画像認識AIとは?生成AIとの融合で進化する最新技術を解説
画像認識AIは、単に画像の内容を識別するだけの技術ではありません。近年は生成AIと融合し、人間と対話しながら複雑な分析を行う「マルチモーダルAI」へと進化を遂げています。実際、2026年1月のAIベンチマーク(LMSYS Arena)では、Googleの「Gemini 3 Flash」がVision Score 79.0という高スコアを記録しました。このセクションでは、画像認識AIの基礎知識から、こうした最先端技術の動向までをわかりやすく解説します。最適なAIを選ぶために、まずは技術の全体像を掴みましょう。
画像認識AIの基本と物体検出などの主要機能
画像認識AIは、画像から特定の情報を抽出・識別する技術群の総称です。その主要な機能は多岐にわたり、ビジネス課題に応じて使い分けられます。
- 物体検出 (Object Detection): 画像内の物体の位置と種類を特定する技術です。自動運転での車両検知や、工場の生産ラインにおけるAI画像認識検査に応用されています。
- 画像分類 (Image Classification): 画像全体が何であるかを「犬」「猫」のように分類する機能で、商品画像の自動仕分けなどに活用できます。
- 光学文字認識 (OCR): 画像内の文字を読み取り、テキストデータに変換します。請求書や領収書のデータ入力自動化に不可欠な技術です。
- 顔認識 (Face Recognition): 画像から人物の顔を検出し、個人を特定する機能。セキュリティシステムの認証などで利用が広がっています。
これらの基本機能を理解することが、自社の課題に最適なAIを選ぶ第一歩となります。より詳しい【2025年】画像認識AIの種類とはも参考に、どの機能が必要か検討してみてください。
あわせて読みたい
画像 認識 ai 種類について、導入方法から活用事例まで詳しく解説します。
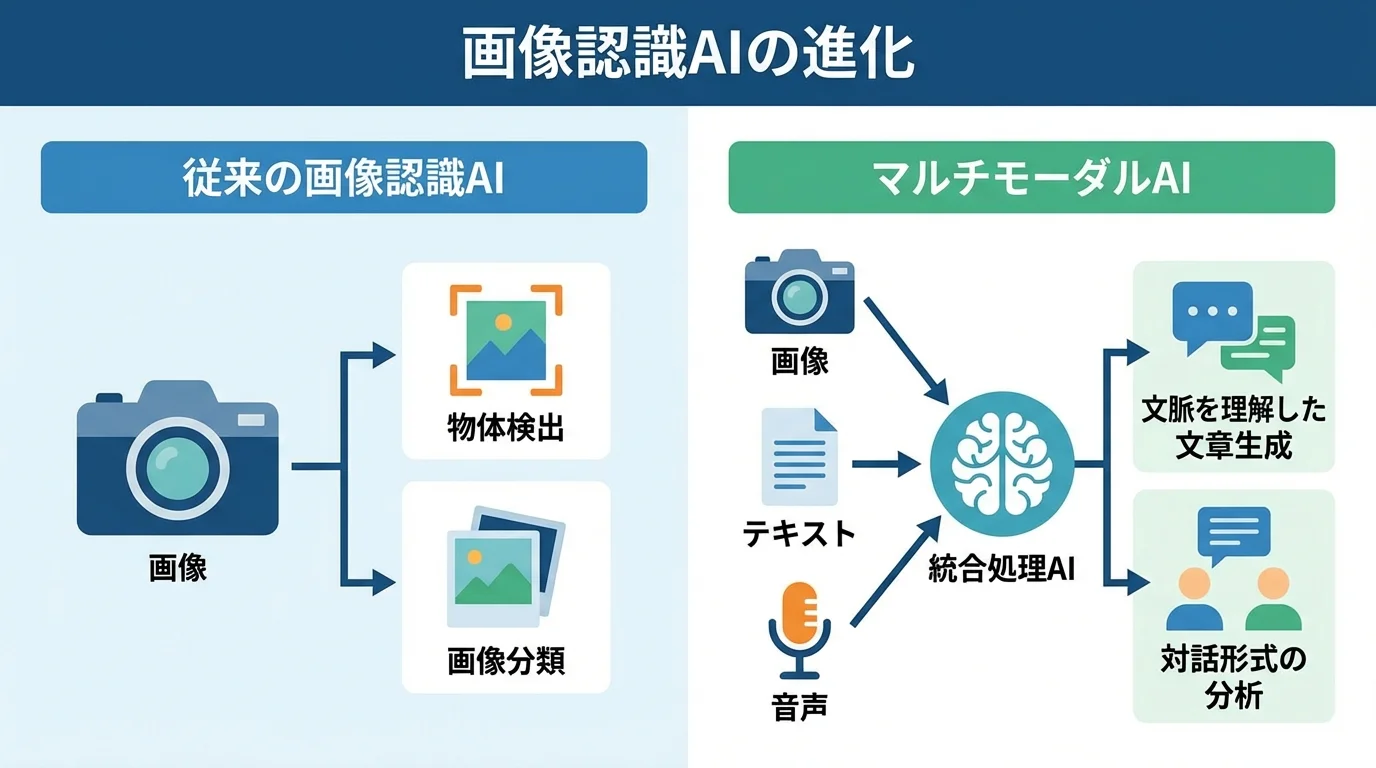
生成AIとの融合で進化するマルチモーダルAIとは
従来の画像認識AIが画像という単一の情報(モーダル)しか扱えなかったのに対し、マルチモーダルAIはテキスト、画像、音声といった複数の情報を統合的に処理できます。この技術は生成AIと融合することで、単に「犬」と分類するだけでなく、「公園の芝生でフリスビーを追いかけるゴールデンレトリバー」のように、画像全体の文脈を理解した文章を生成することが可能になりました。
さらに、画像を見ながら「この製品の傷はどこですか?」と質問すると、AIが該当箇所を指摘しながらテキストで回答するなど、対話形式での分析が実現します。この能力は、単なる認識を超えた「理解」の領域であり、進化する画像認識AIの仕組みとは、まさにこの点にあります。GoogleのGeminiシリーズのように、画像とテキストを組み合わせた複雑な指示に対応できるモデルが、今後の主流となるでしょう。
あわせて読みたい
画像 認識 ai 仕組みについて、導入方法から活用事例まで詳しく解説します。
【2026年最新】Geminiが拓く画像認識の新時代
2026年の画像認識技術を語る上で、GoogleのGeminiシリーズは欠かせない存在です。LMSYS Arenaの2026年3月時点のリーダーボードでは、Gemini 3 FlashがVision Score 79.0という高評価を獲得し、その実用性の高さを示しました。このモデルの強みは、100万トークンという広大なコンテキストウィンドウにあります。これにより、長大な動画や複雑な技術文書を読み込ませた上で、画像に関する対話形式の分析が可能になるのです。この進化は、生成AI時代の画像認識AIとは何かを具体的に示しており、AI選定の基準が単なる認識精度から、文脈理解や対話能力へと移り変わっていることを物語っています。
あわせて読みたい
画像 認識 ai とはについて、導入方法から活用事例まで詳しく解説します。
画像認識AIの選び方と比較ポイント【2025年版】|Gemini連携や精度を軸に解説
ここからは、画像 認識 ai 比較のおすすめ10選を紹介します。それぞれの特徴やメリットを詳しく解説していますので、導入検討の参考にしてください。
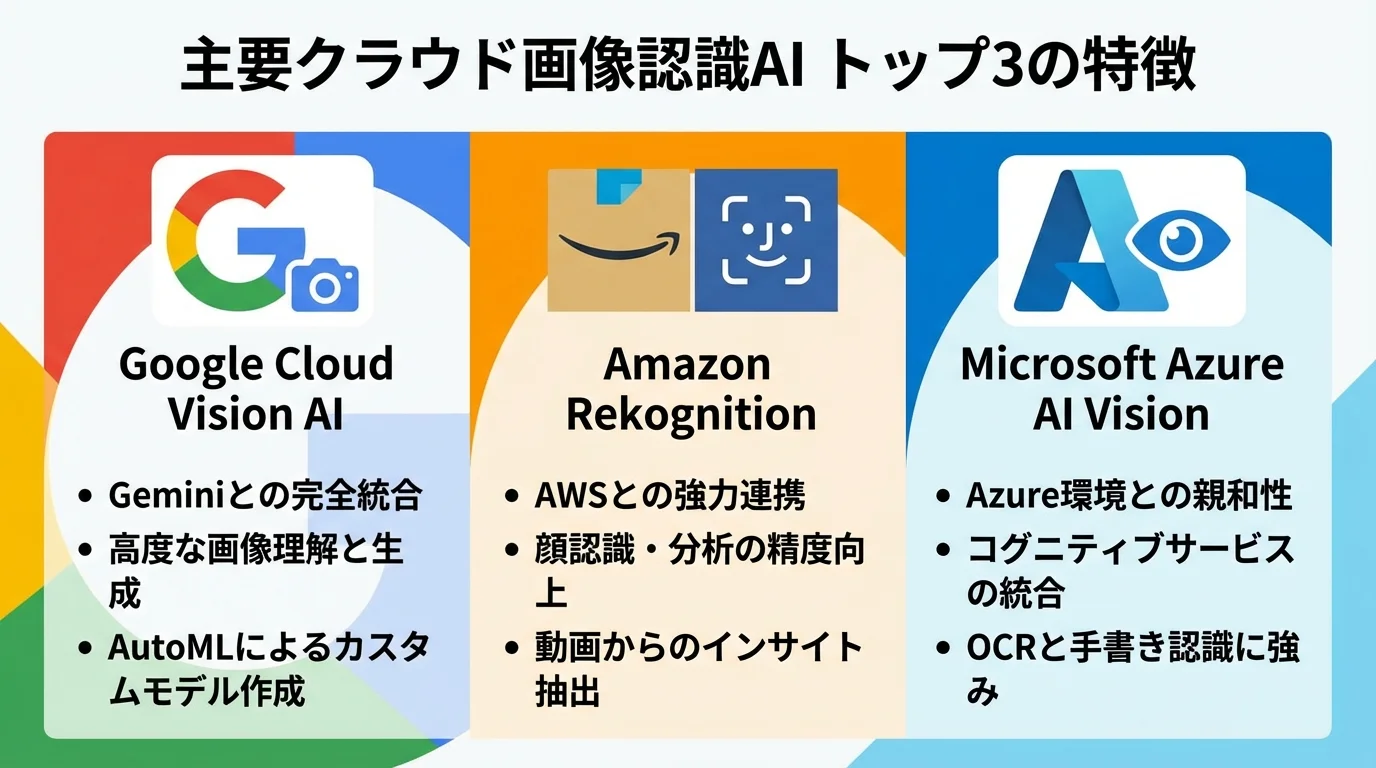
1位:Google Cloud Vision AI
Google Cloud Vision AIは、Googleの膨大なデータセットで学習した、世界最高クラスの精度を誇る画像認識AIです。ラベル検出やOCR(光学文字認識)といった基本的な機能はもちろん、現在はGoogleの統合AIプラットフォーム「Vertex AI」の中核技術として、常に最先端の能力を提供し続けています。
その最大の強みは、生成AI「Gemini」との完全な統合にあります。これにより、単に画像内の物体を識別するだけでなく、「この画像は何を表しているか?」といった複雑な質問への回答や、状況を説明する文章の生成まで可能です。2026年には、AIの性能指標であるLMSYS Arenaで「Gemini 3 Flash」がトップクラスのスコアを記録するなど、その性能は客観的にも証明されています。料金は機能単位の従量課金制で、毎月1,000ユニットまでの無料枠があるため、小規模なテストから始めやすい点も魅力でしょう。
常に最高の認識精度を求める開発者や、Google Cloudの他サービスと連携して大規模なAIシステムを構築したい企業に最適な選択肢です。
2位:Amazon Rekognition
Amazon Rekognitionは、AWSが提供する深層学習を活用した高精度な画像・動画分析サービスです。物体やシーンの検出、顔分析、テキスト認識、不適切コンテンツの検出など、1つのAPIで多彩な機能を利用できる点が大きな強み。専門的な機械学習の知識がなくても、開発者はアプリケーションに高度な画像認識機能を容易に組み込めます。
2026年3月時点では、画期的な新機能の発表はありませんが、ラベル検出の強化や動画分析の高度化など、継続的なモデルの精度向上が図られています。料金は分析量に応じた従量課金制で、無料利用枠も用意されているため、コストを抑えながらスモールスタートが可能です。
既にAWS環境でシステムを構築している企業や、サーバーレスアーキテクチャで画像処理システムを迅速に開発したい場合に最適な選択肢となります。
3位:Microsoft Azure AI Vision
Microsoftが提供する、開発者向けのクラウドAIサービスです。REST APIやSDKを通じて、画像や動画から情報を抽出する高度な機能をアプリケーションに手軽に実装できます。
主な強みは、物体検出・文字認識(OCR)・人物検出・キャプション生成などを1つのAPIで呼び出せる統合性の高さにあります。さらに、2024年に強化されたマルチモーダル埋め込み機能は102の言語に対応しており、グローバルな画像検索システムの構築も可能である点も大きな特徴です。
最新情報として、古いバージョンのAPI廃止が進んでいる点には注意が必要です。Computer Vision API v3.1以前のバージョンは2026年9月13日に廃止されるため、利用中の方は早めに最新のv3.2へ移行しましょう。料金は月5,000トランザクションまで無料のFreeプランと、利用量に応じた従量課金制が用意されています。
すでにAzure環境を導入している企業や、多様な機能を組み合わせて独自のサービスを開発したい方に最適な選択肢となります。
4位:Hugging Face Hub
「AI版GitHub」とも称される、世界最大級のオープンソースAIプラットフォームです。2026年時点で200万以上のAIモデルや50万以上のデータセットが公開されており、最先端の画像認識モデルを誰でも手軽に試すことができます。世界中の開発者や企業が参加する活発なコミュニティも大きな強みでしょう。
2026年には、モデルリポジトリとは別に大容量ファイルを柔軟に管理できる新機能「Storage Buckets」が追加されました。また、中核ライブラリである「Transformers」が約5年ぶりにv5へとメジャーアップデートされ、推論の高速化や外部ツールとの連携がさらに容易になっています。
個人利用は無料から始められ、Proプランは月額$9から利用可能です。最新のオープンソースモデルをいち早く試したい開発者や、自社データでAIモデルをファインチューニングしたい研究者・企業に最適なプラットフォームです。
5位:Roboflow
Roboflowは、コンピュータビジョンモデルの開発を加速させるエンドツーエンドプラットフォームです。データの準備からアノテーション、モデルのトレーニング、デプロイまで、開発に必要な全工程を一つの環境でシームレスに行える点が最大の特徴。直感的なGUI操作が可能で、専門知識が少なくても画像認識AIの開発を始められます。
特に、2026年1月にリリースされた最新の物体検出モデル「YOLOv26」へ即座に対応するなど、常に最先端の技術を迅速に取り入れている点は大きな強みです。また、ドラッグ&ドロップで処理の流れを構築できる「Workflows Builder 2.0」も実装され、より複雑なタスクも直感的に設計できるようになりました。無料のStarterプランからエンタープライズプランまで用意されており、プロジェクトの規模に応じて選択できます。データセットの準備からモデルのデプロイまで、開発サイクル全体を効率化したいチームや、最新モデルをいち早く試したい開発者におすすめです。
6位:Clarifai
第6位は、AIモデルの開発からデプロイ、運用までを一気通貫で管理できる統合プラットフォーム「Clarifai」です。単一の機能に特化するのではなく、画像、動画、テキスト、音声といった多様なデータを扱うAIモデルのライフサイクル全体をサポートします。
強みは、画像認識だけでなく、自然言語処理(NLP)や生成AIなど、異なる種類のAIモデルを自由に組み合わせ、独自のAIワークフローを構築できる柔軟性にあります。これにより、例えば「画像からテキストを抽出し、その内容を要約して別の言語に翻訳する」といった複雑なタスクも実現可能です。近年のアップデートでは料金体系がシンプルな従量課金制に移行し、最低月額料金なしで高度な機能にアクセスできるようになりました。
自社のデータを使ってカスタムモデルを開発したい、あるいは複数のAI機能を連携させた高度なアプリケーションを構築したい開発者や企業に最適なプラットフォームです。
7位:OpenCV
OpenCVは、画像処理やコンピュータビジョン開発で世界的に利用されているオープンソースライブラリです。豊富な機能が無料で利用できるため、研究開発から商用アプリケーションまで幅広いシーンで活用されています。
最大の強みは、物体検出や機械学習、3Dビジョンなど網羅的な機能が無料で使える点にあります。C++やPythonなど多様な言語に対応しており、開発の自由度が非常に高いのも特徴です。2026年現在、次期メジャーバージョン「OpenCV 5.x」への移行が進み、AI機能が大幅に強化されました。特にDNNモジュールでは最新AIモデルへの対応が向上し、AWS Graviton 4といった最新プロセッサ向けのハードウェア最適化も進んでいます。
コストをかけずに独自の画像認識AIを開発したい研究者やスタートアップ、また特定のエッジデバイス上で高速処理を実現したい企業に最適な選択肢です。
8位:Google Lens
Google Lensは、スマートフォンをかざすだけで目の前のモノを認識し、関連情報を検索してくれる無料のビジュアル検索ツールです。テキストの翻訳やコピー、動植物の特定、似ている商品の検索など、日常生活のあらゆる場面で役立つ機能がGoogleアプリやカメラに統合されています。
最大の特徴は、誰でも直感的に使える手軽さとその多機能性です。2026年現在、AIモデル「Gemini」との連携が強化され、Googleマップ上でカメラをかざすだけで建物を認識し、道案内する機能などが追加されました。また、年内に登場予定のAI搭載スマートグラスとの連携も発表されており、ハンズフリーでのリアルタイム翻訳や情報検索が現実のものとなりつつあります。
料金は完全無料で、追加費用は一切かかりません。専門的なAPI利用ではなく、日常生活や旅行先で画像認識AIの便利さを手軽に体験したい個人ユーザーに最適なツールです。
9位:ABBYY Vantage
ABBYY Vantageは、請求書や契約書といった多様な文書からデータを高精度に抽出する、インテリジェント・ドキュメント・プロセッシング(IDP)プラットフォームです。ローコード/ノーコードの直感的な操作性が特徴で、専門家でなくてもAIによる業務自動化を実現できます。
強みは、150種類以上もの業界・業務に特化した事前学習済み「AIスキル」です。マーケットプレイスから必要なスキルを選ぶだけで、すぐに高精度なデータ抽出を開始できます。また、RPAやBPMなど既存システムとの連携もスムーズに行えるため、業務プロセス全体の自動化を推進します。
2026年1月にメジャーアップデートされた「Vantage 3.0」では、生成AIとの直接統合が大きな注目点です。Azure OpenAIと連携し、プロンプト(指示文)ベースで柔軟なデータ抽出が可能になりました。加えて、新しいリアルタイム分析ダッシュボードにより、プロセスのボトルネックを特定し、投資対効果(ROI)の向上を支援します。
AI開発の専門家がいない部門でも、大量の帳票処理を自動化し、業務効率を大幅に改善したい企業に最適なソリューションです。
10位:TensorFlow Hub
TensorFlow Hubは、Googleが提供する再利用可能な訓練済み機械学習モデルの総合リポジトリです。専門家が構築した高性能なモデルを、数行のコードで自身のアプリケーションに組み込むことができます。
最大の強みは、転移学習を簡単に行える点にあります。これにより、ゼロからのモデル開発にかかる時間と膨大な計算コストを大幅に削減可能です。画像分類や物体検出はもちろん、テキストや音声処理など、多様なタスクに対応した最新モデルが揃っており、開発者は本質的な課題解決に集中できます。
TensorFlowエコシステムは進化を続けており、TensorFlow 2.21のリリースに伴い、TensorFlow Liteモデルの実行速度が向上しました。これにより、Hubから取得したモデルをスマートフォンなどのエッジデバイスでより効率的に動かせます。モデルはすべて無料で利用できるため、コストを抑えたい個人開発者やスタートアップにも最適です。
機械学習モデルを迅速にプロトタイピングしたい方や、特定のタスクに特化したAIを手軽に開発したいエンジニアにとって、非常に強力なツールとなります。
主要な画像認識AIサービス10社の機能・料金を一覧で徹底比較
ここまで紹介した主要な画像認識AIサービス10社について、機能・料金・精度を一覧比較表でわかりやすく整理します。各サービスを個別に見ていくだけでは、自社に最適な選択は困難です。ここでは、最新の機能アップデートから料金体系、そしてAIベンチマークに基づく認識精度までを横断的に比較。あなたのプロジェクトに本当に必要なコストパフォーマンスと性能を備えたサービスがどれなのか、客観的なデータで確認しましょう。

【2026年最新】主要サービスの機能アップデート比較
2026年現在、各社の機能アップデートには2つの明確なトレンドが見られます。AI選定のポイントは、単なる認識精度だけでなく、自社の目的にどちらの方向性が合致するかを見極めることです。
一つは、GoogleのGemini連携やABBYY VantageのAzure OpenAI統合に代表される生成AIとの連携強化です。これにより、プロンプト(指示文)ベースで柔軟なデータ抽出が可能になるなど、生成AI時代の画像認識AIとは何かを各社が具体的に示し始めています。もう一つは、Hugging FaceやRoboflowのように、最新のオープンソースモデルへ即座に対応し、開発サイクル全体を高速化するプラットフォームとしての進化。自社で対話的な分析を重視するのか、迅速なモデル開発を優先するのかによって、注目すべきサービスは大きく異なります。
あわせて読みたい画像 認識 ai とはについて、導入方法から活用事例まで詳しく解説します。
料金プランとコストパフォーマンス比較一覧
画像認識AIの料金体系は、APIコール数に応じた従量課金制が主流ですが、無料枠の範囲や特定機能の単価は各社で大きく異なります。小規模なテストであれば、Google Cloud、AWS、Azureが提供する無料利用枠の活用が最も効率的です。一方、大規模な本番運用では、リクエスト量に応じて単価が下がるボリュームディスカウントの有無が総コストを左右します。
単純なAPI単価だけでなく、ABBYY Vantageのように特定業務に特化して開発工数を削減できるサービスや、OpenCVのようにライセンス費用がかからないオープンソースも選択肢です。ただし、後者は自社での環境構築や保守にかかる人的コストを考慮する必要があります。どのような機能を使うかで料金は変わるため、【2025年】画像認識AIの種類とはも参考に、自社の利用規模と目的に見合うコストパフォーマンスを備えたプランを選びましょう。
あわせて読みたい画像 認識 ai 種類について、導入方法から活用事例まで詳しく解説します。
AIベンチマークで見る最新の認識精度比較
APIの機能や料金だけでなく、客観的な「精度」を比較することもサービス選定の重要な判断材料です。その指標となるのが、LMSYS Chatbot ArenaのようなAIベンチマーク。これは単なる正解率ではなく、画像の内容について対話形式でタスクを処理する能力を評価するもので、より実用的な性能がわかります。
2026年3月時点のリーダーボードでは、Googleの「Gemini 3 Flash」がVision Score 79.0と他をリードしています。このスコアは、画像の内容を正確に理解し、複雑な質問に的確に答える能力の高さを証明するものです。ただし、こうした総合評価だけでなく、特定の業務に特化したAI画像認識検査のような用途では、その専門分野での精度を個別に検証する必要があります。自社の目的に合わせて、どの指標を重視するか見極めましょう。
あわせて読みたい
ai 画像 認識 検査について、導入方法から活用事例まで詳しく解説します。
【2025年】画像認識AIおすすめランキング10選を徹底比較!最新モデルの評価も紹介
ここからは、画像 認識 ai 比較のおすすめ10選を紹介します。それぞれの特徴やメリットを詳しく解説していますので、導入検討の参考にしてください。
1位:Google Cloud Vision AI
Google Cloud Vision AIは、世界トップクラスの精度を誇るGoogleの画像認識APIです。単体のサービスとしてだけでなく、Google Cloudの統合AIプラットフォーム「Vertex AI」の中核を担い、包括的なソリューションを提供します。
主な強みは、物体や顔の検出、高精度なOCR(文字認識)、ロゴ検出といった多彩な機能を、APIを通じて簡単に利用できる点にあります。さらに、Vertex AI Visionと連携することで、工場の品質管理や店舗の顧客分析など、リアルタイムの動画ストリーム解析も可能です。
2026年現在の進化の核は、最先端のマルチモーダルAI「Gemini」との統合です。実際に、AIの性能を測るLMSYS Arenaのリーダーボード(2026年1月)では「Gemini 3 Flash」がトップスコアを記録。これにより、画像の内容を深く理解し、質問に答えたり説明文を生成したりする高度なタスクが実現しました。料金は機能と処理量に応じた従量課金制で、毎月一定の無料枠も用意されています。
業界最高水準の認識精度を求めるプロジェクトや、Google Cloudの他のサービスと連携して大規模なAIシステムを構築したい企業に最適な選択肢です。
2位:Amazon Rekognition
Amazon Rekognitionは、Amazon Web Services (AWS) が提供する、深層学習を活用したフルマネージド型の画像・動画分析サービスです。専門的な機械学習の知識がなくても、シンプルなAPIを呼び出すだけで、物体やシーンの検出、顔認証、テキスト認識といった高度な機能を自社アプリケーションに組み込めます。
最大の強みは、S3やLambdaといったAWSの他サービスとの強力な連携です。これにより、データの保存から分析、結果の活用までをシームレスに自動化するワークフローを容易に構築できます。2026年3月時点では、画期的な新機能の発表は限定的ですが、ラベル検出の強化や動画分析の高度化など、既存機能の継続的な精度向上が図られています。
料金は分析した画像枚数や動画の長さに基づく従量課金制で、無料利用枠も用意されています。AWSを既に利用している企業や、スピーディに高精度な画像認識AIをサービスに導入したい開発チームに最適な選択肢です。
3位:Microsoft Azure AI Vision
Microsoftが提供するクラウドベースの画像認識サービスが「Azure AI Vision」です。豊富な機能をAPI経由で利用でき、既存のアプリケーションやシステムに高度な視覚認識機能を容易に組み込めます。
主な強みは、1つのAPIで物体検出・文字認識(OCR)・人物検出など多彩な分析が可能な点にあります。さらに、Azureの他のサービス群とシームレスに連携できるため、Microsoft製品をメインで利用する企業にとっては開発効率が非常に高い選択肢となるでしょう。
2025年3月に旧APIが廃止され、現在は一般提供版の「Image Analysis 4.0」への移行が必須です。このバージョンでは、画像と多言語テキストを組み合わせた高度な検索ができるマルチモーダル埋め込み機能が強化されています。料金は従量課金制で、1,000トランザクションあたり1ドルから利用でき、無料枠も用意されています。
既にAzure環境を導入済みの企業や、SDK/APIを使って自社システムへ柔軟に機能を組み込みたい開発者の方に特におすすめです。
4位:Hugging Face Hub
Hugging Face Hubは「AI版のGitHub」とも称される、世界最大級の機械学習プラットフォームです。画像認識を含む200万以上のAIモデルやデータセットが公開されており、最先端の技術を誰でも手軽に試せるのが最大の強み。オープンソースAIのエコシステムの中核を担い、世界中の開発者や企業がモデルを共有しています。
2026年3月には、学習データや中間生成物といった大容量ファイルを柔軟に管理できる新機能「Storage Buckets」が追加されました。さらに、基盤ライブラリ「Transformers」がv5へとメジャーアップデートされ、推論の高速化や外部ツールとの連携がより容易になっています。
基本的な利用は無料ですが、チームでの利用や高度な機能を提供するProプラン(月額$9〜)も用意されています。最新の画像認識モデルをいち早く試したい開発者や、オープンソースの資産を活用して効率的にAI開発を進めたい企業に最適な選択肢です。
5位:Roboflow
Roboflowは、画像のアノテーションからモデルのトレーニング、デプロイまで、コンピュータービジョン開発の全工程を一つのプラットフォームで完結させられるサービスです。
最大の特徴は、GUIベースで直感的に操作できる使いやすさと、開発サイクルを高速化する豊富な機能群にあります。2026年には、最新の物体検出モデル「YOLOv26」へ即座に対応したほか、ドラッグ&ドロップで処理を組める「Workflows Builder 2.0」をリリース。これにより、専門家でなくても高度な画像認識AIを構築可能です。無料のPublicプランから利用できるため、学習や小規模なプロジェクトから手軽に始められる点も魅力でしょう。
コンピュータービジョン開発の工数を大幅に削減したい企業や、最新モデルを迅速に試したいエンジニアに特におすすめのツールです。
6位:Clarifai
Clarifaiは、画像認識だけでなくテキストや動画など多様なデータを扱える、開発者向けの包括的なAIライフサイクルプラットフォームです。豊富な事前学習済みモデルと、独自のデータでモデルを構築できる柔軟性を両立させています。
このプラットフォームの強みは、マルチモーダルなAI開発に対応している点でしょう。画像分類から自然言語処理、生成AIまで、複数のAI機能をAPI経由で組み合わせ、独自のワークフローを設計できます。2026年3月時点の最新情報として、料金体系が最低月額料金のない従量課金制(Pay-As-You-Go)プランへ移行しました。これにより、GPUの自動プロビジョニングといった高度な機能が小規模なプロジェクトでも利用しやすくなったのは大きなメリットです。
利用した分だけ支払う料金体系のため、スモールスタートでAI導入を試したい企業や、多様なAIモデルを組み合わせて独自のソリューションを構築したい開発者に向いています。
7位:OpenCV
7位は、世界中の開発者や研究者に利用されている、定番のオープンソース・コンピュータビジョンライブラリ「OpenCV」です。無料で利用できる手軽さと、画像処理から機械学習までを網羅する圧倒的な機能量が最大の強み。PythonやC++など多様なプログラミング言語に対応しており、研究開発から商用アプリケーションまで、目的に応じて柔軟にシステムを構築できます。
最新の動向として、次期メジャーバージョンであるOpenCV 5.xへの移行が進んでおり、DNN(ディープラーニング)モジュールが抜本的に強化されました。最新のAIモデルのサポートや、AWS Graviton 4といったエッジデバイス向けプロセッサへの最適化も進んでいます。ライセンス費用は無料なので、コストを抑えて高機能な画像認識AIを開発したいスタートアップや個人開発者、学術研究機関に特におすすめです。
8位:Google Lens
Googleが提供する「Google Lens」は、スマートフォンのカメラをかざすだけで、目の前のあらゆるものを検索できる無料の画像認識ツールです。日常のふとした疑問を即座に解決してくれます。
このツールの最大の強みは、その手軽さと多機能性。街で見かけた商品の特定から、外国語メニューのリアルタイム翻訳、植物や動物の名前を調べるといった多彩な用途で活躍します。Googleアプリや多くのAndroidスマートフォンに標準搭載されており、誰でもすぐに利用できる点も大きなメリットです。
最新のアップデートでは、高性能AI「Gemini」との連携が強化されました。これにより、Googleマップ上でカメラを風景にかざすだけでランドマークを認識し、より直感的なナビゲーションが可能になるなど、機能が向上しています。料金は完全無料で利用できるため、旅行先での翻訳や、日常生活での情報収集を手軽に行いたい個人ユーザーに最適なツールです。
9位:ABBYY Vantage
ABBYY Vantageは、請求書や契約書といった多様なビジネス文書から、AIがデータを自動で抽出・分類するIDP(インテリジェント・ドキュメント・プロセッシング)プラットフォームです。専門知識がなくても直感的に操作できるローコード/ノーコード環境が特徴で、金融や物流など業界に特化した150種類以上のAIモデル(スキル)が用意されており、迅速な導入を実現します。
2026年1月にリリースされた最新版「Vantage 3.0」では、生成AI(Azure OpenAI)との直接統合が大きな注目点。これにより、プロンプト(指示文)を使って柔軟にデータを抽出できるようになりました。従来のAIが持つ高い精度と生成AIの柔軟性を組み合わせ、複雑な文書処理の自動化レベルを一段と高めています。また、プロセスの稼働状況を可視化する分析ダッシュボードや、機密情報を自動で墨消しするコンプライアンス機能も強化されました。
価格は利用規模に応じた個別見積もりです。金融、保険、物流など、日々大量の非定型文書を処理し、業務プロセス全体の効率化と自動化を目指す大企業に特におすすめします。
10位:TensorFlow Hub
TensorFlow Hubは、Googleが提供する学習済みの機械学習モデルを共有・再利用できるライブラリです。画像認識をはじめ、自然言語処理や音声認識など、多種多様なモデルが公開されており、開発者はこれらを活用してAI開発の時間を大幅に短縮できます。
最大の特徴は、転移学習を手軽に実践できる点にあります。数行のコードで高性能なモデルをダウンロードし、独自のデータセットで再学習させるだけで、高精度なAIを構築可能です。TensorFlowのコアAPIであるKerasとシームレスに連携できるため、既存の開発フローにもスムーズに組み込めます。
2026年3月現在、TensorFlow本体のアップデートに伴い、エッジデバイス向けのTensorFlow Liteモデルの実行が高速化されています。これにより、Hubから取得したモデルをスマートフォンなどでもより効率的に動かせるようになりました。利用は基本的に無料ですが、モデルのライセンスは個別に確認が必要です。
ゼロからモデルを構築する時間や計算リソースを節約し、迅速にプロトタイプを開発したいエンジニアや研究者、スタートアップにおすすめです。
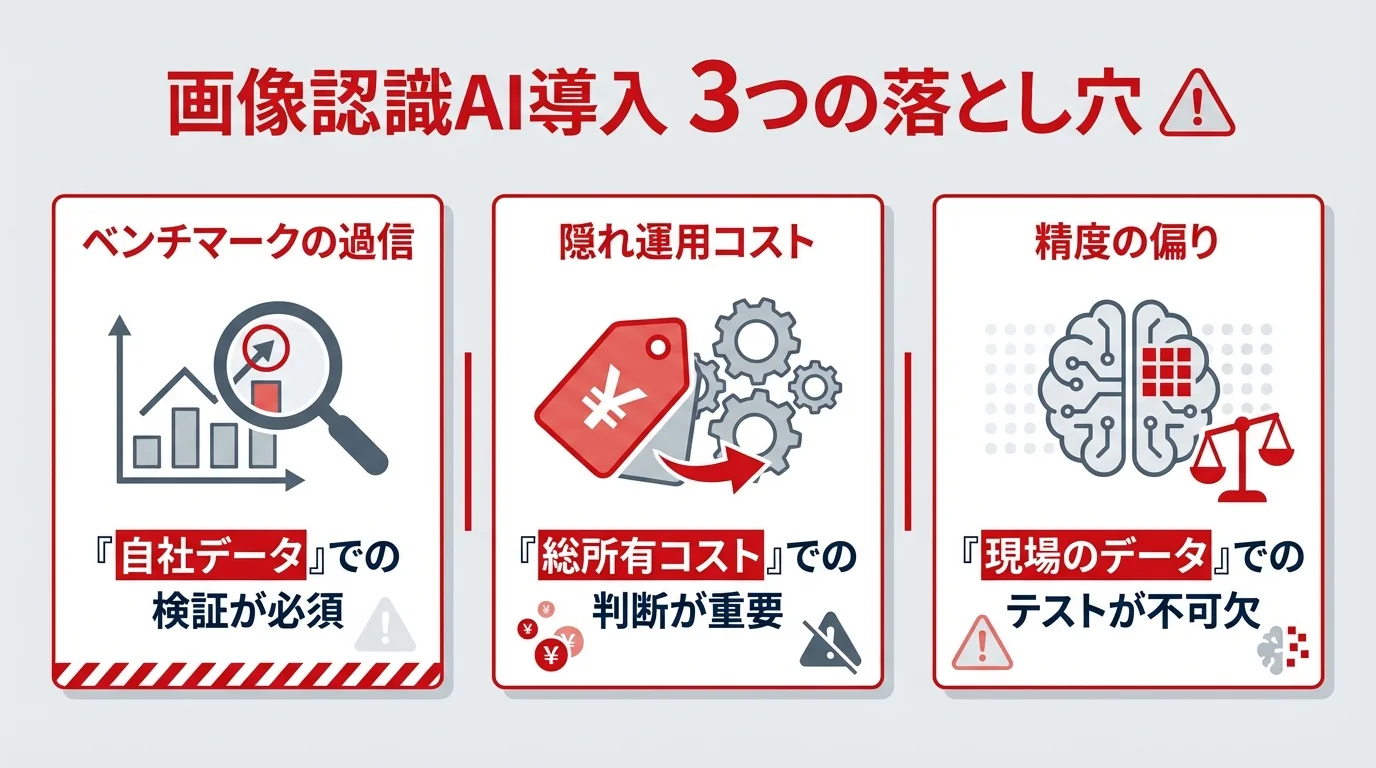
画像認識AI導入で失敗しないための注意点|精度とコストの落とし穴とは?
さて、ここまで各社の華やかな機能やランキングを見てきたわけだが、それだけで導入を決めるのはあまりに危険だ。ベンチマークの高スコアや一見安価に見えるAPI料金に惹かれて安易に飛びつけば、まず間違いなく失敗する。本当の画像 認識 ai 比較とは、表に出てこない隠れコストや、特定のデータでしか露呈しない精度の偏りを見抜くことにある。ここからは、導入担当者が必ずハマる「落とし穴」について、忖度なく解説していこう。
ベンチマークの高スコアを鵜呑みにする危険性
ベンチマークのスコアは、完璧に照明が整えられた環境で、綺麗な画像を使って行われる「学力テスト」でしかない。これを自社の泥臭い現場にそのまま当てはめるのは、あまりに短絡的だ。例えば、LMSYS Arenaで最高評価を得た汎用AIも、工場の生産ラインで油に汚れた部品の微細な傷を検出するような専門的なタスクでは、まったく歯が立たない。実際、特定のフォーマットの帳票OCRでは9位のABBYY Vantageが、1位のGoogleを圧倒する精度を出すことも日常茶飯事である。重要なのは、自社のデータでPoC(概念実証)を行うこと。公開スコアを信じるのではなく、無料トライアルで徹底的に比較検証した結果だけが、唯一信じるに足る指標なのだ。
API料金表に載らない「隠れ運用コスト」
API料金の安さだけで選ぶのは、愚の骨頂だ。「1リクエスト0.1円」といった数字に騙されてはいけない。本当に企業の体力を奪うのは、料金表には決して載らない人件費である。例えば、7位のOpenCVのようなオープンソースは一見無料だが、その裏では専門エンジニアによるインフラ構築と保守という泥沼が待っている。また、自社データで精度を出すために必要なアノテーション作業も、結局は地道な人海戦術であり、外部委託すれば莫大な費用がかかるのだ。表面的なAPI単価で比較するのではなく、開発工数や保守費用まで含めた総所有コスト(TCO)で判断しなければ、数年後に必ず後悔することになる。
特定のデータで露呈する認識精度の偏り
ランキング上位のAIは、多様な画像に対応できる「優等生」に見えるだろう。しかし、その認識精度は学習データに大きく依存しており、特定の条件下では驚くほど無力化する。これがAIのバイアス問題だ。例えば、欧米のデータセットで学習した顔認識AIが、アジア人の顔を正確に見分けられないケースは後を絶たない。また、晴天時の屋外で撮影された画像で高精度を誇るモデルも、薄暗い倉庫内や西日の当たる環境では、物体の誤認識を頻発させる。この落とし穴を避ける唯一の方法は、自社の実データで徹底的に試すこと。APIのデモサイトで綺麗なサンプル画像を試して満足してはいけない。泥や油にまみれた部品、光が反射するビニール包装、画質の粗い監視カメラ映像など、現場の「汚いデータ」でこそAIの真価が問われるのだ。ランキングの順位は、この過酷なテストをクリアして初めて意味を持つ。
まとめ:自社の課題解決に最適な画像認識AIを選ぼう
ここからは、画像 認識 ai 比較のおすすめ10選を紹介します。それぞれの特徴やメリットを詳しく解説していますので、導入検討の参考にしてください。


