なぜ今ローカルLLMが注目されるのか?3つの大きな理由
ChatGPTなどのクラウドAIが便利な一方で、なぜ今あえて手元のPCで動かす「ローカルLLM」が注目を集めているのでしょうか。その背景には、2026年現在、オープンソースLLMが商用モデルに匹敵する性能へと進化したことがあります。本セクションでは、データを外部に出さない高いセキュリティ、API費用からの解放、そして自社データで自由に調整できるカスタマイズ性という、今ローカルLLMが選ばれる3つの大きな理由を具体的に解説します。

データが外部に漏れない高いセキュリティ
ChatGPTのようなクラウドAIに業務情報を入力することに、抵抗を感じる方も多いはずです。入力データが学習に使われる可能性や、意図せぬ情報漏洩のリスクは、特に機密情報を扱う企業にとって無視できない問題です。ローカルLLMの最大のメリットは、このセキュリティリスクを根本から解消できる点にあります。すべての処理が手元のPCや自社サーバー内で完結するため、顧客データ、設計図、非公開のソースコードといった機密情報が外部に送信されることはありません。これにより、これまでAI導入が難しかった金融や法務といった分野でも、安心して生成AIとは何かという技術の恩恵を受けられるようになります。
あわせて読みたい
生成AIについて、基礎知識から活用事例・比較・導入方法まで包括的に解説するガイドです。
商用モデルに迫るオープンソースLLMの性能向上
ローカルLLMが注目されるもう一つの大きな理由は、オープンソースモデルの劇的な性能向上です。かつては「オープンソースは商用に劣る」というイメージがありましたが、2026年現在、その構図は大きく変わりつつあります。MetaのLlama 4やGoogleのGemma 3といった高性能モデルが登場し、特定のタスクでは商用モデルに匹敵、あるいはそれを凌駕する性能を示すことも珍しくありません。MoE(Mixture of Experts)のようなアーキテクチャの進化は、LLMとは何かという技術の可能性を広げ、限られたPCスペックでも効率的に動作するモデルを増やしました。これにより、高価なAPIを使わずとも、手元で強力なAI機能が利用できる時代になったのです。
あわせて読みたい
llm とはについて、導入方法から活用事例まで詳しく解説します。
API費用を削減し、自由にカスタマイズ可能
クラウドAIサービスを利用する上で、APIの従量課金は大きな懸念点です。特に、大量のテキスト生成や分析を日常的に行う場合、コストが膨らみ、自由な試行錯誤を妨げる要因になりかねません。ローカルLLMは、このコストの制約から解放してくれます。一度環境を構築すれば、API利用料を気にすることなく、何度でもプロンプトのテストやモデルの評価を実行できるのです。さらに、オープンソースモデルを自社のデータで微調整(ファインチューニング)し、専門用語や社内ルールに特化した独自のAIを構築できる点も大きな魅力です。例えばOllamaの「Modelfile」機能を使えば、モデルの構成をコードで管理でき、チーム内での環境再現も容易になります。
セキュリティ・コスト・カスタマイズ性で選ぶ!ローカルLLM導入のメリット
前章で触れたローカルLLMの3つの魅力は、単なる理想論ではなく、2026年現在、具体的なビジネスメリットとして明確になっています。ここでは、情報漏洩リスクを根本から断ち切る安全性、APIの従量課金から解放される経済性、そして特定業務に特化させる独自データでの微調整という、3つの強力な利点を一つずつ詳しく解説します。自社の状況に最適なAI活用法を見つけるためのヒントがここにあります。
情報漏洩リスクを回避!自社データは自社内で管理
クラウドAIサービスを利用する上で最大の障壁となるのが、情報漏洩リスクです。入力したデータが意図せず学習に利用されたり、外部へ流出したりする可能性は、特にコンプライアンスを重視する企業にとって看過できません。ローカルLLMは、この問題を根本から解決します。全ての処理が自社の管理下にあるPCやサーバー内で完結するため、顧客情報・財務データ・非公開のソースコードといった機密情報が外部ネットワークに出ることは一切ありません。これにより、例えば社内文書のみを学習データとしたRAG(検索拡張生成)システムを構築し、完全にセキュアな環境でナレッジ検索や要約を行うといった、生成AIとは何かという技術の安全な活用が可能になるのです。データの主権を自社で完全に掌握できること、それがローカルLLMが選ばれる決定的な理由です。
あわせて読みたい生成AIについて、基礎知識から活用事例・比較・導入方法まで包括的に解説するガイドです。
APIの従量課金なし!コストを気にせず試行錯誤
クラウドAIサービスを利用する際の大きな壁が、APIの従量課金です。特に、最適なプロンプトを見つけるためのチューニングや、大量のデータを処理するアプリケーション開発では、呼び出し回数が膨大になり、コストが予測不能になることも少なくありません。ローカルLLMは、このランニングコストの制約を完全に撤廃します。一度環境を構築してしまえば、何千回でもプロンプトをテストしたり、Llama 4やGemma 3といった複数のモデルの性能を心ゆくまで比較検証したりすることが可能です。例えば、なぜ今LLMに必須とされるRAG(検索拡張生成)システムの構築においても、API費用を気にすることなく、自社データとの最適な連携方法を無制限に試行錯誤できるのです。
あわせて読みたい
llm ragについて、導入方法から活用事例まで詳しく解説します。
特定業務に特化!独自データでモデルを微調整
ローカルLLMの真価は、自社の独自データでモデルを微調整(ファインチューニング)できる点にあります。市販のクラウドAIでは対応しきれない専門用語や社内独自の規定を学習させることで、まるでベテラン社員のように文脈を理解する「自社専用AI」を構築できます。汎用的なLLMとは何かという知識に加え、自社ナレッジを注ぎ込むことで、問い合わせ対応の自動化や技術文書の要約といったタスクの精度が劇的に向上するのです。特にOllamaの「Modelfile」機能を使えば、モデルの構成をコードで管理できるため、チーム内での環境再現も容易になります。Qwen3のような高性能モデルを土台に、自社に最適化されたAIを作り上げられる点が、最大のカスタマイズメリットです。
あわせて読みたいllm とはについて、導入方法から活用事例まで詳しく解説します。
2026年最新動向:Llama 4やGemma 3など高性能オープンソースモデルの台頭
ローカルLLMが実用的な選択肢となった背景には、モデル自体の劇的な性能向上と、それを手軽に動かす実行ツールの進化があります。2026年現在、Metaの「Llama 4」やGoogleの「Gemma 3」といった新世代オープンソースモデルは、特定のタスクで商用AIに匹敵、あるいはそれを凌駕する能力を示し始めました。さらに、Ollamaが牽引するマルチモーダル機能や、LM Studioの大型アップデートなど、エコシステム全体が急速に成熟しています。本セクションでは、ローカルLLMの最前線を走るこれらの技術動向を詳しく掘り下げていきます。
商用モデルに匹敵する高性能オープンソースLLMの登場
2026年、オープンソースLLMは「無料で使える二番手」という評価を完全に覆しました。MetaのLlama 4やGoogleのGemma 3はもちろん、AlibabaのQwen 3.5、さらにはOpenAI初のオープンウェイトモデル「GPT-OSS」など、特定のベンチマークで商用モデルを凌駕する性能を持つモデルが次々と登場しています。この飛躍を支えているのが、MoE(Mixture of Experts)のような新アーキテクチャです。必要な専門家(Expert)部分だけを活性化させることで、少ない計算リソースでも巨大モデルに匹敵する性能を引き出せるようになりました。こうしたLLMとは何かという技術自体の進化が、これまで高スペックなマシンを要求した高性能AIを、より身近な存在に変えたのです。
あわせて読みたいllm とはについて、導入方法から活用事例まで詳しく解説します。
Ollamaが牽引するマルチモーダル機能の進化
ローカルLLMの進化は、もはやテキスト処理の領域だけにとどまりません。その象徴が、テキスト以外のデータも扱うマルチモーダル機能への対応です。この流れを強力に牽引しているのが、手軽さで人気の実行ツール「Ollama」です。2026年1月、Ollamaはついにテキストからの画像生成機能を試験的にサポートしました。これにより、これまで高価なクラウドAPIに頼ることが多かった画像生成が、完全にセキュアなローカル環境で実行可能になったのです。将来的には画像編集機能の追加も視野に入っており、生成AIとは何かという技術の可能性を、手元のPCからさらに広げています。
あわせて読みたい生成AIについて、基礎知識から活用事例・比較・導入方法まで包括的に解説するガイドです。
LM Studioなど実行ツールの大型アップデート
高性能モデルの能力を最大限に引き出すための、実行ツールの進化も目覚ましいです。特に2026年に入り、「LM Studio」は大規模なアップデートを敢行しました。目玉は2月にリリースされた新機能「LM Link」で、外出先の非力なノートPCから自宅の高性能マシン上で動くLLMをリモート利用できます。これにより、場所を選ばずに強力なAI環境へアクセス可能になりました。一方で、シンプルさで人気のOllamaも、自律的にタスクをこなすAIエージェントと生成AIの違いとはを理解する上で重要な、開発を支援する機能を追加するなど進化を続けています。さらに、単一ファイルでLLMを動かせるLlamafileも登場し、ローカルLLMを試すハードルは劇的に下がっています。
あわせて読みたい
ai エージェント 生成 ai 違いについて、導入方法から活用事例まで詳しく解説します。
Ollamaのマルチモーダル対応も!進化が止まらない実行ツールの最新機能
ローカルLLMの進化は、もはやテキスト処理の領域に留まりません。その最前線を走るのが、手軽さで人気の実行ツール「Ollama」によるマルチモーダル対応です。2026年1月には、ついにテキストからの画像生成機能をサポートし、高価なクラウドAPIを介さずに、完全にセキュアなローカル環境で画像処理を完結できるようになりました。本セクションでは、この画期的な新機能の詳細から、将来的な画像編集機能の可能性まで、実行ツールの進化を具体的に掘り下げていきます。
画像生成も可能に!Ollamaのマルチモーダル対応
Ollamaの進化はテキスト生成だけではありません。2026年1月、ついにテキストからの画像生成機能が試験的にサポートされました。これにより、これまでStable Diffusion WebUIのような専門ツールや高価なクラウドAPIに頼っていた画像生成が、ollama runコマンドのような手軽さで、完全にオフラインの環境で実行可能になったのです。デザインの試作品や未公開の製品コンセプトなど、機密性の高いビジュアルを扱う際も、情報漏洩のリスクを心配する必要はありません。この機能は、生成AIとは何かという技術の応用範囲を、セキュリティが重視される現場へと大きく広げる画期的な一歩です。
生成AIについて、基礎知識から活用事例・比較・導入方法まで包括的に解説するガイドです。
クラウドAPI不要!ローカルで完結する画像処理
Ollamaによる画像生成機能がもたらす最大の利点は、DALL-E 3などの高価なクラウドAPIへの依存から解放されることです。デザインのプロトタイプ作成や資料用のイラスト生成において、これまでAPIの利用回数や月額費用は常に頭の痛い問題でした。ローカル環境であれば、このコストを気にせず、納得がいくまで何百枚でも試行錯誤が可能になります。さらに重要なのがセキュリティ面です。未公開の製品コンセプトや顧客データを含む図版など、機密性の高いビジュアルを扱う業務では、データを外部サーバーに送信するリスクを完全に排除できます。これにより、これまで導入が難しかったデザイン部門や企画部門でも、安全に生成AIとは何かという技術の恩恵を受けられるようになります。
あわせて読みたい生成AIについて、基礎知識から活用事例・比較・導入方法まで包括的に解説するガイドです。
画像編集も視野に!進化を続けるLLM実行ツール
Ollamaが実現した画像生成は、ローカルLLMの進化における始まりに過ぎません。開発ロードマップでは、将来的にはローカル環境での画像編集機能の追加も視野に入っており、デザイン業務のあり方を根本から変える可能性を秘めています。進化はOllamaだけに留まらず、他の実行ツールも目覚ましいアップデートを続けています。例えば「LM Studio」は、2026年2月に画期的な「LM Link」機能をリリースしました。これを使えば、外出先の非力なノートPCから自宅の高性能マシンにリモート接続し、場所を選ばずに強力なAI環境を呼び出せます。こうしたツールの機能拡充は、ローカルLLMのエコシステム全体が成熟し、より高度で多様なAI活用が手元で可能になる未来を示しています。
機密情報の分析にも!データが外部に出ないローカルLLMの活用事例
ローカルLLMの理論的なメリットは理解できても、具体的な活用イメージが湧かない方もいるかもしれません。このセクションでは、データを外部に出さないという強みを最大限に活かした、3つの実践的な活用事例を紹介します。社内ナレッジの安全な検索・要約から、個人情報を含むデータ分析、非公開コードのレビューまで、AIによる業務効率化をセキュアに実現する方法を見ていきましょう。
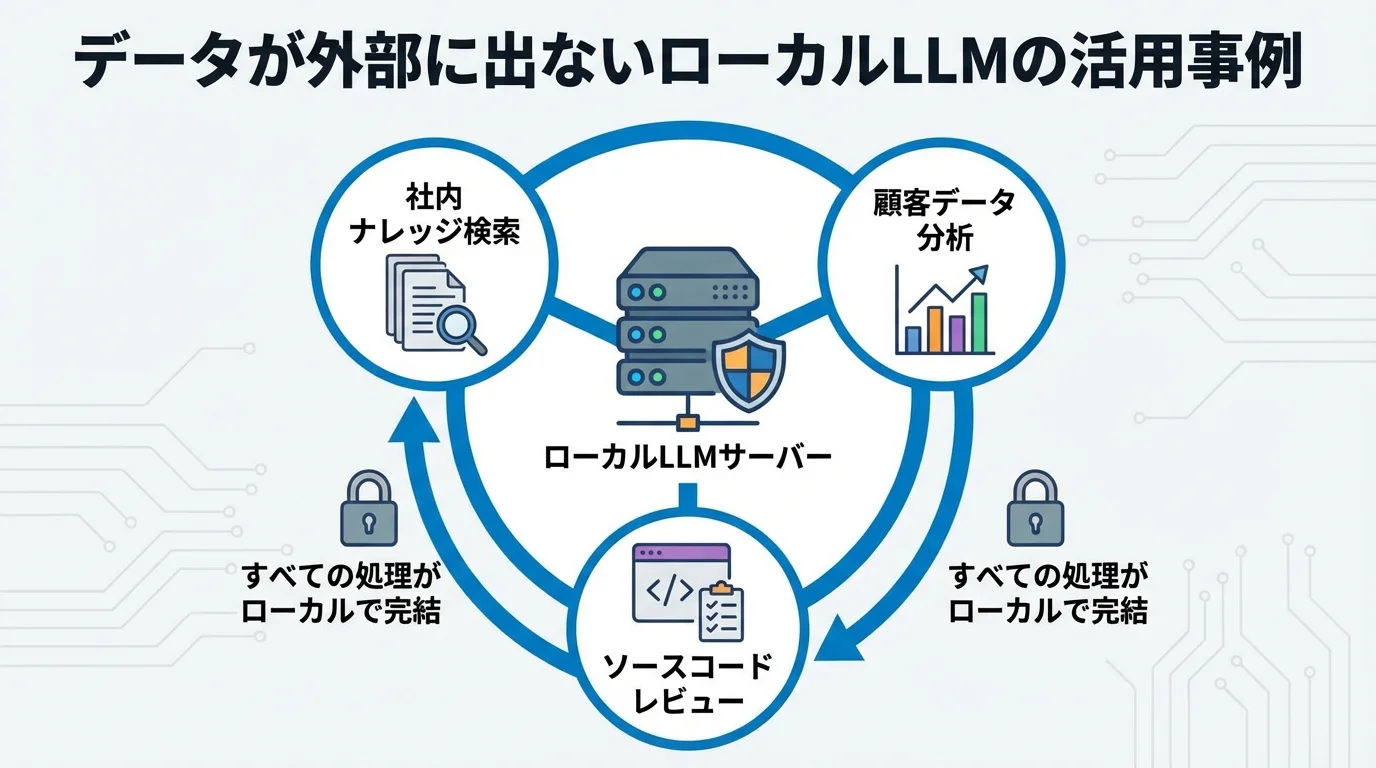
社内規定や議事録のセキュアな検索・要約
「あの規定はどこだっけ?」「先週の会議の決定事項は?」こうした情報検索に費やす時間は、業務の大きなボトルネックです。だからといって、機密情報である社内規定や議事録をクラウドAIにアップロードすることは、情報漏洩のリスクから許容されません。このジレンマを解決するのが、ローカルLLMです。RAG(検索拡張生成)という技術を活用し、社内サーバー上のドキュメントだけを参照するセキュアなナレッジ検索システムを構築できます。LM Studioなどのツールを使えば、PDFやドキュメントファイルを読み込ませるだけで、まるでベテラン社員に質問するように「〇〇の経費精算ルールを教えて」と自然言語で対話することが可能になります。これにより、情報検索の時間を劇的に短縮し、他社はどう使ってるのか気になるような、先進的なナレッジ活用が実現します。
あわせて読みたい
生成 ai 活用 事例について、導入方法から活用事例まで詳しく解説します。
顧客データなど個人情報を含む市場分析
顧客アンケートの自由回答や購買履歴といった貴重なデータも、個人情報保護の観点からクラウドAIでの分析を躊躇する企業は少なくありません。ローカルLLMは、このジレンマを解決します。自社の管理下にあるサーバー内ですべての処理が完結するため、顧客データを一切外部に送信することなく、安全に深層的な分析を実行できます。例えば、大量のレビューコメントから顧客の感情を読み解き、製品改善のヒントを抽出したり、問い合わせログを要約して新たなニーズを発見したりすることが可能です。APIコストを気にせず様々な角度から試行錯誤できるため、これまで見過ごされてきたインサイトを発見し、データに基づいたマーケティング戦略を加速させます。これは、クラウドサービスでは実現が難しい、セキュアな環境でのChatGPTデータ分析の活用法と言えるでしょう。
あわせて読みたい
ChatGPT データ分析 活用について、導入方法から活用事例まで詳しく解説します。
非公開ソースコードのレビューやリファクタリング
ソフトウェア開発において、非公開のソースコードは最も重要な機密情報の一つです。これをクラウドAIにアップロードしてレビューを依頼するのは、情報漏洩のリスクが非常に高く、多くの企業で禁止されています。ローカルLLMは、この課題を解決します。自社のネットワーク内で完結するため、開発中の新機能や独自アルゴリズムのコードを、外部に漏らすことなくAIにレビューさせることが可能です。Qwen3-Coderのようなコーディングに特化したモデルを使えば、単なる文法チェックに留まらず、潜在的なバグの指摘やパフォーマンス改善のためのリファクタリング案を、完全にオフラインで得られます。基本的なLLMとは何かという技術が、このように専門的な開発支援にも応用され、セキュアな環境で開発サイクルの高速化とコード品質の向上が両立するのです。
あわせて読みたいllm とはについて、導入方法から活用事例まで詳しく解説します。
初心者でも安心!ローカルLLM環境構築を始めるための第一歩
ローカルLLMに興味はあっても、「環境構築は専門知識が必要で難しそう」とためらっていませんか?2026年現在、その心配はもう不要です。OllamaやLM Studioといった非常に手軽な実行ツールが登場したおかげで、数ステップで自分だけのAI環境を構築できるようになりました。このセクションでは、ツールの導入から使いたいLLMモデルのダウンロード、そして始める前に確認すべき推奨PCスペックまで、初心者がつまずかないための第一歩を具体的に解説していきます。
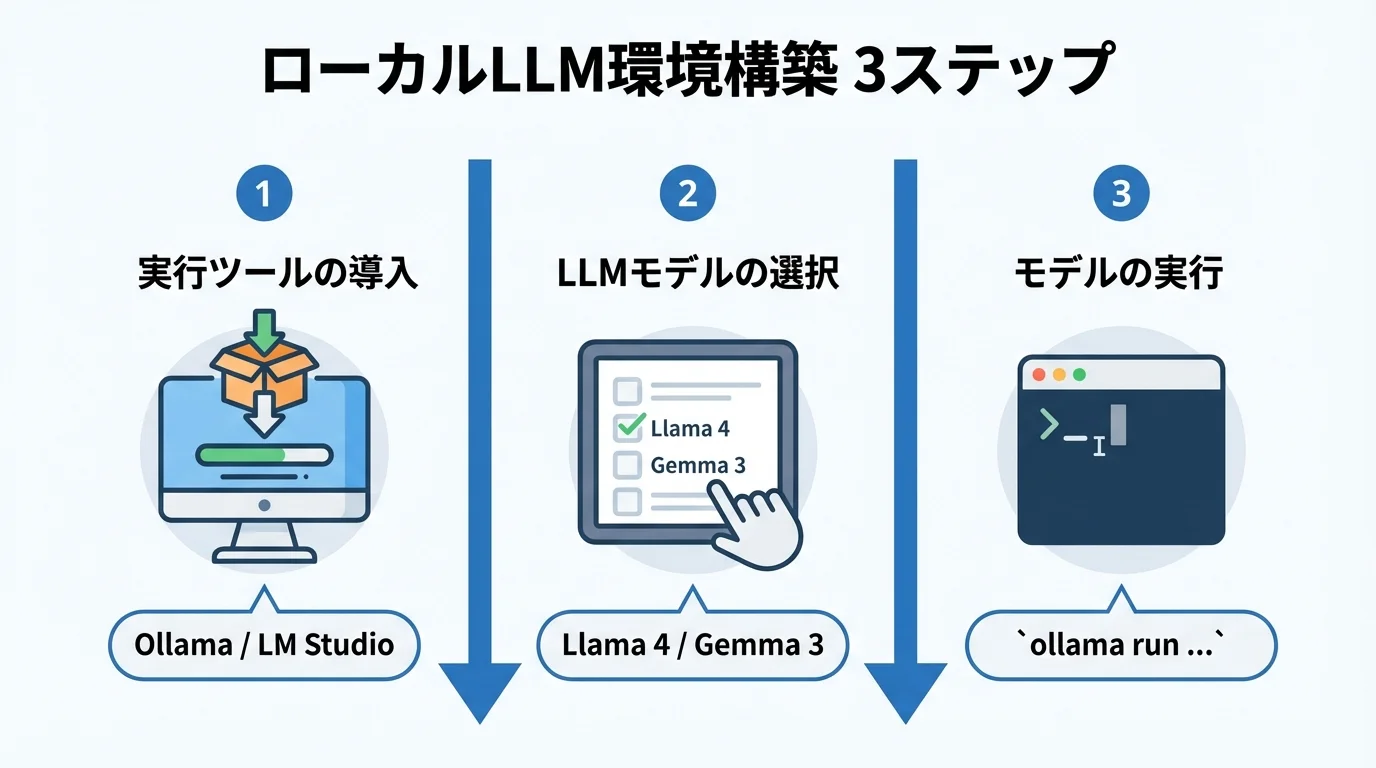
まずはOllamaなど実行ツールを導入
ローカルLLM環境構築の第一歩は、驚くほど簡単です。かつては専門的な知識が必要でしたが、2026年現在では「Ollama」や「LM Studio」といった優れた実行ツールが登場し、誰でも手軽に始められるようになりました。
特に推奨したいのが、デファクトスタンダードとなりつつあるOllamaです。公式サイトからお使いのOS(Windows, Mac, Linux)に合ったインストーラーをダウンロードし、実行するだけで基本的なセットアップは完了します。コマンド操作に慣れていない方には、GUIが充実していて直感的に扱えるLM Studioも良い選択肢です。これらのツールを使えば、複雑な設定をすることなく、数クリックで自分だけのAI環境の土台を築けます。まずは、この強力な生成AIとは何かを動かすためのツールをPCにインストールすることから始めてみましょう。
あわせて読みたい生成AIについて、基礎知識から活用事例・比較・導入方法まで包括的に解説するガイドです。
使いたいLLMモデルを選んでダウンロード
実行ツールの準備が整ったら、次はいよいよAIの「脳」となるLLMモデルを選んでダウンロードします。Ollamaならターミナルで ollama run llama3 のようなコマンドを1行入力するだけ。これだけで、モデルのダウンロードからチャットの開始までが自動で完了します。GUIが中心のLM Studioでは、アプリ内で使いたいモデルを検索してダウンロードボタンをクリックするだけで準備は万全です。
初めての方は、まず7B(70億パラメータ)程度の比較的小さなモデルから試すのがおすすめです。PCへの負荷が少なく、手軽に動作を体験できます。モデルには様々なサイズや量子化(軽量化)レベルがあり、日本語性能もモデルによって異なります。どのモデルが良いか迷ったら、【2026年最新】生成AIおすすめ10選などの比較記事を参考に、自分の目的に合ったものを見つけてみましょう。
あわせて読みたい生成AI おすすめ10選を、Chatbot Arena(arena.ai)のベンチマークスコアと実務での使い勝手を軸に徹底比較。ChatGPT、Claude、Gemini、Grokなど主要サービスの特徴・料金・用途別の選び方を解説します。
始める前にチェック!推奨PCスペック
ローカルLLMを快適に動かす鍵は、PCのスペック、特にグラフィックボードが搭載するVRAM(ビデオメモリ)の容量にあります。モデルの規模が大きくなるほど、より多くのVRAMが必要になるため、事前に自分のPC環境を確認しておくことが重要です。
入門としては、VRAMが8GB〜12GBあれば、7B(70億パラメータ)クラスのモデルを快適に動かせます。より高性能な13Bクラス以上のモデルを試すなら、16GB以上のVRAMが中級レベルの目安です。もしVRAMが足りなくても、モデルを軽量化する「量子化」という技術を使えば動作させることが可能なため、諦める必要はありません。まずはご自身のPCスペックを確認し、無理なく動かせるモデルから始めてみましょう。
導入前に知っておくべきローカルLLMのデメリットと注意点
ここまでローカルLLMのメリットを並べてきたが、バラ色の未来ばかりではない。このセクションでは、導入後に「こんなはずではなかった」と頭を抱えることがないよう、あえて不都合な真実を突きつける。見落としがちな高スペックPCという初期投資、それを維持する専門人材の必要性、そしてクラウドAPIに劣る性能の限界。甘い期待だけで飛びつく前に、LLMをローカルで動かすことの本当のコストと現実を直視してほしい。

見落としがちな高スペックPCという初期投資
「API費用が無料」という言葉に踊らされてはいけない。その裏には、数十万円単位の初期投資という現実が待ち構えている。2026年現在、7Bを超える中規模モデルを快適に動かすには、最低でもVRAM 16GB以上のGPUが必須。これは高性能ゲーミングPCに相当し、価格は30万円から50万円を超えることもザラだ。スペックをケチったPCでは、結局使い物にならない速度しか出ず、投資が無駄になるのが関の山。その数十万円でクラウドAPIがどれだけ使えるか、冷静に計算してみるべきだ。本当に機密性の高いデータでなければ、大抵のケースでクラウドの方が費用対効果は高い。安易な節約思考が、結果的に最も高くつく典型例である。
環境構築と保守を担う専門人材の必要性
Ollamaをインストールすれば終わり、などと本気で思っているなら、今すぐ考えを改めるべきだ。本当の地獄は、その後の保守・運用フェーズにある。新しいモデルの検証、ライブラリの依存関係地獄、セキュリティパッチの適用、そして現場からの「なぜか動かない」という問い合わせ対応。これらを片手間で処理できると考えるのは、あまりに楽観的すぎる。結局、インフラとLLMの両方に精通した高価な専門人材をアサインしなければ、システムはすぐに陳腐化し、誰も触れない「AI置物」と化すのがオチだ。その人材の採用コストと人件費を考えれば、クラウドAPIを素直に使った方がよほど安上がりなケースは多い。運用コストを具体的に試算できない体制なら、最初から手を出すべきではない。
クラウドAPIに劣る応答速度と性能の限界
「ローカルLLMはサクサク動く」という甘い期待は、最初のプロンプト入力で裏切られる。クラウドAPIが瞬時に応答を返すのに対し、ローカル環境では数秒の沈黙が続くのが現実だ。この致命的な応答速度の差は、チャットボットのような対話型アプリケーションではユーザー体験を根本から破壊する。性能も同様。VRAMの制約から、ローカルで動かせるモデルは必然的にモデル規模が小さい。これは単に知識量が少ないだけでなく、GPT-4oが解けるような複雑な指示を理解する能力や、推論の深さが決定的に劣ることを意味する。リアルタイム性と最高性能が必須の業務なら、ローカルに固執するのは時間と金の無駄に他ならない。
まとめ
この記事では、なぜ今ローカルLLMが注目されているのか、その理由から具体的な始め方までを解説してきました。セキュリティを確保しながらAPIコストを気にせず、自社データに合わせてカスタマイズできる点が最大の魅力だ。Llama 3をはじめとする高性能モデルや、Ollamaのような手軽な実行ツールの登場で、導入のハードルは劇的に下がりました。もちろん、マシンスペックの要求や運用知識が必要といったデメリットも存在します。まずはこの記事を参考に、Ollamaを使って手元のPCで小さなモデルを動してみることから、ローカルLLMの世界に足を踏み入れてみてください。本格的な業務活用や最適なモデル選定でお悩みなら、ぜひOptiMaxにご相談ください。