイトではrobots.txtを直接編集できません。そのため、クリエイターの意思表示はプラットフォーム側の機能に委ねられます。先進的な事例として、noteなどのプラットフォームではアカウント設定からワンクリックで「生成AIの学習拒否」の意思を示せる機能が標準搭載され始めています。
さらに、Webページや画像に「noai」といったメタデータを埋め込むことで、AI開発者へ学習禁止の意向を伝える標準化の動きも試験的に始まっています。これらはまだ紳士協定の域を出ませんが、重要な一歩です。プラットフォームの機能に頼るだけでなく、クリエイター自身が作品に特殊な加工を施す「見えない透かし」技術はAI学習禁止の切り札かと期待されており、自衛手段も多様化しています。今後は、どのプラットフォームがクリエイターの権利保護に積極的か、その姿勢を見極めることが不可欠となるでしょう。
AI学習禁止の限界と批判的視点|技術進化を阻害する可能性とは?
クリエイターの権利を守るため「AI学習禁止」を掲げるのは、一見すると正義のように聞こえる。だが、思考停止に陥ってはいないだろうか。このセクションでは、そんな楽観論に冷や水を浴びせ、「禁止」という選択が孕む技術的な限界と、それが招きかねない技術進化の停滞という皮肉な未来を直視する。データ枯渇が新たなデジタル格差を生むという不都合な真実から、目を背けるわけにはいかない。
技術的対策は万能ではない?抜け道を許す根本的な課題
robots.txtの設定やサーバーのワンクリック遮断機能に安堵するのは早計だ。これらの対策は、ルールを守る気のある事業者に対する紳士協定に過ぎず、悪意を持ってデータを収集するクローラーの前では全くの無力。ユーザーエージェントを偽装されれば、もはや特定してブロックすることさえ不可能になる。
画像に「毒」を盛る「Nightshade」のような能動的防御ツールも登場しているが、これもAIモデルの進化とのいたちごっこになる可能性は否めない。そもそも、過去に学習されてしまったデータは取り戻せず、日本の著作権法のように「不当に利益を害する場合」という曖昧な解釈が残る限り、技術的な自衛策は気休めでしかないのが現実だ。
データ枯渇という現実、AI技術の発展を阻む両刃の剣
「学習させない」というクリエイターの権利主張が、AI開発の現場を崖っぷちに追い込んでいる現実から目を背けてはならない。専門家が警鐘を鳴らす「AIの2026年問題」、すなわち高品質な学習データの枯渇は目前の危機だ。この状況は技術の健全な発展を促すどころか、倫理観の欠如した業者に不正利用のインセンティブを与えるだけだろう。データがなければ、手段を選ばなくなるのがビジネスの現実だ。ルールを無視した無断収集や、質の悪い合成データによる「汚染」が横行しかねない。結局、クリエイターが守りたかったはずの創造性の価値すら貶めるAIが生まれるという皮肉な結末だ。データ枯渇はAIの進化を止めるブレーキではなく、暴走を促す両刃の剣に他ならない。
大企業によるデータ独占へ?新たなデジタル格差の懸念
「AI学習禁止」はクリエイターの正当な権利主張だが、その裏で笑うのは誰か、冷静に見極める必要がある。オープンなウェブデータが利用できなくなれば、AI開発の参入障壁は一気に高騰する。結果、豊富な資金力でAP通信のような大手メディアとライセンス契約を結べる巨大テック企業だけが、高品質なデータを独占する未来が訪れるだろう。一方で、資金のないスタートアップや研究機関は締め出され、イノベーションは停滞。クリエイター保護という大義名分が、皮肉にも新たなデジタル格差を生み出し、AI技術の寡占化を後押ししかねない。この不都合な構造を直視せずして、健全な未来など描けるはずもない。
まとめ:AIと共創する未来へ、私たちが考えるべき権利の在り方
「AI学習禁止」の潮流は、生成AIの進化がもたらした創造性の権利と技術発展のジレンマを象徴する動きです。本記事では、その背景にある著作権の問題から、EUのAI法といった国際的なルール形成、そしてクリエイター自身が取りうる具体的な対策まで、多角的に掘り下げてきました。
この問題は、技術を制限するか否かという単純な二元論ではありません。クリエイターの努力と成果をいかに正当に保護し、テクノロジーと共創していくかという、社会全体のルール作りが問われています。私たちは今、倫理とイノベーションが交差する大きな転換点に立っているのです。対立を乗り越え、健全なエコシステムを構築するために、私たち一人ひとりが当事者として考え、行動することが未来を形作ります。
これからの時代、AIを事業成長の追い風とするためには、こうした権利問題への配慮と明確な戦略が不可欠です。
■ 【期間限定】2025年最新版『AI・DX推進戦略ハンドブック』無料プレゼント中!
100社以上の相談実績から導き出した「失敗しないAI導入の7ステップ」を網羅したハンドブックを無料で進呈します。ご希望の方には、ハンドブックの内容に基づき、貴社に最適なAI活用法をご提案する「自社専用AI活用ロードマップ」の無料作成会も実施しております。