
画像認識AIとは?基本的な種類とマルチモーダル化への進化
画像認識AIは、もはや単に画像内の物体を識別するだけの技術ではありません。このセクションでは、物体検出のような基本的な画像認識AIの種類から、テキストと画像を同時に理解する「マルチモーダル化」という最先端の進化までをわかりやすく解説します。実際に最新のベンチマークでは、GoogleのGeminiシリーズなどが高い画像理解能力を示しており、AIは複雑な文脈を読み解く段階に入りました。最適なAIを選ぶ第一歩として、まずはこの進化の全体像を把握していきましょう。
物体検出や分類など、画像認識AIの主な種類
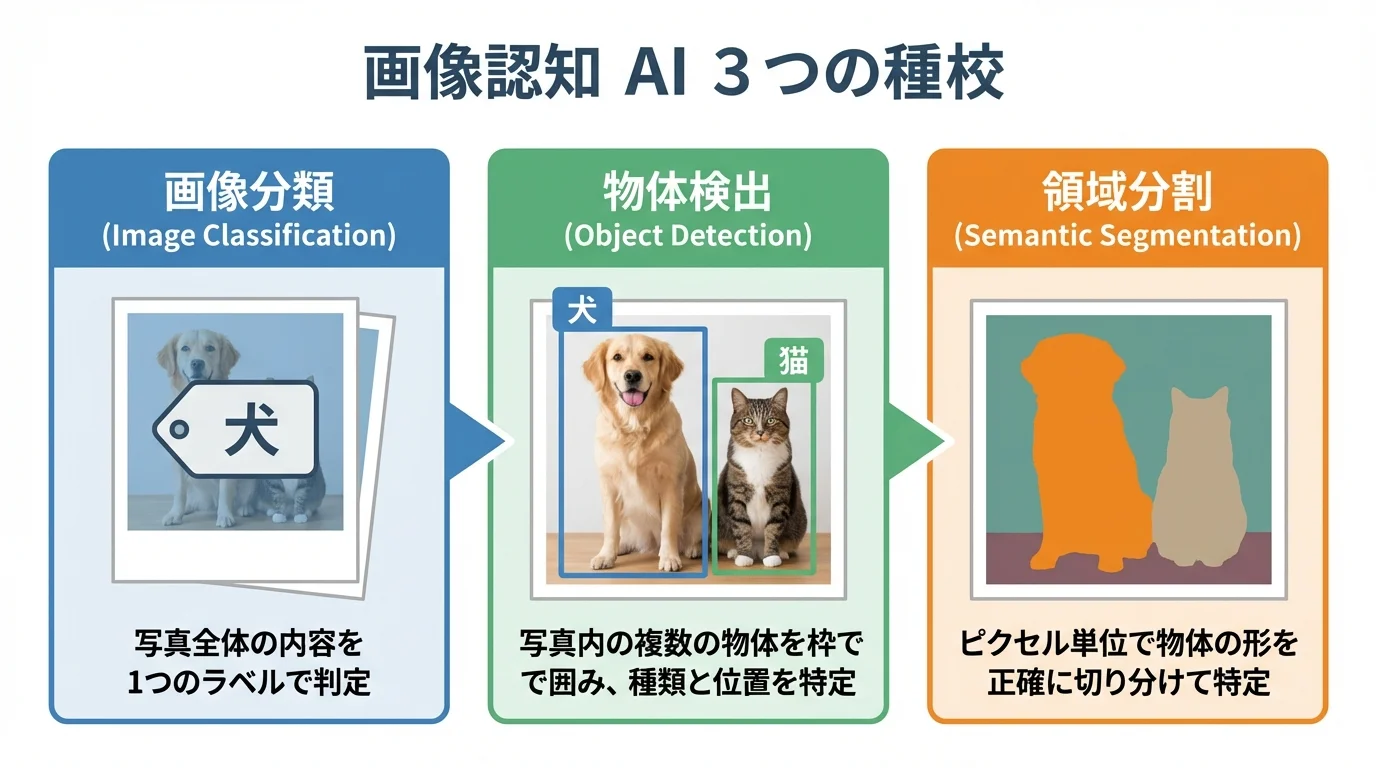
画像認識AIと一言でいっても、その機能は目的によって複数の種類に分かれます。代表的なものとして、画像全体が何かを当てる「画像分類」、画像内の物体の位置と種類を特定する「物体検出」、ピクセル単位で物体の形を正確に塗り分ける「領域分割(セグメンテーション)」があります。
例えば、自動運転では物体検出で人や車を認識し、医療現場では領域分割で患部を特定します。また、製造ラインでは、正常品と異なるパターンを見つけ出す「異常検知」が画像検査AIの導入を加速させているのです。これらの技術はそれぞれ得意なことが違うため、自社の課題にどの種類が最適かを見極めることが重要になります。より詳しい進化する画像認識AIの仕組みとはを知ることで、選定の精度はさらに高まります。
あわせて読みたい
画像検査 AIについて、導入方法から活用事例まで詳しく解説します。

画像 認識 ai 仕組みについて、導入方法から活用事例まで詳しく解説します。
テキストも理解するマルチモーダルAIへの進化
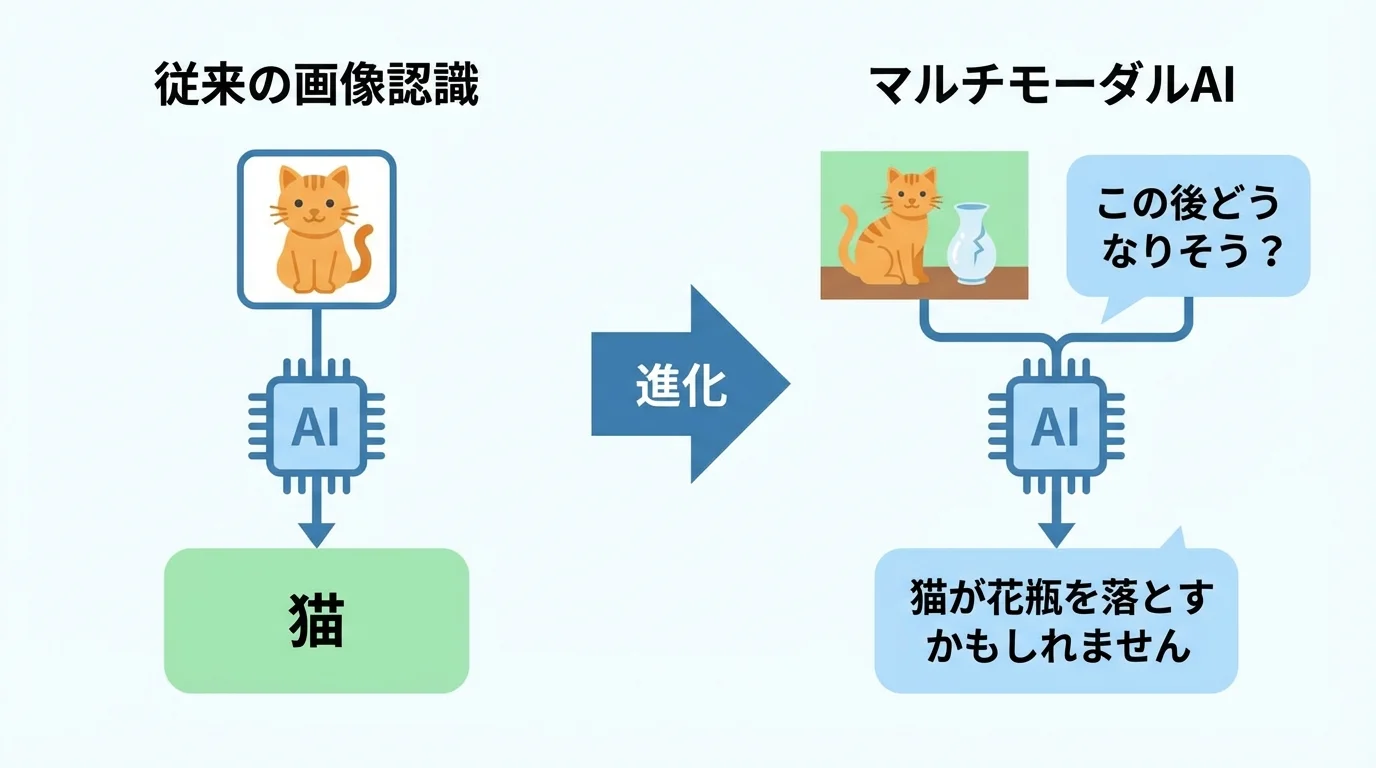
近年の画像認識AIは、画像だけでなくテキストも同時に扱うマルチモーダルAIへと進化を遂げました。これは単に画像に写るモノを識別するだけでなく、「この画像の状況を説明して」といった、文脈を読み解く対話が可能になったことを意味します。この能力は、MMMU(大規模マルチモーダル理解)といった最新ベンチマークで評価されており、GoogleのGeminiシリーズがリーダーボードの上位を独占。こうした生成AI時代の画像認識AIとは、もはや単純な分類ツールではなく、より高度な知的作業を代行するパートナーになったのです。
あわせて読みたい
画像 認識 ai とはについて、導入方法から活用事例まで詳しく解説します。
単純な認識を超え、複雑な文脈を理解する新潮流
マルチモーダルAIの進化は、単一の画像解説に留まりません。最新のトレンドは、複数の画像や動画解析から一貫した文脈や因果関係を読み解く、より高度な推論能力です。例えば、MMMU Proといった最新ベンチマークでは、GoogleのGeminiシリーズがトップクラスのスコアを記録。これは、単に「猫がいる」と認識するだけでなく、「棚の上の花瓶を猫が落としそうだ」という状況の予測まで可能になることを示唆しています。こうした推論能力の有無は、将来的に複雑な業務を自動化できるかを見極める重要な判断基準となるでしょう。まさに生成AI時代の画像認識AIとは何かを定義する動きなのです。
あわせて読みたい画像 認識 ai とはについて、導入方法から活用事例まで詳しく解説します。
【2025年版】画像認識AIの選び方|業務への組み込みと将来性を見極める比較ポイント
ここからは、画像 認識 ai 種類のおすすめ10選を紹介します。それぞれの特徴やメリットを詳しく解説していますので、導入検討の参考にしてください。
1位:Google Cloud Vision AI
Google Cloud Vision AIは、Googleの強力な機械学習モデルをREST API経由で利用できる画像認識サービスです。開発者は、アプリケーションに高精度な画像分析機能を迅速に組み込むことが可能になります。
主な強みは、その多機能性と精度の高さにあります。画像内のテキストを高精度で読み取るOCR機能や、物体・ロゴ・顔の検出、不適切なコンテンツのフィルタリングまで、事前学習済みのモデルが幅広く提供されています。また、Vertex AIなど他のGoogle Cloudサービスとの連携が容易なため、画像認識を起点とした高度なデータ分析基盤の構築もスムーズです。
2026年現在、API自体の大きな機能追加はありませんが、Googleの最新マルチモーダルAI「Gemini」との統合が深化しています。これにより、単なる物体検出を超え、画像の内容を文脈で理解する高度な分析が実現しました。自律的にタスクをこなす「AIエージェント」の「目」としての役割も担い、LMSYS Arenaなどのベンチマークでもその基盤技術は高い評価を獲得しています。
料金体系は機能ごとの従量課金制で、毎月最初の1,000ユニットまで無料枠が適用されます。ただし、無料枠利用時も請求先アカウントの設定は必須なので注意しましょう。
開発コストを抑えつつ迅速に高精度な画像認識機能を導入したい企業や、Google Cloudプラットフォームでデータ活用を推進したいプロジェクトに最適です。
2位:Amazon Rekognition
AWSが提供する、機械学習の専門知識がなくてもAPI経由で高度な画像・動画分析をアプリに実装できるフルマネージドサービスです。物体・シーン検出や顔分析、テキスト抽出(OCR)といった豊富な機能を備えており、開発者はインフラ管理を気にすることなく機能開発に集中できます。特に、自社の製品ロゴや特定の機械部品などを認識させられる「カスタムラベル」機能は、独自のビジネスニーズへ柔軟に対応できる強力な点だと言えます。
2026年2月には不適切なコンテンツを検出するカスタムモデレーション機能の精度が向上するなど、継続的な改善が行われています。一方で、人物の動線を追跡する「People Pathing」機能は2025年10月に廃止されたため、利用を検討していた方は代替策が必要です。
料金は使った分だけ支払う従量課金制で、最初の12ヶ月間は月5,000枚の画像分析が無料になる利用枠も用意されています。開発リソースを抑えつつ、アプリに高精度な画像認識を迅速に導入したい企業や、ユーザー投稿コンテンツの健全性を保ちたいサービス運営者に向いています。
3位:Microsoft Azure AI Vision
Microsoftが提供する、開発者向けの包括的な画像・動画分析サービスです。OCRや物体検出、顔検出、独自のモデルを構築できるCustom Visionなど、ビジネスで必要とされる多彩な機能をAPI経由で手軽に利用できる点が強みです。
主な特徴は、製造業での不良品検知や小売業での顧客行動分析(空間分析)など、特定用途に特化した機能まで網羅している総合力にあります。2024年に一般提供が開始された「Image Analysis 4.0」では、テキストと画像をベクトル化して高度な検索を可能にするマルチモーダル埋め込み機能が追加されました。ただし、旧バージョンのAPIは2026年9月13日に廃止されるため、利用中の方は最新版への移行が必要です。
料金はトランザクション数に応じた従量課金制で、無料枠も用意されています。既にMicrosoft Azureを利用している企業や、一つのプラットフォームで多様な画像認識機能を実装したい開発者におすすめします。
4位:OpenCV
4位 OpenCV|研究開発から商用利用まで対応する定番ライブラリ
OpenCVは、画像処理やコンピュータビジョン分野でデファクトスタンダードとなっているオープンソースのライブラリです。物体検出や顔認識、画像フィルタリングといった500以上のアルゴリズムを標準で提供しており、C++、Python、Javaなど多様な言語から利用できます。
大きな強みは、その豊富な機能と高いカスタマイズ性にあります。オープンソースであるため、最新の研究論文で発表されたアルゴリズムを自ら実装したり、特定の用途に合わせて既存の機能を改変したりすることが可能です。2026年3月時点の最新動向として、次期メジャーバージョンであるOpenCV 5系統の開発が活発化。特にDNNモジュールの強化が進んでおり、画像とテキストを扱うVision Language Model(VLM)のサポートが向上しています。また、AWS Gravitonプロセッサ向けの最適化により、適応的閾値処理で3倍の高速化を達成するなど、パフォーマンスも大幅に改善されています。
Apache 2ライセンスで提供されており、研究開発から商用利用まで基本的に無料で利用可能です。コストを抑えつつ、独自の画像認識AIを開発したいエンジニアや研究者、スタートアップ企業に最適な選択肢です。
5位:TensorFlow
TensorFlowは、Googleが開発した機械学習向けのオープンソースライブラリです。画像認識AIをはじめ、自然言語処理や音声認識など、多様なAIモデルの開発で世界的に利用されています。研究開発から実際の製品への組み込みまで、一貫したエコシステムが提供されている点が大きな強みです。
最大の特徴は、最新バージョンでデフォルトとなったKeras 3によるマルチバックエンド対応でしょう。これにより、TensorFlowだけでなく、JAXやPyTorchを計算の裏側で切り替えて利用できます。2026年3月にはTensorFlow 2.21がリリースされ、特にオンデバイスAI向けの「LiteRT」が強化されました。このアップデートで、スマートフォンなどでのGPUパフォーマンスが大幅に向上しています。
TensorFlowはオープンソースのため、誰でも無料で利用可能です。研究から本番デプロイ、エッジAIの実装まで一気通貫で開発したい企業や、複数のフレームワークを柔軟に活用したい開発者におすすめします。
6位:PyTorch
Metaが開発を主導する、研究分野で絶大な人気を誇るオープンソースの機械学習ライブラリです。特に画像認識を含む最先端のAI研究開発で広く採用されています。
Pythonと親和性が高く直感的にコーディングできる点が大きな強みであり、Define-by-Run方式によりデバッグも容易です。2026年1月リリースのPyTorch 2.10で強化されたコンパイラ機能torch.compileは、訓練ループ全体を最適化し、8〜15%の高速化を実現します。また、PyTorch Foundationのもと、vLLMやRayといったプロジェクトが統合され、エコシステムも拡大し続けているのが特徴です。
最新のアップデートでは、Python 3.14に対応し、これまでモデルのデプロイに使われていたTorchScriptが非推奨となり、今後はtorch.exportへの移行が必要です。オープンソースのため利用は無料で、最新の研究成果を素早く実装したい研究者や、開発スピードを重視するスタートアップに最適なフレームワークです。
7位:Roboflow
Roboflowは、画像認識AIの開発に必要なデータセットの準備からモデルのトレーニング、デプロイまでを一気通貫で支援するプラットフォームです。直感的なアノテーションツールや、ワンクリックで多様なパターンを生成するデータ拡張機能が強みであり、開発の初期段階にかかる時間を大幅に短縮できます。
2026年には、最新のリアルタイム物体検出モデルYOLO26への即日対応や、Workflows機能へ「Qwen3.5-VL」といった最新マルチモーダルモデルを統合するなど、最先端技術への追随が非常に速い点も特徴です。無料のPublicプランから、月額$249〜(年間契約時)のStarterプラン、大規模開発向けのEnterpriseプランまで提供されています。
AI開発の経験が浅い方でも、迅速に高精度なモデルのプロトタイプを構築したい場合や、アノテーションからデプロイまでのワークフロー全体を効率化したい企業に最適なツールです。
8位:NVIDIA Jetson
エッジデバイス上で高度なAI推論を実現する、NVIDIAが提供する開発者向けプラットフォームです。特にロボティクスや自律動作マシンの開発分野で、世界中のエンジニアから絶大な支持を得ています。
その最大の強みは、パワフルなGPU性能と充実したソフトウェア開発環境にあります。2026年に登場した最新最上位モデル「Jetson AGX Thor」は、NVIDIAの最新アーキテクチャ「Blackwell」を採用し、最大2,070 TFLOPSという圧倒的なAI性能を誇ります。また、最新のソフトウェアスタック「JetPack 7」ではリアルタイムカーネルがサポートされ、ロボット制御に求められる低遅延で決定論的なパフォーマンスを実現します。
価格はエントリー向けの「Jetson Orin Nano 開発者キット」が約8万円からですが、上位モデルは数十万円と専門家向けです。自律走行搬送ロボット(AMR)やドローン、高度なリアルタイムAI推論システムなど、プロレベルのエッジAI開発に挑戦したい研究者や企業にとって、非常に強力な選択肢となるでしょう。
9位:Google レンズ
9位は、スマートフォンユーザーにとって最も身近な画像認識AI、Google レンズです。カメラをかざすだけで、目の前にあるテキストの翻訳、商品の検索、ランドマークの特定など、多岐にわたる情報を直感的に調べられるツールだ。多くのAndroidスマホでは標準カメラやGoogleフォトと深く連携しており、特別なアプリを意識することなくシームレスに利用できる点が強みです。
2026年3月のアップデートでは「かこって検索」機能が大幅に進化。画像に写る洋服のコーディネート一式をまとめて検索したり、気になる服を自分の写真に重ねて試着できる「Try it on」機能が日本でも利用可能になりました(Pixel 10以降)。この高精度な認識を支えるのが、AIリーダーボードでも高い性能を示すGoogleのマルチモーダルAI「Gemini」であり、2026年中に登場が予告されているAIスマートグラスの中核技術としても採用される見込み。
料金は無料で、日常生活や旅行先で手軽に情報収集をしたい個人ユーザーに最適。専門知識がなくても、すぐに最先端の画像認識技術の恩恵を受けられます。
10位:Clarifai
Clarifaiは、データのラベリングからモデルのトレーニング、デプロイ、運用まで、AI開発の全工程をカバーするフルライフサイクルAIプラットフォームです。コーディングの知識がなくても使える直感的なUIと、開発者向けの強力なAPIやCLIツールを両立させている点が大きな特徴。特に2026年3月のアップデートではCLIが刷新され、わずか3つのコマンドでAIモデルを本番環境へ迅速にデプロイできるようになりました。
料金は無料プランから利用でき、使用量に応じた従量課金やエンタープライズプランも提供されています。月単位で機能アップデートが行われるため最新情報のキャッチアップは必要ですが、インフラ管理を気にせず迅速なプロトタイピングと本番投入を実現したい開発者や企業に最適なツールです。アイデアを素早く形にしたいなら、一度試してみる価値があります。
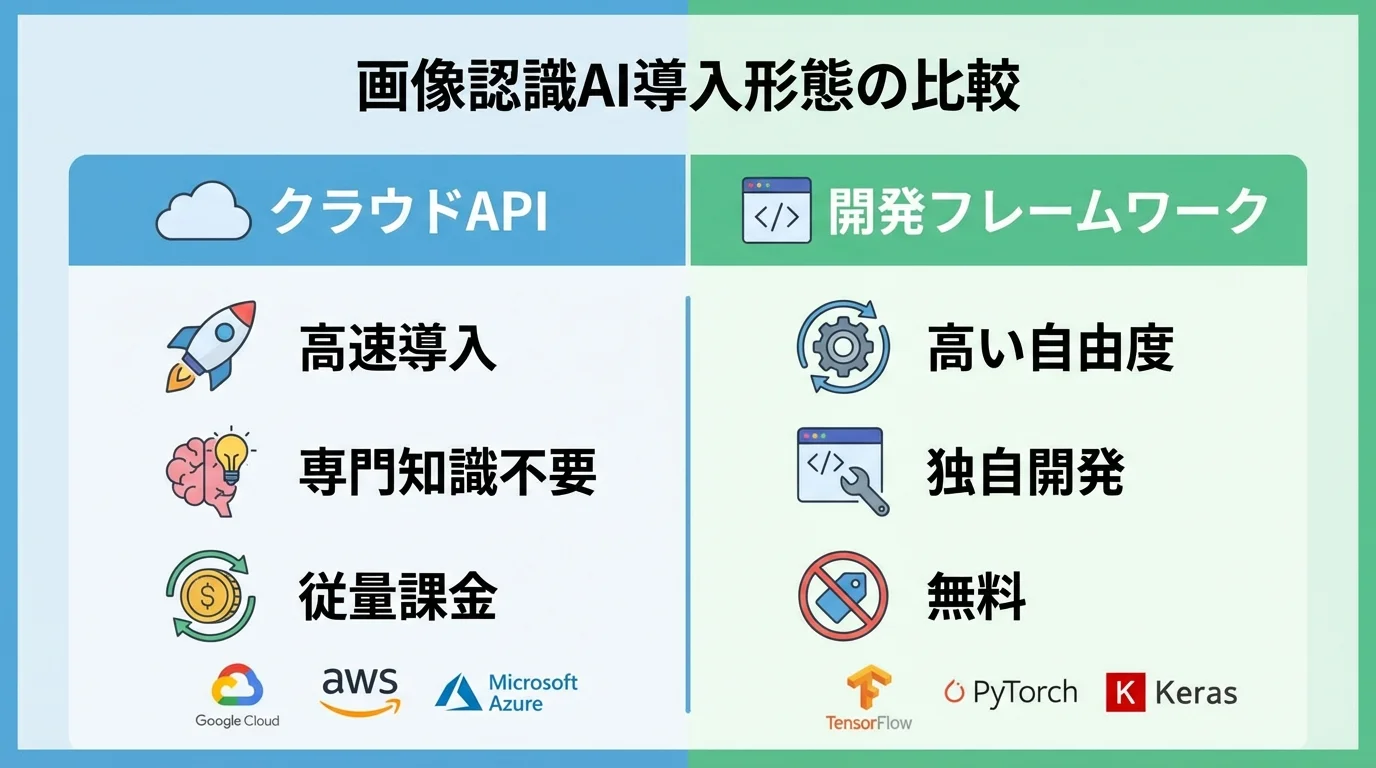
画像認識AIの機能・料金比較一覧表|クラウドAPIから開発フレームワークまで
ここまで紹介してきた多様な画像認識AIの中から、自社の課題に最適な一つを選ぶのは難しいかもしれません。そこでこの章では、主要なサービスをすぐに使える「クラウドAPI」と、自由度の高い「開発フレームワーク」の2つに分類。それぞれの機能、料金体系、そして将来性を見極める上で重要なマルチモーダル対応の有無を一覧表にまとめました。この比較表を参考に、自社の目的と開発リソースに合ったサービスを効率的に見つけてください。
主要クラウドAPIの機能・料金を比較
Google Cloud Vision AI、Amazon Rekognition、Microsoft Azure AI Visionは、いずれも高水準な画像認識機能をAPIで提供しますが、それぞれに強みがあります。GoogleはGemini統合によるマルチモーダル性能が際立ち、MMMU Proなどのベンチマークでも高いスコアを記録。複雑な画像理解や将来性で一歩リードしています。一方、Amazonは「カスタムラベル」機能により独自の物体認識を手軽に構築できる点が魅力的。Microsoftは製造業の不良品検知など、特定業種向けのソリューションが充実しているのが特徴です。
料金体系はどこも従量課金制ですが、無料枠の条件は異なります。Googleは毎月、AWSは最初の1年間、Azureも一定量の無料枠を提供しており、初期コストを抑えたい場合は重要な比較ポイントになります。自社の既存クラウド環境や、AI開発の費用相場を考慮して、最適なプラットフォームを選定してください。
あわせて読みたい
ai 開発 費用について、導入方法から活用事例まで詳しく解説します。
開発フレームワークの自由度と特徴比較
クラウドAPIが完成品の料理なら、開発フレームワークは独自のAIをゼロから作り上げるためのプロ仕様の調理器具です。OpenCV、TensorFlow、PyTorchは特に代表的な存在であり、それぞれに明確な個性があります。
TensorFlowは、Googleが開発を主導しており、本番デプロイまで見据えたエコシステムが強み。一方、PyTorchは研究コミュニティで絶大な人気を誇り、直感的なコードで開発スピードを重視するプロジェクトに向いています。OpenCVは、これら深層学習フレームワークと組み合わせ、AIモデルを動かす前後の画像処理(フィルタリングや幾何変換など)を担う場合に不可欠な存在です。どのツールを選ぶかは、生成AI時代の画像認識AIとは何かを理解した上で、最終的なゴールから逆算して判断することが成功の鍵となります。
あわせて読みたい画像 認識 ai とはについて、導入方法から活用事例まで詳しく解説します。
マルチモーダル対応で見るAIの将来性
これからの画像認識AIを選ぶ上で、将来性を測る最も重要な指標がマルチモーダル対応の有無です。これは単に画像を認識するだけでなく、テキストによる指示や質問を組み合わせて、より複雑なタスクを処理できる能力を指します。例えば、MMMU Proのような最新ベンチマークで高いスコアを出すモデルは、「この機械の画像で、マニュアル(テキスト)の安全基準を満たしていない箇所はどこか」という問いに答えられます。サービス選定時には、APIが画像とテキストを同時に扱えるかを確認してください。この視点が、単なるツールを超えた生成AI時代の画像認識AIとは何かを見極める鍵となります。
あわせて読みたい画像 認識 ai とはについて、導入方法から活用事例まで詳しく解説します。
【2025年】画像認識AIおすすめランキング10選を目的別に徹底比較
ここからは、画像 認識 ai 種類のおすすめ10選を紹介します。それぞれの特徴やメリットを詳しく解説していますので、導入検討の参考にしてください。
1位:Google Cloud Vision AI
Google Cloud Vision AIは、開発者がアプリケーションに強力な画像分析機能を簡単に組み込める、Google提供の事前トレーニング済みAPIです。
主な特徴は、物体検出、顔検出、高精度なOCR(文字認識)、不適切なコンテンツの検知といった、ビジネスですぐに使える豊富な機能を網羅している点。Googleの膨大なデータで学習した高精度なモデルを、専門知識なしで手軽に利用できるのが大きな強みである。
2026年現在の最新動向として、単なるAPIから、自律的に業務を遂行する「AIエージェント」の「目」としての役割へと進化しています。背景には最新のマルチモーダルAI「Gemini」ファミリーとの統合深化があり、これにより画像の文脈理解能力が飛躍的に向上しました。料金は機能ごとの従量課金制で、毎月最初の1,000ユニットまでは無料枠が適用されるため、スモールスタートも可能です。
Webサービスに手軽に画像認識を実装したい開発者から、大量の画像データを活用して業務を自動化したい企業まで、幅広いニーズに対応します。
2位:Amazon Rekognition
Amazon Rekognitionは、AWSが提供するフルマネージドの画像・動画分析サービスです。機械学習の専門知識がなくても、APIを呼び出すだけで物体検出や顔分析、テキスト認識(OCR)といった高度な機能をアプリケーションに組み込めます。特に、自社製品のロゴや特定の機械部品など、独自の物体を認識させたい場合に有効な「カスタムラベル」機能は大きな強みでしょう。
2026年2月には不適切なコンテンツを検出する機能の精度が向上するなど、継続的なアップデートが行われています。一方で、動画内の人物の動線を追跡する「People Pathing」機能は2025年10月末に廃止されたため、この機能が必要な場合は代替手段の検討が必要です。料金は分析した画像数や動画時間に応じた従量課金制で、無料利用枠も用意されています。
すでにAWSをインフラとして利用しており、既存のシステムに画像認識機能を迅速に追加したい開発者や、ユーザー投稿コンテンツのモデレーションを自動化したい企業に最適です。
3位:Microsoft Azure AI Vision
Microsoftが提供する、開発者向けの多機能な画像・動画解析サービスです。高精度な学習済みモデルをAPI経由で手軽に利用できるため、機械学習の専門知識がなくても高度な機能を自社システムに組み込めます。
主な強みは、その機能の網羅性にあります。画像から物体や人物を検出する基本的な分析はもちろん、高精度のOCR(光学文字認識)、リアルタイム動画から人の動きを分析する空間分析、独自の画像でモデルを学習させる「Custom Vision」まで、幅広いニーズに対応可能です。特に、旧Computer Vision APIが2026年9月13日に廃止されるため、最新の「Image Analysis 4.0」への移行が推奨されており、これによりテキストと画像をベクトル化して高度な検索を行うマルチモーダル機能などが利用できます。
料金は従量課金制で、無料利用枠も用意されています。既にAzure環境を利用している企業や、OCRから物体検出まで多様な機能を一つのサービスで実現したい開発者におすすめです。
4位:OpenCV
OpenCVは、画像認識やコンピュータビジョンの研究開発で世界的に利用されている、オープンソースのライブラリです。学術用途から商用製品まで、非常に幅広い分野で活用されている実績があります。
豊富な画像処理・機械学習アルゴリズムを標準で搭載しており、C++やPythonなど多様な言語から利用できる点が強みです。また、Apache 2ライセンスで提供されているため、商用利用のハードルが低いのも魅力となっています。
2026年3月現在、メジャーバージョンであるOpenCV 5系統への移行が進んでおり、C++17が必須となるなど近代化が図られています。開発中の機能としてはDNNモジュールの強化が著しく、画像とテキストを扱うマルチモーダルAI(VLM)のサポート向上が進行中です。さらに、アルゴリズムの最適化により、適応的閾値処理で3倍の高速化を達成するなど、パフォーマンスも向上し続けています。
ライセンス費用は無料で、誰でも自由に利用を開始できます。コストを抑えつつ、独自の画像認識システムをゼロから構築したいエンジニアや研究者にとって、第一候補となるライブラリです。
5位:TensorFlow
Googleが開発したTensorFlowは、機械学習と深層学習の分野で豊富な実績を持つオープンソースライブラリです。研究開発からスマートフォン、クラウドでの本番運用まで、一貫したエコシステムを提供している点が最大の強みだと言えます。
主な特徴は、Keras 3をデフォルトAPIとして採用したことによる柔軟性の向上です。これにより、バックエンドをJAXやPyTorchに切り替えながら開発を進めることが可能になりました。2026年3月にリリースされたTensorFlow 2.21では、オンデバイスAI向けの新しいランタイム「LiteRT」が製品版となり、従来のTFLiteと比較してGPUパフォーマンスが1.4倍向上するなど、エッジデバイスでの性能が大幅に強化されています。
オープンソースのため無料で利用できます。研究から製品へのスムーズな移行を目指す企業や、スマートフォンなどのエッジデバイスで高性能な画像認識を実装したい開発者におすすめです。
6位:PyTorch
Meta社が開発を主導する、Pythonベースのオープンソース機械学習ライブラリです。研究開発から本番環境へのデプロイまで、幅広い用途で絶大な支持を集めています。
主な強みは、Pythonの構文に近く直感的に書けるコードと、Define-by-Run方式によるデバッグのしやすさです。この柔軟性の高さから、最新の論文やアルゴリズムがPyTorchで実装されることが多く、最先端の技術をいち早く試したい開発者にとって最適な選択肢となります。
2026年1月にリリースされたPyTorch 2.10では、コンパイラ機能のtorch.compileがさらに進化。訓練ループ全体を最適化し、最大8〜15%の高速化を実現しました。また、これまで使われてきたTorchScriptが非推奨となり、今後はtorch.exportへの移行が推奨される点には注意が必要です。
料金は無料で、誰でも利用できます。
最新の研究成果を迅速に実装したい研究者や、カスタマイズ性の高いAIモデルを構築したい開発者におすすめです。
7位:Roboflow
Roboflowは、コンピュータビジョンモデル開発の全工程を効率化する統合プラットフォームです。データセットの準備からアノテーション、モデルのトレーニング、そしてデプロイまでをシームレスに実行できます。
主な強みは、最新AIモデルへの迅速な対応力と、開発サイクル全体を加速させる豊富なツール群でしょう。例えば、2026年1月にリリースされた物体検出モデル「YOLO26」を翌日にはプラットフォームで完全サポートしました。また、Workflows機能では「Qwen3.5-VL」といった最新のマルチモーダルモデルが統合され、画像認識と自然言語処理を組み合わせた高度なパイプライン構築が可能です。さらに、10万以上の公開データセットが集まるコミュニティ「Roboflow Universe」も、開発者にとって大きな魅力となります。
料金は個人や学習向けの無料プランから、チーム向けのStarterプラン(月額$249〜)、大規模開発に対応するEnterpriseプランまで用意されています。独自のデータで最新のAIモデルを素早く試し、管理・デプロイまでを一気通貫で行いたい開発者や企業に最適なツールです。
8位:NVIDIA Jetson
ロボットやドローンなど、エッジデバイス上で直接AIを動かしたい開発者向けのプラットフォームがNVIDIA Jetsonです。クラウドに頼らず、現場でリアルタイムに画像認識やデータ処理を完結させられるため、低遅延と高セキュリティが求められる用途に強みを持っています。
主な特徴は、手のひらサイズの「Jetson Orin Nano」から超高性能な最新モデルまで、用途に合わせて選べるスケーラブルなハードウェアラインナップにあります。2026年には、最新アーキテクチャを採用し最大2,070 TFLOPSの性能を誇る「Jetson AGX Thor」が登場。これにより、これまでエッジでは困難だった物理AIや大規模言語モデルのリアルタイム推論も可能になりました。
Jetson Orin Nano開発者キットが数万円台から入手できる一方、高性能モデルは数十万円と、本格的な開発者向けです。自律走行ロボットや工場の自動検査システムなど、特定のハードウェアにAI機能を組み込みたい企業や研究者におすすめします。
9位:Google レンズ
9位は、誰でも無料で使えるGoogleの「Google レンズ」です。スマートフォンのカメラをかざすだけで、目の前の世界を検索できる強力な画像認識AIツールであり、日常生活に溶け込んでいます。
主な特徴は、その手軽さと多機能性です。看板やメニューをリアルタイムで翻訳したり、気になった商品の価格を調べたり、植物や動物の名前を特定したりと、幅広い場面で活躍します。2026年3月のアップデートでは「かこって検索」機能が強化され、Pixel 10以降では洋服のバーチャル試着も可能になりました。さらに、2026年中に登場が予告されているAIスマートグラスの中核技術となることも発表されており、見るものすべてが検索対象になる未来を予感させます。
利用は完全無料で、海外旅行での翻訳や、日常の「これ何だろう?」という疑問をすぐに解決したい方に最適なアプリです。ただし、一部最新機能は特定のデバイスに限定される点には注意してください。
10位:Clarifai
Clarifaiは、AIモデルの開発からデプロイ、管理までをワンストップで提供する、開発者向けの統合AIプラットフォームです。単なるAPI提供にとどまらず、AI開発の全工程を効率化する機能が揃っています。
最大の強みは、エンドツーエンドのAIライフサイクル管理を実現している点。データ準備からモデルのトレーニング、本番環境へのデプロイ、そして運用までをシームレスに実行可能です。特に、2026年3月のアップデートで大幅に刷新されたCLI(コマンドラインインターフェース)は非常に強力です。model init serve deployというわずか3つのコマンドで、モデルを数分で本番環境へデプロイできるようになり、開発サイクルを劇的に高速化します。
料金プランは、個人開発者向けの無料プランから、月額$30〜のEssentialプラン、大規模開発向けのEnterpriseプランまで幅広く用意されています。まずは無料プランで強力な開発環境を試してみてはいかがでしょうか。
AIモデルのプロトタイピングから本番運用まで、一気通貫でスピーディーに進めたい開発チームやスタートアップにとって、非常に心強い選択肢となります。
画像認識AIを選ぶ前に知るべき注意点|APIの移行リスクと運用コストの罠
ここからは、画像 認識 ai 種類のおすすめ10選を紹介します。それぞれの特徴やメリットを詳しく解説していますので、導入検討の参考にしてください。
ベンダー都合のサービス終了・統合リスク
Google Cloud Vision AIは、Googleの強力な機械学習モデルを活用した高精度な画像認識APIです。開発者はこのAPIを呼び出すだけで、物体検出やOCR(文字認識)、顔検出といった高度な機能を自社のアプリケーションへ迅速に組み込むことができます。
主な強みは、事前学習済みの高精度なモデルと、ビジネスニーズに応える多彩な機能群です。例えば、SNS上の画像から自社ロゴを検出してブランド管理に役立てたり、ユーザー投稿コンテンツから不適切な画像を自動でフィルタリングしたりする活用が可能です。さらに、Vertex AIなど他のGoogle Cloudサービスと連携させることで、より複雑なシステムも構築できます。
2026年現在、単体のAPIとしての機能強化に加え、Google Cloud全体で推進される「AIエージェント」の「目」としての役割が重要視されています。最新のマルチモーダルAI「Gemini」との統合も進んでおり、画像の内容をより深く、文脈を理解した上での分析が実現しました。
料金は、機能ごとに毎月最初の1,000ユニットまで無料枠があり、超過分は従量課金制です。大量に利用するほど単価が下がるため、公式サイトで最新の料金を確認しましょう。
Googleの最新AI技術を手軽に利用したい開発者や、他のGoogle Cloudサービスと連携してデータ活用や業務自動化を推進したい企業に最適な選択肢です。
使えば使うほど膨らむ従量課金の罠
Amazon Rekognitionは、AWSが提供するフルマネージドの画像・動画分析サービスです。機械学習の専門家でなくても、APIを呼び出すだけで自社のアプリケーションやシステムに高度な画像認識機能を簡単に組み込めます。
主な特徴は、物体・シーン検出、顔分析、テキスト抽出(OCR)、不適切なコンテンツのフィルタリングといった多彩な機能を、必要な時に必要なだけ利用できる点にあります。さらに、自社製品や特定の機械部品など、独自の対象物を認識させたい場合は「カスタムラベル」機能で簡単に独自のAIモデルを学習させることも可能です。2026年3月の最新情報では、不適切なコンテンツ検出機能がアニメやイラストにも対応するなど精度が向上しました。一方で、人物の動線を追跡する「People Pathing」機能は2025年10月末で廃止されたため、この機能の利用を検討していた場合は注意が必要です。
料金は処理した画像の枚数などに応じた従量課金制で、無料利用枠も用意されています。開発リソースを抑えつつ、スピーディーに高度な画像分析機能を導入したい開発者や企業、ユーザー投稿コンテンツの管理を自動化したいプラットフォーム運営者などに特におすすめです。
ベンチマークのスコアを鵜呑みにする危険性
Microsoftが提供する総合的なAIサービス群「Azure AI」の中核をなす画像・動画解析サービスです。開発者がアプリケーションに高度な画像認識機能をAPI経由で容易に組み込める点が強みである。
主な特徴は、物体検出や顔検出はもちろん、日本語にも強い高精度なOCR(光学文字認識)や、独自の画像でモデルを学習させられる「Custom Vision」など、ビジネスニーズに応える多彩な機能を提供している点です。Microsoftの他のクラウドサービスとの連携もスムーズに行えます。
近年、機能が大幅に強化された「Image Analysis 4.0」が一般提供を開始しました。これにより、テキストと画像で高度な検索ができるマルチモーダル機能が利用可能です。ただし、旧API(v3.1以前)は2026年9月に廃止予定のため、利用中の方は早めの移行計画が必要になります。
料金はAPIの呼び出し回数に応じた従量課金制で、無料試用枠も用意されています。既存システムに画像解析機能を後付けしたい開発者や、書類のデジタル化、製品の検品自動化などを目指す企業に最適な選択肢です。
まとめ:最適な画像認識AIを選び、業務プロセス全体の自動化を実現しよう
ここからは、画像 認識 ai 種類のおすすめ10選を紹介します。それぞれの特徴やメリットを詳しく解説していますので、導入検討の参考にしてください。

