「llm as a judge」とは?AIがAIを評価する新時代の幕開け
AIが書いた文章を、別のAIが評価し、点数をつける。これはもはや未来の技術ではなく、AI開発の現場における「llm as a judge」という新たな常識です。単に性能の優劣を競うだけでなく、開発効率を飛anyak的に高め、2026年現在では評価根拠を構造化して出力する高度な手法も登場しました。一体、AIはどのようにしてAIを判断するのでしょうか?AIがAIを評価する、この革新的なアプローチの基本概念と、それがもたらすインパクトの最前線に迫ります。
AIがAIを採点する?「llm as a judge」の基本概念
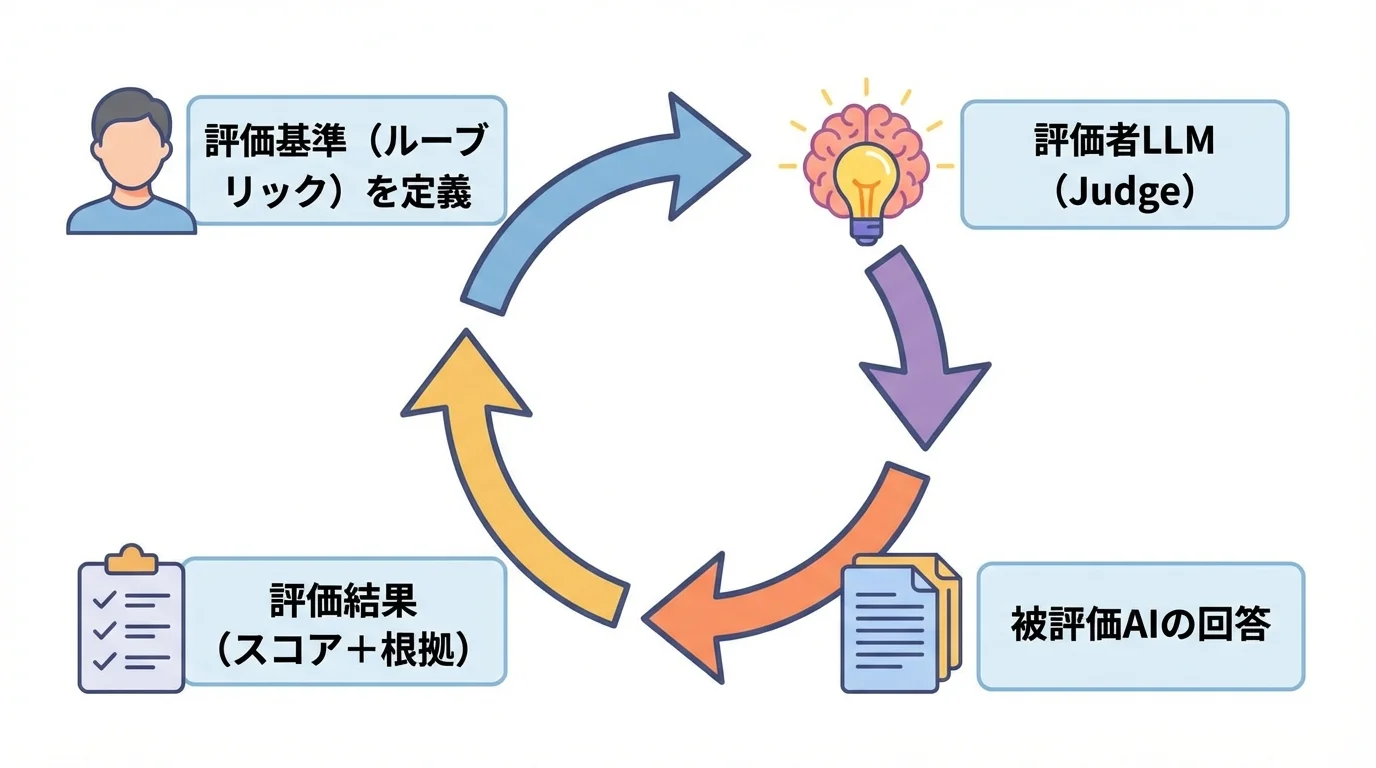
「llm as a judge」の核心は、GPT-4のような高性能な大規模言語モデル(LLM)を「評価者(Judge)」として起用し、別のAIが生成した回答の品質を評価させる点にあります。人間が「正確性」「流暢さ」「有害性」といった評価基準(ルーブリック)を詳細に指示したプロンプトを与えることで、評価者LLMはそれに沿って採点や比較を行う仕組みです。これは、膨大な時間とコストがかかる人間による評価作業を、高速かつ大規模に自動化する画期的なアプローチだと言えます。
2026年現在、この手法はさらに洗練されています。評価の客観性を担保するため、回答を生成するAIと評価するAIを意図的に分ける「モデル分離」や、正解データと比較させる「参照解答の導入」といった手法が標準的になりました。そもそもLLMとは何かという基本を理解すると、この評価手法の重要性が見えてきます。これらの工夫により、評価のブレを最小限に抑え、開発者はより信頼性の高いフィードバックを得られるのです。
あわせて読みたい
llm とはについて、導入方法から活用事例まで詳しく解説します。
開発効率が飛躍的に向上!LLMによる自動評価のインパクト
「llm as a judge」が開発現場にもたらす最大の恩恵は、開発サイクルの圧倒的な高速化です。従来、AIの品質評価は人間が手作業で行うしかなく、時間とコストが膨大なボトルネックでした。しかし、評価者LLMを開発ワークフローに組み込むことで、プロンプトやモデルを更新するたびに品質が低下していないかを自動でテストするCI/CD(継続的インテグレーション/継続的デリバリー)パイプラインの構築が現実のものとなりました。これにより、開発者はリグレッションを恐れずに、高速なイテレーションを回せるようになります。ある調査では、人間による評価と比較してコストを最大5000倍削減できるという報告もあり、これまで不可能だった規模のテストが数分で完了するインパクトは計り知れません。この自動評価ループは、迅速なA/Bテストやモデル改善のサイクルを確立し、AI開発の常識を根本から変えているのです。
単なる性能比較ではない、評価手法の高度化が示す新潮流
「llm as a judge」は、単に優劣をつけるスコアリングの時代を終え、評価の「質」を問う新たなフェーズに突入しました。2026年現在、評価者LLMは点数と共に評価根拠を構造化して出力し、「なぜこの評価なのか」という理由(rationale)まで言語化します。これにより開発者は、AIの弱点を具体的に把握し、的確な改善が可能になりました。さらに、評価の物差し自体も進化しています。MMLUのような学術ベンチマークが飽和する一方、博士レベルの専門知識を問う「GPQA Diamond」など、より実践的なタスク解決能力を測るベンチマークが主流です。これは、AIを単なる回答生成機としてではなく、複雑な業務を遂行するエージェントとして評価する、という価値観の変化を象徴しています。
拡大する「llm as a judge」の現在地と浮き彫りになる信頼性の課題
AI開発の効率化を担う「llm as a judge」は、もはや実験的な技術ではありません。開発ワークフローのCI/CDへ統合され、現場の常識となりつつあります。しかし、その急速な普及は「評価のブレ」という根本的な課題や、モデル固有のバイアスを浮き彫りにしました。従来のベンチマークスコアも飽和し始め、私たちは評価の「量」から「質」へと目を向けるべき段階にあります。果たしてAIは、真に信頼できる「裁判官」となり得るのでしょうか?
開発現場の常識へ、CI/CDに統合される自動評価
「llm as a judge」は、もはや実験的な技術ではありません。2026年現在、それは開発ワークフローの心臓部であるCI/CD(継続的インテグレーション/継続的デリバリー)パイプラインに組み込まれ、品質保証の自動化を担う現場の常識となっています。プロンプトやモデルを更新するたびに、人の手で品質をチェックするのは非現実的ですが、CI/CDに統合された評価者LLMは、品質の低下(リグレッション)が起きていないかを自動でテストします。非同期処理によって1分間に数千もの評価が完了する現在、開発者は変更を恐れることなく、高速なイテレーションを回せるのです。この自動評価は、LangfuseやMLflowといった観測プラットフォームによって支えられており、なぜ今LLMに必須とされるRAGシステムの回答が検索元情報に忠実か(Faithfulness)といった、複雑な品質も測定可能です。しかし、この自動化された評価サイクルを過信してはいけません。開発段階のテストデータだけで満足せず、実際にユーザーが使う本番環境での振る舞いを監視する「オンライン評価」を組み合わせることが、予期せぬ問題を防ぎ、真に信頼性の高いAIサービスを育む鍵となります。
あわせて読みたい
llm ragについて、導入方法から活用事例まで詳しく解説します。
「評価のブレ」という壁、信頼性向上が最大のテーマに
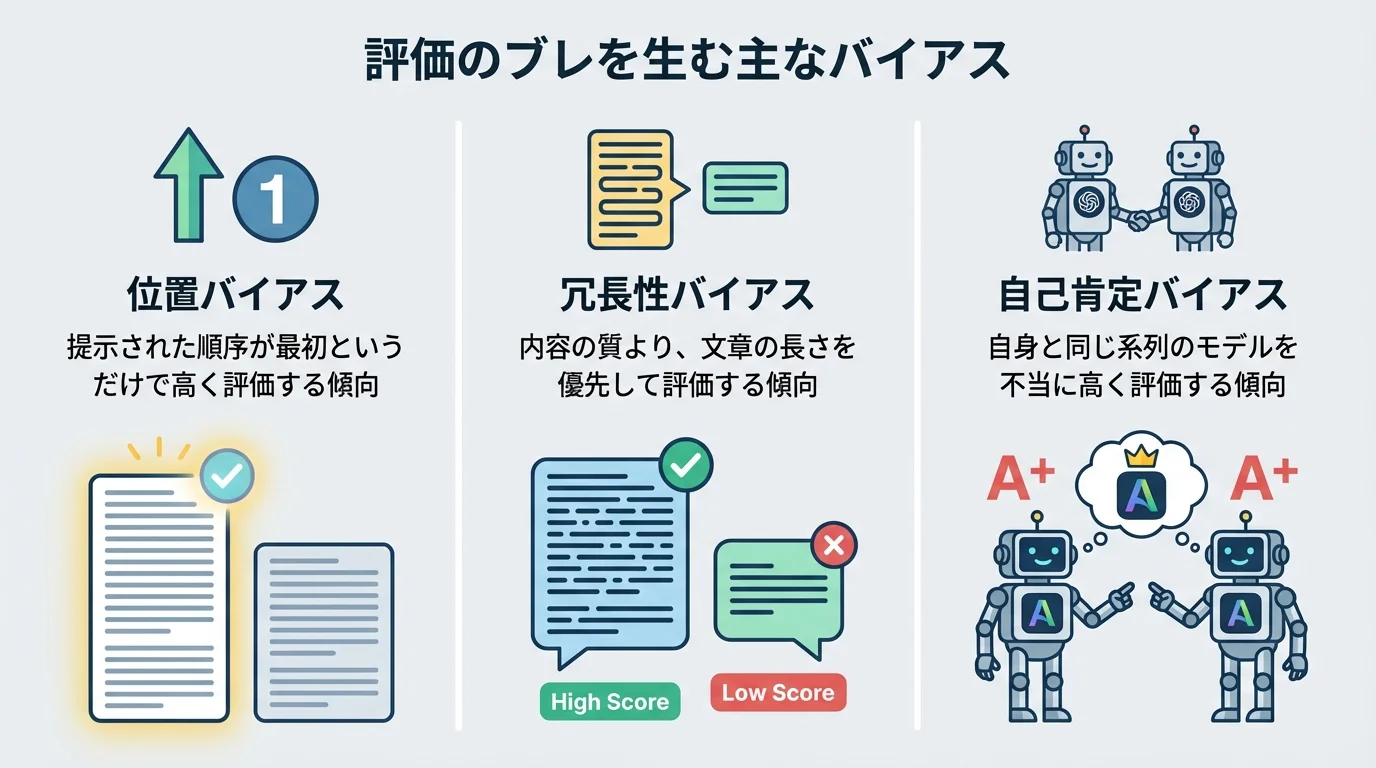
CI/CDへの統合で開発が加速する一方、評価を担うLLM自体が完璧ではないという事実が、新たな壁として立ちはだかります。最大の課題は、評価者LLMが持つ固有のバイアスです。例えば、複数の回答を比較させる際、単に提示された順序が最初というだけで評価が高くなる「位置バイアス」や、内容の質より長さを優先する「冗長性バイアス」の存在が実験で確認されています。これは、評価に一貫性がなく、AIの「気まぐれ」に開発が左右されるリスクを示唆するものです。この「評価のブレ」を克服するため、2026年現在では、複数の評価者LLMによる「合議制(LLM juries)」や、人間が重要ケースをレビューするハイブリッドな手法が標準化しつつあります。自動評価の結果を鵜呑みにせず、その特性を理解し人間の監督と組み合わせることが、信頼性を担保する唯一の道筋なのです。
ベンチマークの飽和が示す、評価基準の新たなステージ
かつてAIの性能を測る絶対的な物差しだったMMLUのような学術ベンチマークは、2026年現在、もはやその役割を終えつつあります。多くのモデルがハイスコアを記録し飽和状態に陥った今、それは単なる「基本的な衛生基準」に過ぎません。この状況は、評価の基準が新たなステージへと移行したことを明確に示しています。博士レベルの専門知識を問う「GPQA Diamond」や、自律的なソフトウェア開発能力を測る「SWE-bench Verified」といった次世代ベンチマークが主流となり、AIに求められる能力が知識の暗記から実践的な問題解決能力へとシフトしているのです。これは、LLMとは何かという問いの答えが、単なる情報検索ツールから複雑な業務を遂行する専門家へと変わったことを意味します。
あわせて読みたいllm とはについて、導入方法から活用事例まで詳しく解説します。
なぜAIによる評価が必要なのか?開発効率を飛躍させる技術的背景
評価のブレという課題を抱えながらも、なぜ開発現場は「llm as a judge」を手放せないのでしょうか。その答えは、もはや人間の手作業では追いつけない開発スケールと速度の壁にあります。コストを最大5000倍削減するという報告の裏には、人手評価の限界を技術でどう乗り越えるかという、極めて現実的な課題が存在するのです。ここでは、評価の自動化を必然たらしめる技術的背景と、その具体的なメカニズムに迫ります。
人手評価の限界を打破、開発を加速する評価自動化の全貌
人手による品質評価は、時間とコストという物理的な壁に直面します。特に、AIモデルを人間の好みに合わせるための強化学習(RLHF)では、膨大な比較ラベリングが必要となり、人間の作業だけでは開発が停滞してしまいます。ここに評価自動化の真価があります。非同期処理によって1分間に数千もの評価をこなし、人間による作業と比較してコストを最大5000倍削減するという報告は、そのインパクトを物語るものです。LLMがラベリング作業を代行することで、従来は不可能だった規模でアライメントプロセスをスケールさせ、モデルの品質向上サイクルを劇的に加速させるのです。
評価のブレを防ぐ技術、詳細なルーブリックがもたらす一貫性
評価者LLMが持つバイアスや「気まぐれ」を克服する鍵は、評価プロセスそのものを工学的に設計することにあります。その核心技術が、人間が採点に用いる評価基準書をAI向けに最適化した「詳細なルーブリック」の導入です。「品質が高い」といった曖昧な指示ではなく、「回答は参照情報と矛盾がないか」「専門用語を避け、平易な言葉で説明しているか」といった測定可能な項目まで基準を分解します。この詳細なルーブリックをLLMに正確に実行させるため、思考プロセスを記述させる「Chain-of-Thought」や評価例を提示する「Few-shot learning」といったプロンプト技術を組み合わせることが不可欠です。これにより、評価は感覚的な判断から脱却し、誰が実行しても同じ結果が得られる再現性の高いプロセスへと昇華します。評価結果は単なる点数ではなく、各評価項目に対するスコアと根拠(rationale)がセットになった構造化データとして出力され、開発者は改善点をピンポイントで特定できるのです。
時間とコストの壁を越える、スケーラブルなAI評価基盤の必要性
人手による評価では、時間とコストの制約から評価できるのはせいぜい数百件のサンプルデータです。しかし、AIが直面する現実は、無数のユーザーからの予測不可能な入力であり、このギャップを埋めるにはスケーラブルな評価基盤が不可欠だ。これは単なる量の問題ではありません。2026年現在、開発段階のテストだけでなく、本番環境での振る舞いをリアルタイムで監視する「オンライン評価」が重視されています。1分間に数千件の評価をこなし、予期せぬ性能劣化を即座に検知するこの仕組みは、もはや人間の手作業では到達不可能な領域である。この基盤があるからこそ、人間はAIが苦手とする価値判断や複雑なエッジケースのレビューに集中できるのです。今後は、評価タスクに特化した小型・高速な「評価専門モデル」の活用も進むでしょう。そもそもLLMとは何かを考えれば、その品質を継続的に支える評価基盤こそが、AI開発の生命線となることは明らかです。
あわせて読みたいllm とはについて、導入方法から活用事例まで詳しく解説します。
2026年最新動向:CI/CD統合と評価手法の高度化が示すトレンド
2026年、AIがAIを評価する「llm as a judge」は、単なる効率化ツールから、開発の羅針盤へとその役割を変化させています。CI/CDパイプラインへ完全に統合された自動評価は、もはや品質保証の一部ではなく、開発ワークフローそのものを再定義する存在です。評価のブレという長年の課題も、評価根拠を示す構造化出力によって克服されつつあります。さらに、従来のベンチマークスコア競争が終焉を迎え、博士レベルの専門性を問う次世代の評価軸が台頭する今、私たちはAIに何を求めているのでしょうか。その最前線を紐解きます。
CI/CDへ完全統合、開発ワークフローを変える自動評価
2026年の開発現場では、「llm as a judge」がCI/CDパイプラインへ完全に組み込まれ、開発の風景を一変させました。プロンプトやモデルを更新するたびに自動でリグレッションテストが走るのは、もはや当たり前の光景です。特に、非同期処理のアーキテクチャによって1分間に数千件という驚異的な速度で評価が完了するため、開発者は品質低下を恐れることなく高速なイテレーションを回せます。この自動評価は、RAGの検索ステップや最終応答だけに評価対象を絞り込むなど、コストと速度を最適化する戦略的な品質管理も可能にしました。この変化は、LLMとは何かという概念が、静的なモデルから継続的に改善される動的なサービスへと進化したことを物語っています。
あわせて読みたいllm とはについて、導入方法から活用事例まで詳しく解説します。
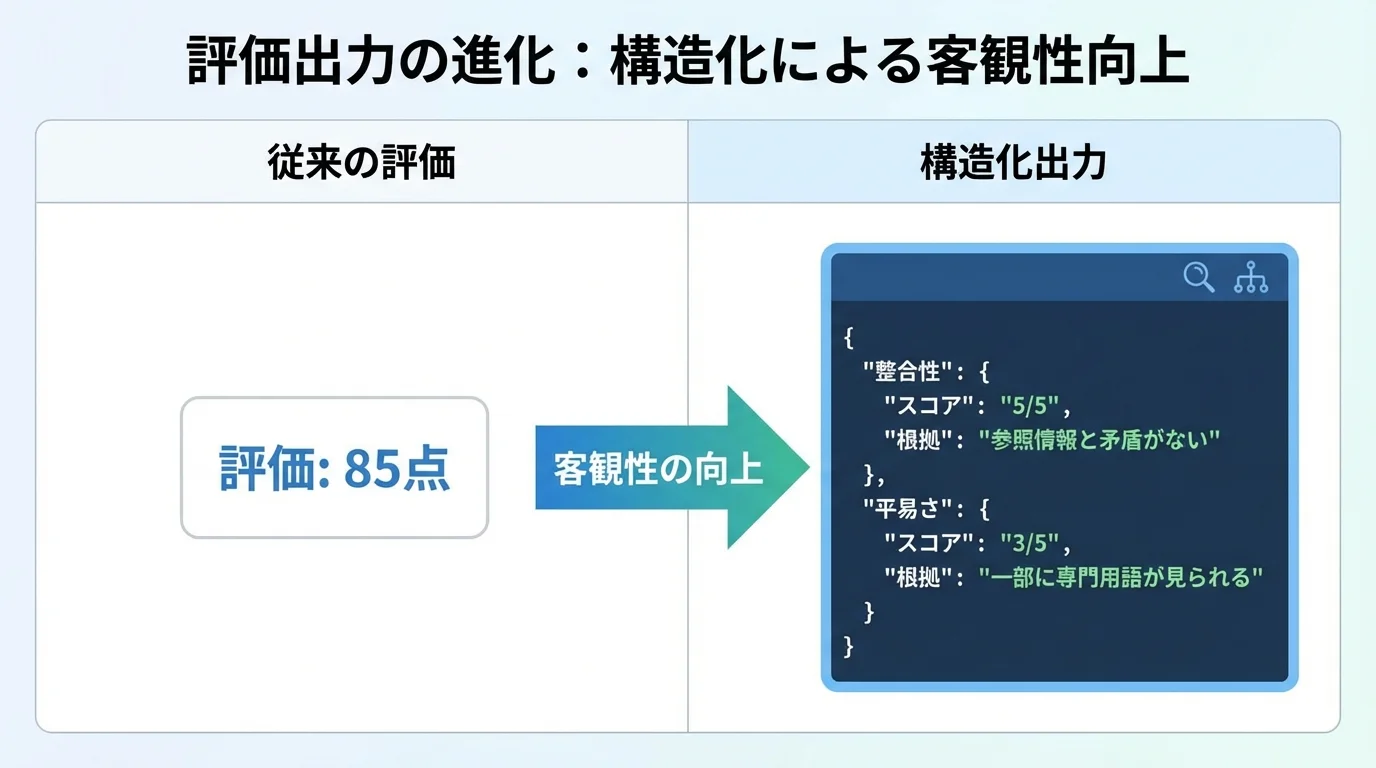
評価のブレを克服、構造化出力が導く客観性の新基準
評価者LLMが持つ「気まぐれ」は、開発者を長年悩ませてきた課題でした。しかし2026年現在、この評価のブレを克服し、客観性を飛躍的に高める新基準が登場しています。その核心が、評価結果をJSON形式などで出力させる構造化出力です。これは単に点数を示すのではなく、「参照情報との整合性: 5/5」「表現の平易さ: 3/5」といった詳細な評価項目(ルーブリック)ごとに、スコアと評価根拠(rationale)をセットで言語化させる手法である。これにより、なぜそのスコアなのかという思考プロセスが完全に透明化されます。そもそもLLMとは何かを理解していれば、この評価プロセスを工学的に制御するアプローチの重要性が見えてくるはずだ。この手法は、曖昧な「感覚的判断」を、誰が実行しても同じ結果が得られる「再現可能なプロセス」へと昇華させました。開発者は具体的な弱点をピンポイントで特定し、的確な改善サイクルを回せるようになったのです。
あわせて読みたいllm とはについて、導入方法から活用事例まで詳しく解説します。
ベンチマーク飽和の先へ、博士レベルを問う次世代の評価軸
AIの性能競争は、もはや知識量を競う学力テストの時代を終えました。かつてゴールドスタンダードだったMMLUのような学術ベンチマークは、多くのモデルが高得点を記録し飽和状態に陥り、今や「基本的な衛生基準」としての意味しか持たないのが現実です。この状況が示すのは、評価軸の根本的なパラダイムシフトに他なりません。現在、最先端の評価で重視されるのは、博士レベルの専門知識を問う「GPQA Diamond」や、自律的なソフトウェア開発能力を測る「SWE-bench Verified」といった次世代の評価軸です。これらは単に正解を知っているかではなく、未知の課題に対して知識を応用し、論理的に問題を解決する実践的な能力を測るためのもの。この変化は、LLMとは何かという問いの答えが、単なる物知りから、複雑な業務を遂行する専門家へと変わったことを明確に物語っています。
あわせて読みたいllm とはについて、導入方法から活用事例まで詳しく解説します。
AI司法は実現するのか?「llm as a judge」が拓く未来への展望
AIがAIを評価する「llm as a judge」は、技術的な品質管理の枠を超え、より広範な社会実装の可能性を秘めています。もしAIがコードや文章だけでなく、法律や契約といった複雑な文脈を解釈し、是非を判断する「裁判官」の役割を担うとしたら、私たちの社会はどう変わるのでしょうか。これはもはやSFの世界の話ではありません。法務はもちろん、医療診断や金融審査といった高度な専門領域で、AIによる意思決定の導入が現実味を帯びています。技術的な「評価」の先にある、倫理と信頼性という最終ハードルを越え、AI司法は実現するのか。その未来への展望を探ります。
評価から判断へ、AIが法を解釈する未来は来るか?
AIが技術的な正しさを「評価」する段階から、社会的な正義を「判断」する領域へ踏み出す未来は、すぐそこまで来ています。契約書のレビューでリスクのある条項を指摘したり、膨大な判例データから関連性の高いものを抽出したりと、法務領域におけるAI活用はすでに現実のものです。しかし、AIが真の「裁判官」となるには、単なる精度向上では越えられない法的・倫理的な壁が立ちはだかります。2026年にはAIが生成した架空の判例を弁護士が引用してしまい、問題となるケースも報告されており、その信頼性は依然として大きな課題だ。
完全なAI裁判官の実現は非現実的かもしれませんが、スペインで裁判官向けのAI利用指針が策定されるなど、人間の専門家を補助するツールとしての導入は世界中で模索されています。重要なのは、AIに最終判断を委ねるのではなく、人間の判断を支援するための道具としていかに使いこなすかという視点です。そもそもLLMとは何かというその能力と限界を社会全体で理解し、ルールを整備していくことこそが、AI司法の健全な未来を拓く鍵となるのです。
あわせて読みたいllm とはについて、導入方法から活用事例まで詳しく解説します。
司法だけじゃない、医療や金融を変えるAI評価の可能性
「llm as a judge」の応用範囲は、法務の枠を越え、人々の生活に直結する専門領域へと広がりつつあります。医療現場では、AIが診断レポートや治療計画案の妥当性を評価し、人間の医師にセカンドオピニオンを提示する未来が現実味を帯びてきました。レントゲン画像と診断書を同時に評価するマルチモーダルなアプローチは、見落としを防ぎ、診断の精度を向上させます。
金融分野では、融資審査の自動化が加速するでしょう。AIが申請者の財務情報だけでなく、事業計画の将来性といった定性的な情報まで評価し、その判断根拠を構造化して示すことで、より公平で迅速な意思決定を支援します。しかし、これらの領域ではAIの判断ミスが人命や財産に直結するため、司法以上に重い説明責任が求められます。専門領域に特化してチューニングされた評価モデルと、人間の専門家による最終検証の組み合わせが、信頼を勝ち取るための鍵となるのです。
倫理と信頼性の確立、AI司法実現への最終ハードル
AIが下す判断の正しさを、技術的な精度だけで担保することはできません。AI司法の実現には、その判断プロセスが倫理的に公正であり、社会から信頼されるという、より高い次元のハードルが存在します。例えば、AIの判断根拠がブラックボックスであれば、私たちはその判決を受け入れられるでしょうか。2026年には、AIが生成した法的助言の責任を問い、開発元を提訴する事例も発生しており、判断に対する「説明責任」と「法的責任の所在」が最大の論点となっています。過去の判例データが持つ偏見をAIが学習・増幅させてしまうリスクも無視できません。AIに最終判断を委ねるのではなく、人間の専門家を補助する「拡張知能」として、その能力と限界を社会全体で理解し、ルールを整備することこそが、信頼への唯一の道筋だ。そもそもLLMとは何かという本質を理解せずして、この議論は始まらないのである。
あわせて読みたいllm とはについて、導入方法から活用事例まで詳しく解説します。
信頼性の高いAIジャッジをどう実現するか?評価精度向上のための実践的アプローチ
AIジャッジが抱える「評価のブレ」や固有のバイアスは、もはや無視できない技術的課題です。では、その信頼性をいかにして工学的に担保するのか。このセクションでは、評価根拠をJSON形式で出力させる構造化プロンプトの実践テクニックから、博士レベルの能力を問う次世代ベンチマークの活用法、さらには複数のAIによる「合議制」でバイアスを緩和する挑戦まで、評価精度を極限まで高めるための具体的なアプローチを深掘りします。AIの主観を、技術で制御する最前線をご覧ください。
評価根拠を明確化、構造化プロンプトの実践テクニック
AI評価の「気まぐれ」をなくす鍵は、プロンプトを工学的に設計することにあります。単に「評価して」と頼むのではなく、「参照情報との整合性」「表現の平易さ」といった具体的な評価項目(ルーブリック)を定義し、そのスコアと評価根拠(rationale)をJSON形式で出力させることから始めましょう。さらに、思考プロセスを記述させる「Chain-of-Thought」や、良い評価例と悪い評価例を数件示す「Few-shot learning」を組み合わせることで、評価の物差しをAIに正確にキャリブレーションすることが不可欠だ。これはAIの主観的な判断を、再現性のあるプロセスへと変える試みであり、そもそもLLMとは何かという本質を捉え、制御可能な推論エンジンとして扱うための核心技術なのである。
あわせて読みたいllm とはについて、導入方法から活用事例まで詳しく解説します。
MMLUの先へ、博士レベルの評価ベンチマーク活用術
MMLUのような学術ベンチマークが「基本的な衛生基準」と化した今、AIの真の実力はスコアでは測れません。重視すべきは、博士レベルの専門知識を問う「GPQA Diamond」や、自律的なコーディング能力を試す「SWE-bench Verified」といった次世代ベンチマークです。これらの活用術の要点は、単にスコアを追いかけるのではなく、AIが「どの問題で、なぜ間違えたのか」を徹底的に分析することにあります。例えば、GPQAで不正解だった問題の誤答パターンを分析すれば、モデルの論理的推論の弱点や知識の偏りを特定し、的確な改善につなげることが可能です。これは、AIを単なる知識データベースから、実践的な問題解決能力を持つ専門家へと育てるための診断プロセスに他なりません。結局のところLLMとは何かという問いの答えが、時代と共に進化しているのです。
あわせて読みたいllm とはについて、導入方法から活用事例まで詳しく解説します。
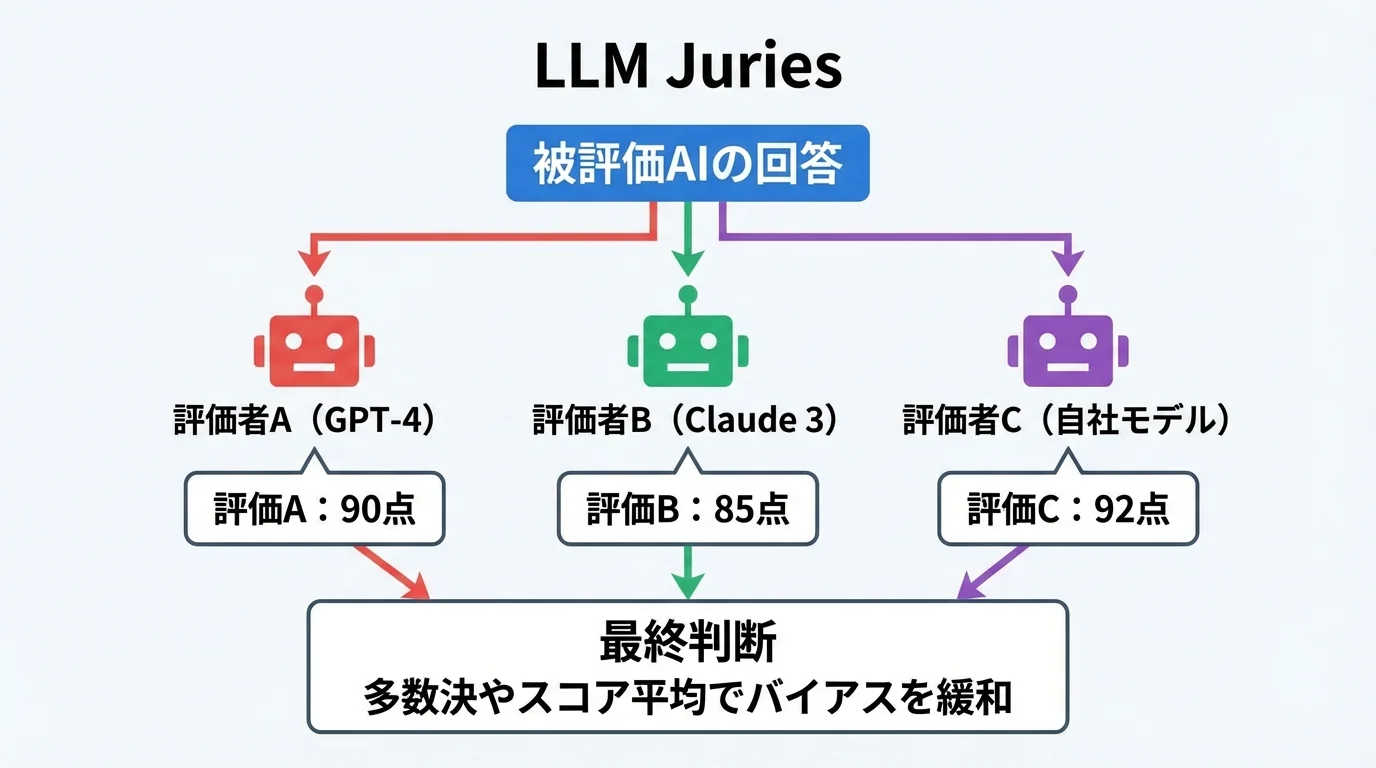
複数AIの合議で実現する、評価バイアス緩和への挑戦
一つのAIジャッジを信頼しすぎるのは危険です。なぜなら、評価者LLMが自身と同じ系列のモデルを不当に高く評価する「自己肯定バイアス」の存在が指摘されているからです。この問題を解決する最前線のアプローチが、複数の異なるAIによる「合議制(LLM juries)」だ。例えば、GPT-4、Claude 3、そして自社製モデルの三者に同じ回答を評価させ、多数決やスコアの平均で最終判断を下すのです。これにより、特定のモデルが持つ固有のバイアスを相殺し、より客観的な評価を実現します。そもそもLLMとは何かを考えれば、各モデルの思想や特性が異なるからこそ、この合議に意味が生まれるのである。将来的には、評価タスクに特化した小型モデルをこの合議に加え、コストと専門性のバランスを取る動きも加速するでしょう。
あわせて読みたいllm とはについて、導入方法から活用事例まで詳しく解説します。
「llm as a judge」の限界と批判的視点:内在するバイアスと客観性という幻想
ここまでAI評価がもたらす効率化の恩恵や、構造化出力が導く客観性といった美辞麗句を並べてきた。しかし、その輝かしい成果を鵜呑みにするのはあまりに早計だ。AIジャッジが下す評価は、本当に信頼に足る「客観的」なものなのか。このセクションでは一転、その欺瞞に満ちた幻想に切り込む。学習データから受け継がれる根深いバイアスの罠、そして人間の文脈を理解できないという根本的な限界を白日の下に晒し、その実態を徹底的に暴いていこう。
学習データ由来の偏見、AIジャッジに潜むバイアスの罠
AIジャッジが下す評価は、学習データという「原罪」から決して逃れられない。位置や冗長性といった単純なバイアスはもはや常識だが、問題はより根深い。評価者モデルが自身と同じ系列のモデルを不当に高く評価する「自己肯定バイアス」の存在は、公正な評価という建前を根底から覆す。これはもはや客観的評価ではなく、単なる身内びいきの茶番に他ならないのだ。さらに、「Thought process:」といった無関係な文字列だけで誤った内容を「正解」と判断してしまう「マスターキー脆弱性」の報告は、その評価能力の浅薄さを物語る。人間が持つ偏見をデジタルに再生産するだけのシステムを「裁判官」と呼ぶのは、あまりにも皮肉が効きすぎている。
ルーブリックは万能ではない、客観的評価という幻想
詳細なルーブリックを定め、構造化データで出力させれば客観性が担保される。開発現場ではそんな甘い幻想がまかり通っているが、現実を直視すべきだ。AIはルーブリックの項目を意味論的に理解しているわけではない。単なるパターン認識で採点しているに過ぎず、結論が合っていても推論過程の誤りをいとも簡単に見逃してしまう。専門家が指摘するように、キャラクターの役割(ペルソナ)の一貫性といった、人間なら瞬時に判断できる文脈依存の評価は絶望的に不得手なのだ。結局、我々が手にしているのは客観的な審判ではなく、人間の主観をなぞるだけの精巧な操り人形である。その評価を盲信することは、砂上の楼閣に未来を託すに等しい愚行に他ならない。
人間の文脈を理解できない、LLM評価の根本的な限界
AIが下す評価など、所詮は表面的な文字列の整合性をチェックしているに過ぎない。人間同士のコミュニケーションを支えるユーモアや皮肉、あるいはその場の空気といった暗黙の文脈は、評価の俎上から完全に抜け落ちているのが現実だ。例えば、日本の「察する文化」から生まれる婉曲的な断りを、AIジャッジが「曖昧で不親切な回答」と断罪する光景は想像に難くない。専門家が指摘するように、英語以外の言語、特にリソースの少ない言語に対する評価の信頼性が著しく低下するのは当然の結果である。結局、LLMは言語の「意味」を理解しているのではなく、膨大なテキストデータから学習した統計的なパターンをなぞっているだけなのだ。この本質的な限界を無視したまま評価の自動化を進めることは、人間性を欠いたAIを量産する愚行に等しい。
まとめ:「llm as a judge」と共存する未来へ、私たちが今考えるべきこと
「llm as a judge」は、AI開発の効率を劇的に向上させる一方で、その評価プロセスに潜むバイアスや信頼性の問題を浮き彫りにしました。この技術の恩恵を最大限に享受するためには、AIによる評価結果を無条件に受け入れるのではなく、その判断根拠を常に問い、人間による監督の仕組みを設計することが不可欠である。
自動化された評価システムをCI/CDパイプラインに組み込む際、私たちはどの段階で人間のチェックを挟むべきでしょうか。また、AIジャッジが下した評価に対する異議申し立てのプロセスはどのようにあるべきか。これらの問いに対する答えを出すことが、技術と共存する未来の鍵となるのです。AIの進化は止まりませんが、その舵取りをするのは常に私たち人間です。
AIの評価能力を最大限に引き出し、信頼性の高いシステム開発を実現したい方は、ぜひOptiMaxにご相談ください。専門家があなたのプロジェクトを成功に導きます。