LLMリーダーボードとは?AIの性能を測る「ものさし」を徹底解説
ChatGPTやGeminiなど、次々と登場する大規模言語モデル(LLM)。「結局、どのAIが一番賢いの?」と疑問に思ったことはありませんか?その疑問に答えるのが、AIの性能を客観的な指標で比較し、ランキング形式で公開するLLMリーダーボードです。これはまさに、AIモデルたちのための「成績表」や性能を測る「ものさし」のような存在。このセクションでは、LLMリーダーボードがどのような仕組みでAIの性能を評価しているのか、そしてなぜ開発競争において重要視されるのかを、最新の動向も交えながら詳しく解説します。まずは、この「ものさし」の基本を理解して、AIモデルを正しく評価する第一歩を踏み出しましょう。
LLMの性能を可視化する「ものさし」の仕組み
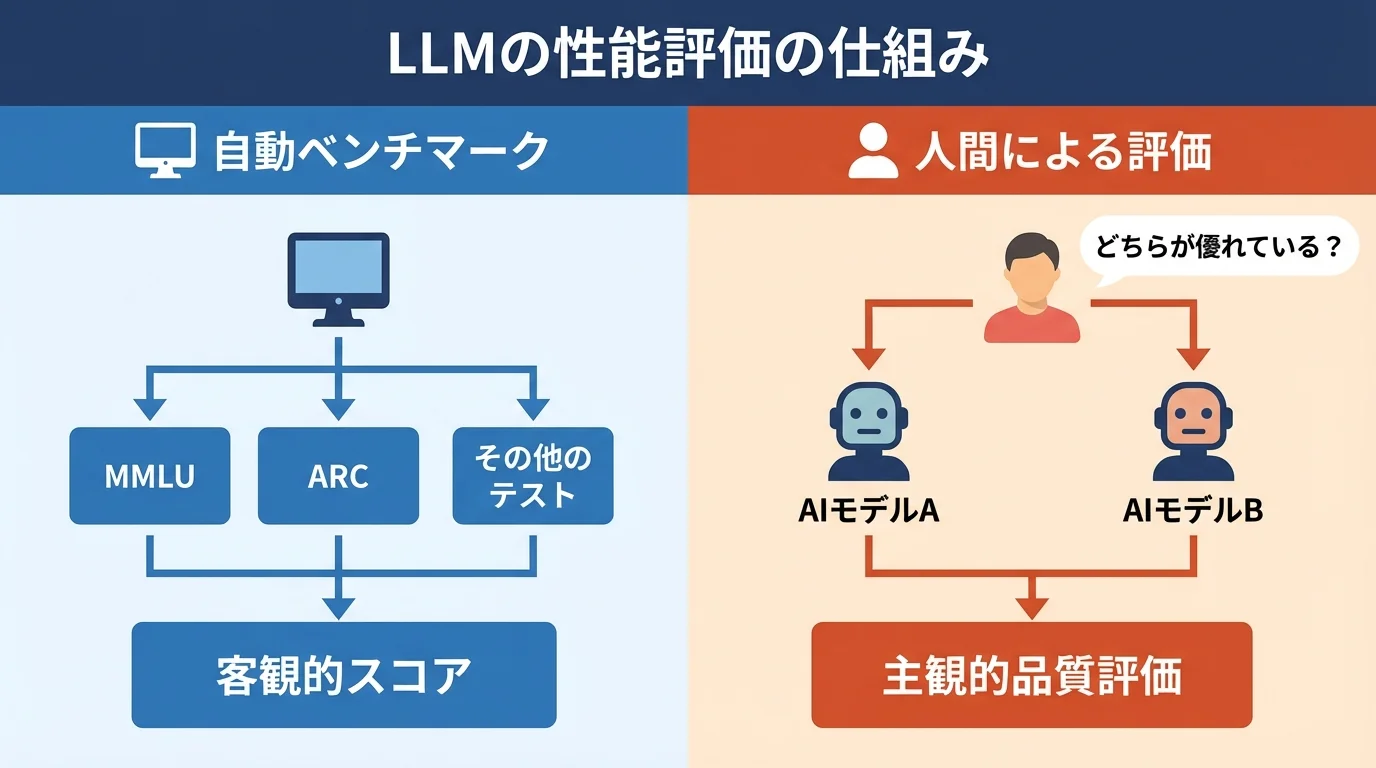
LLMリーダーボードの「ものさし」は、大きく2つの仕組みで成り立っています。1つ目は、標準化された問題群を解かせる自動ベンチマークです。これには、一般的な知識を問う「MMLU」や、高度な推論能力を測る「ARC」といった複数のテストが含まれます。モデルがこれらのテストでどれだけ高い正答率を出すかで、知識量や論理性が客観的にスコア化されるのです。
2つ目は、より主観的な質を評価する人間による評価です。例えば、2つのモデルの回答を匿名でユーザーに提示し、「どちらがより優れているか」を投票させる方法が挙げられます。これにより、自動テストでは測りにくい創造性や会話の自然さが評価されます。最近では、この評価者自体をAIが担う「llm as a judge」の是非も活発に議論されており、評価手法そのものが進化を続けています。
あわせて読みたい
llm as a judgeについて、導入方法から活用事例まで詳しく解説します。
開発競争におけるベンチマークとしての重要性
LLMの開発競争が激化する中で、リーダーボードは単なる順位表以上の重要な役割を担います。開発者にとっては、自社モデルがどのレベルにあるのかを客観的に把握し、次に目指すべき性能目標を定めるための開発ロードマップそのもの。例えば、「読解力スコアを次のバージョンで5%向上させる」といった具体的な目標設定に直結します。一方、LLMをビジネスに活用したい企業にとっては、膨大な選択肢の中から自社の目的に合ったモデルを見つけるための客観的な選定基準として機能するのです。特にセキュリティの観点からなぜ今ローカルLLMなのかを検討する企業にとって、オープンソースモデルの性能比較は欠かせません。このように、リーダーボードは開発と導入の両面で、技術進化を導く羅針盤となっています。
あわせて読みたい
llm ローカルについて、導入方法から活用事例まで詳しく解説します。
2026年最新動向:オープンソースの台頭と評価軸
2026年現在、LLMの世界ではオープンソースモデルの性能が飛躍的に向上し、特定の分野では商用モデルを凌駕するケースも珍しくありません。この背景には、自社データで自由にカスタマイズできる柔軟性や、なぜ今ローカルLLMなのかといったセキュリティへの関心の高まりがあります。この流れを受け、リーダーボードの評価軸も変化しました。単なる総合スコアだけでなく、「推論コスト効率(性能あたりの費用)」や「コーディング能力」「特定業界での専門性」といった、よりビジネスの現場に近い指標が重要視されるようになっています。モデルを選ぶ際は、総合順位だけでなく、自社の用途に合ったこれらの新しい評価軸で比較検討することが不可欠です。
あわせて読みたいllm ローカルについて、導入方法から活用事例まで詳しく解説します。
【2026年最新】LLMリーダーボードの選び方|オープンソースの台頭と評価指標の変化が鍵
ここからは、llm leaderboardのおすすめ10選を紹介します。それぞれの特徴やメリットを詳しく解説していますので、導入検討の参考にしてください。

1位:Hugging Face Open LLM Leaderboard
Hugging Face Open LLM Leaderboardは、世界中のオープンソース大規模言語モデル(LLM)の性能を、客観的な指標で比較・評価できるプラットフォームです。開発者や研究者が最新モデルの性能を把握するための、事実上の標準(デファクトスタンダード)となっています。
主な特徴は、複数のベンチマークに基づいた公平な性能評価と、活発なコミュニティによる情報の更新速度にあります。ARCやHellaSwagといった多様なタスクの平均スコアでモデルが順位付けされるため、総合的な能力を一目で比較できます。また、モデルの規模や精度で結果を絞り込む機能もあり、用途に合ったLLMを効率的に探せる点も強みです。常に新しいモデルがコミュニティから提出され、LLM開発の最新トレンドをリアルタイムで追えることも大きなメリットでしょう。
2024年後半以降、評価方法が更新され、スコアの算出に正規化スコアが導入されました。これにより、GPQAやMATHのような高難易度のベンチマークにおける性能向上が、よりランキングに反映されやすくなっています。利用は無料で、自身のプロジェクトに最適なオープンソースLLMを性能ベースで選びたい開発者や、モデル開発の最前線を追いかけたい研究者におすすめです。
2位:LMSys Chatbot Arena Leaderboard
LMSys Chatbot Arena Leaderboardは、人間による直接対決の投票結果に基づき、LLMの性能を格付けする世界で最も注目されているランキングです。従来のベンチマークとは異なり、匿名のモデル同士をユーザーが比較評価するブラインドテスト方式を採用している点が最大の特徴である。
このアプローチにより、計算上のスコアでは測れない、より実践的で「人間にとって自然か」という観点での性能が明らかになります。集計された評価はEloレーティングという客観的な指標でランキング化され、誰でもリアルタイムで最新の勢力図を確認できます。2026年には「コーディング」など専門分野別のリーダーボードや、難問に特化した「High ELO Ranking」が追加され、より多角的なモデル評価が可能となりました。
ランキングの閲覧や評価への参加は無料です。最新LLMの客観的な実力を知りたい開発者や、自社サービスに導入するAIを選定したい企業にとって、最も信頼性の高い判断材料の一つとなります。
3位:Japanese LLM Leaderboard
3位は、LLM-jpとHugging Faceが共同で運営する「オープン日本語LLMリーダーボード」です。オープンソースコミュニティが主導する透明性の高い評価基準が特徴で、誰でも評価手法や結果を検証できる点が支持されています。
このリーダーボードの強みは、評価ツール「llm-jp-eval」を用いて16種類以上の多様なタスクで日本語LLMの性能を多角的に評価している点にあります。Hugging Face Spaces上で提供されるUIは非常にインタラクティブで、モデルのフィルタリングや比較が直感的に行えるのも魅力。最近ではv2(バージョン2)へのアップデートで、思考連鎖プロンプトなどを採用した高難度なベンチマークが導入され、より実践的な推論能力の評価が可能になりました。利用は完全に無料で、オープンな日本語LLMの性能比較をしたい開発者や研究者にとって、まず確認すべき情報源の一つです。
4位:HELM (Holistic Evaluation of Language Models)
スタンフォード大学が開発したHELMは、LLMの性能を多角的に評価するためのオープンソース・フレームワークです。単なる正解率だけでなく、公平性や堅牢性、バイアスといった複数の指標でモデルの能力とリスクを総合的に評価できる点が最大の特徴となっています。
その強みは、標準化された条件下で様々なモデルを公平に比較できる透明性にあります。これにより、開発者は自社の用途に最適なモデルを客観的なデータに基づいて選定することが可能です。2026年には医療タスクに特化した「MedHELM」が発表されるなど、評価領域の専門化・拡張も継続しており、ベンチマークとしての信頼性は非常に高いです。
フレームワーク自体の利用は無料ですが、評価の実行には別途計算リソース(クラウド費用など)が必要です。複数のLLMを公平な基準で比較したい研究者や、AIのリスクを定量的に把握したい企業にとって重要な選択肢となります。
5位:AlpacaFarm Leaderboard
Stanford大学が開発した、指示追従(instruction-following)能力の評価に特化したリーダーボードです。単なる性能比較だけでなく、RLHF(人間のフィードバックからの強化学習)の研究を低コストで促進することを目的に設計されている点が大きな特徴。自動評価フレームワークにより、高速かつ安価にモデルの性能を測定できるため、多くの研究者に利用されています。
最新の評価基盤「AlpacaEval 2.0」では、評価の公平性を高める「長さ制御付き勝率」が導入されました。これは、回答の長さでスコアが偏るバイアスを補正する仕組みであり、人間による評価との相関が0.98まで向上し、より信頼性の高いベンチマークへと進化しています。
このリーダーボードはオープンソースで公開されており、利用料金はかかりません。自身で開発したモデルの性能を客観的に測りたいAI開発者や、RLHFのようなアライメント技術の研究を進めたい研究者に特におすすめです。
6位:MMLU Leaderboard
MMLUは、LLMの広範な知識と問題解決能力を57の多様なタスクで測定する、AIの「基礎学力」を測るための代表的なベンチマークです。その網羅性から長年、多くのモデル評価の基準とされてきました。
しかし2026年現在、多くの高性能モデルがスコア90%以上に達し、性能差を測りにくい「飽和状態」にある点が大きな特徴です。この課題を解決するため、現在はより高難易度な後継ベンチマーク「MMLU-Pro」が主要な評価指標へと移行しています。MMLU-Proは、解答の選択肢を従来の4択から10択に増やし、大学院レベルの専門知識を問うことで、モデルのより深い推論能力を評価します。リーダーボードはArtificial AnalysisやHugging Faceなどで無料で閲覧可能です。
LLMの基礎的な知識レベルを把握したい開発者や研究者に向いています。ただし、最先端モデルの優劣を判断するには、MMLU-Proや他の専門ベンチマークと合わせて評価することが不可欠です。
7位:Big-Bench Leaderboard
Googleが主導する「Big-Bench」は、200以上の多様なタスクで構成される、LLMの総合的な能力を測るためのベンチマークです。言語学から常識推論、数学までを網羅するタスクの多様性が強みであり、特に難易度の高い23タスクを集めた「Big-Bench Hard (BBH)」は、モデルの高度な推論能力を比較する上で広く利用されています。
2026年3月現在、Big-Bench自体に大きな更新はありませんが、モデルの進化に対応するため、より挑戦的な「BIG-Bench Extra Hard (BBEH)」といった派生ベンチマークが登場している状況です。一方で、BBHでもトップモデルのスコアが飽和しつつあるという指摘もあり、評価指標のトレンドを追うことが重要になります。ベンチマークの利用自体は無料ですが、評価の実行には相応の計算リソースが必要です。
新規開発したLLMの性能を客観的に示したい研究機関や、モデルの能力を多角的に分析したい開発者におすすめです。
8位:EleutherAI LM Evaluation Harness
EleutherAIが開発した、LLMの性能評価におけるデファクトスタンダードとなっているオープンソースフレームワークです。Hugging Faceの「Open LLM Leaderboard」の評価基盤としても採用されています。
このツールの最大の強みは、統一された基準で様々なモデルの性能を公平に比較できる点にあります。数学的推論能力を測る「MATH500」や長文読解を評価する「Longbench v2」など、60を超える多様なベンチマークに対応しており、モデルの能力を多角的に分析することが可能です。
最近のアップデートではインストールプロセスが軽量化され、pip install lm_eval[hf]のように必要なモデルバックエンドのみを選択して導入できるようになり、環境構築が迅速になりました。また、Windows ML Backendのネイティブサポートも追加され、利便性が向上しています。
無料で利用できるため、自社開発モデルの性能を客観的に測定したい研究者や、複数のLLMを公平に比較検討したい開発者に最適なツールです。
9位:C-Eval Leaderboard
C-Evalは、中国語の大規模言語モデル(LLM)が持つ知識と推論能力を評価することに特化したベンチマークです。人文科学から理工学まで52の多様な分野をカバーする問題で構成されており、中国語LLMの性能を多角的に測定できる点が強みとなります。
最大の注意点として、公式サイトのリーダーボードは2025年7月をもって更新を停止しています。そのため、最新モデル同士の性能を直接比較するランキングとしては現在機能していません。その代わり、これまで非公開だったテストセットが公開され、開発者が手元でモデルを評価するための「標準化された物差し」へと役割を変えました。利用は無料です。
最新のLLMランキングを知りたい方には不向きですが、自社で開発・調整したモデルの中国語性能を客観的な指標で測定したい研究者や開発者にとって、依然として価値のあるツールだ。
10位:Evals (by OpenAI)
OpenAI Evalsは、LLMの性能を体系的に評価するために同社が開発したオープンソースのフレームワークです。最大の強みは、自社の特定ユースケースに合わせて独自の評価基準を定義し、モデルの性能を客観的に測定できる点にあります。開発プロセスに組み込むことで、プロンプト変更時などの性能劣化(リグレッション)を自動で検知する仕組みを構築できます。2026年3月にはAIテストツール「Promptfoo」を買収するなど、評価体制の強化が図られており、今後の機能拡充も視野に入ります。フレームワーク自体は無料ですが、評価の実行にはOpenAI APIの利用料が発生するため、大規模なテストには注意が必要です。LLM搭載アプリの品質を継続的に管理したい開発チームや、複数のモデルを比較検討して最適なものを選びたい企業におすすめのツールです。
主要LLMリーダーボード10種の評価軸・特徴を一覧比較
ここまで10種類の主要なLLMリーダーボードを紹介してきましたが、「数が多くて、どれを参考にすれば良いかわからない」と感じた方もいるかもしれません。そこでこのセクションでは、各リーダーボードを「評価方法の違い(自動か人間か)」や「対象領域(汎用か日本語特化か)」といった複数の切り口から横断的に比較し、その特徴を一覧でわかりやすく整理します。それぞれの「ものさし」が持つ個性と強みを理解することで、あなたの目的に本当に合ったリーダーボードを見つけやすくなるでしょう。
評価軸の違い:自動ベンチマーク vs 人間評価
LLMの評価方法は、大きく「自動ベンチマーク」と「人間評価」の2種類に分けられます。それぞれ得意な領域が異なるため、あなたの目的に応じて使い分ける視点が欠かせません。
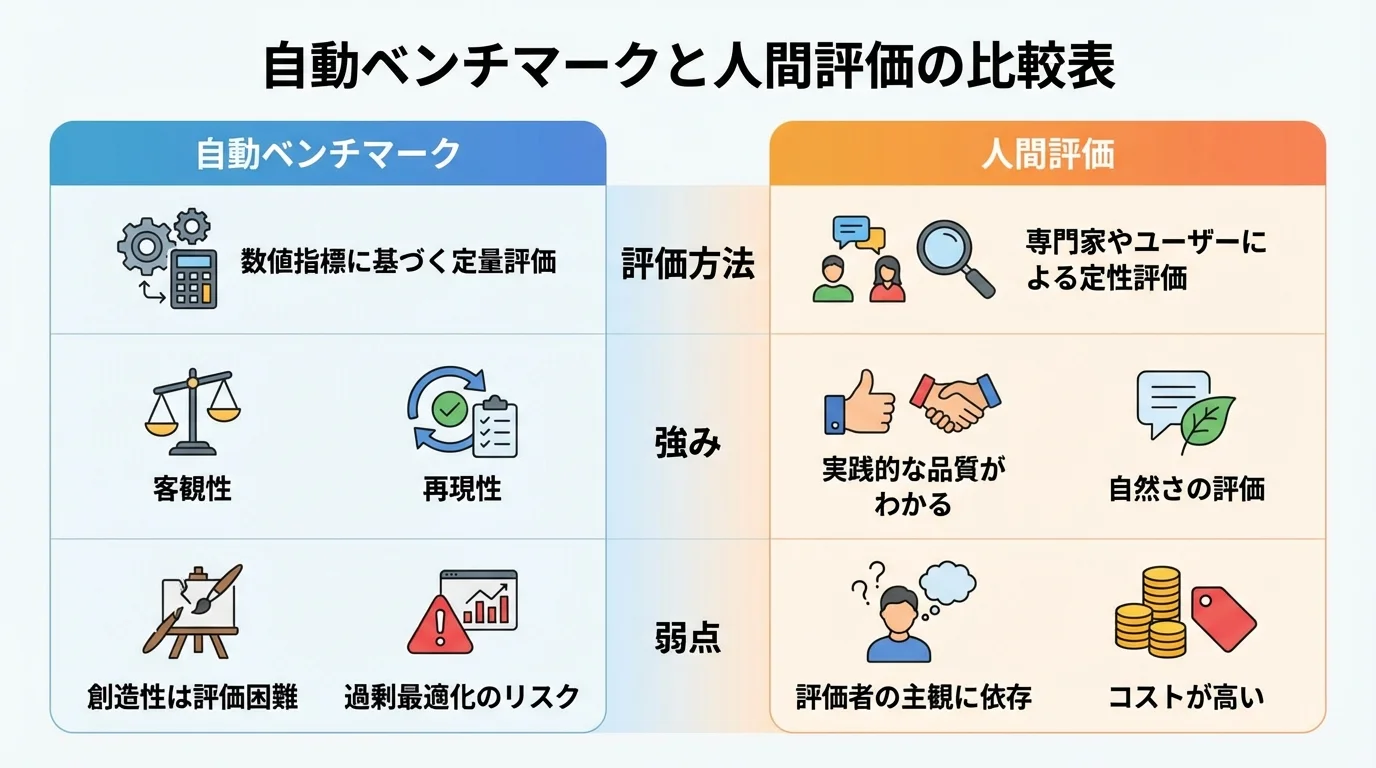
自動ベンチマークは、数学や論理クイズのような明確な正解がある問題セットでLLMの性能を測る方法です。Hugging Faceのリーダーボードが代表的で、客観的な指標でモデルの基礎能力を比較できるのが強み。ただし、ベンチマークに過剰最適化されたモデルが高スコアを出す可能性や、創造性といった数値化しにくい側面は評価できないという弱点があります。
一方、人間評価はLMSys Chatbot Arenaのように、実際のユーザーが「どちらの回答がより自然で優れているか」を直接判断します。これにより、会話の面白さや気の利いた提案力といった、実践的な対話品質が明らかになるのです。ただし、評価者の主観に左右される側面もあり、評価コストをどう下げるかという文脈で「llm as a judge」の是非も活発に議論されています。基礎能力は自動評価、使い心地は人間評価と、両者を補完的に見るのが賢いリーダーボードの活用法です。
あわせて読みたいllm as a judgeについて、導入方法から活用事例まで詳しく解説します。
対象領域で比較:汎用 vs 日本語特化モデル
LLMリーダーボードは、評価対象とする領域によっても役割が異なります。主に英語タスクでグローバルな性能を測る汎用リーダーボードと、「Japanese LLM Leaderboard」のような日本語特化リーダーボードの2種類を意識することが重要です。
Hugging FaceやLMSysといった汎用リーダーボードは、モデルの基礎的な実力を世界基準で比較するのに最適。しかし、そのスコアが高くても、日本語の繊細なニュアンスや文化的な文脈を正確に扱えるとは限りません。一方で日本語特化のリーダーボードは、敬語の適切さや日本の慣習に関する知識といった、より国内ビジネスに直結する能力を評価します。
日本市場向けのサービスを開発する場合、汎用モデルのスコアだけを信じるのは危険です。参考として他社はどう使ってるのかを調べ、自社のユースケースに合った指標を見ることが成功の鍵となります。
あわせて読みたい
生成 ai 活用 事例について、導入方法から活用事例まで詳しく解説します。
2026年最新:新世代オープンLLMへの対応状況
2026年現在、オープンLLMはテキストだけでなく画像も扱うマルチモーダル性能や、数百万トークンを処理する長文対応が標準となりつつあります。この進化に追随するため、リーダーボードの評価軸も大きく変化しました。例えば、Hugging Faceでは「MMMU」のようなマルチモーダルベンチマークや、長文読解力を測る「LongBench」のスコアが重視されるようになっています。こうした新しい指標は、従来のベンチマークでは測れなかったモデルの実践的な能力を可視化します。オープンLLMの進化と、なぜ今ローカルLLMなのかというセキュリティへの関心は、今後も評価基準をさらに細分化させていくでしょう。リーダーボードを見る際は、こうした最新の評価軸に対応しているかを確認することが重要だ。
あわせて読みたいllm ローカルについて、導入方法から活用事例まで詳しく解説します。
LLMリーダーボードおすすめランキングTOP10【2026年最新版】
ここからは、llm leaderboardのおすすめ10選を紹介します。それぞれの特徴やメリットを詳しく解説していますので、導入検討の参考にしてください。
1位:Hugging Face Open LLM Leaderboard
Hugging Face Open LLM Leaderboardは、世界中のオープンソース大規模言語モデル(LLM)の性能を客観的な指標で比較・評価する、事実上の標準プラットフォームです。
主な特徴は、複数のベンチマークスコアを基にした公平なランキングにあります。モデルのタイプや精度で絞り込めるフィルタ機能も充実しており、目的に合ったモデルを効率的に探せます。誰でも自作モデルを提出して性能を競えるオープンなコミュニティ性も、技術革新を加速させる大きな要因となっています。
最近の大きな更新として、スコア算出方法が変更され、難しいタスクでの性能向上がより評価される正規化スコアが導入されました。また、専門家レベルの知識を問う「GPQA」や数学的能力を測る「MATH」といった高難易度の新ベンチマークが追加され、モデルの真の能力を多角的に評価できるようになっています。
このリーダーボードは、誰でも無料で利用可能です。
自身のプロジェクトに最適なオープンソースLLMを選定したい開発者や、LLM開発の最先端トレンドを把握したい研究者・エンジニアに最適です。
2位:LMSys Chatbot Arena Leaderboard
LMSys Chatbot Arena Leaderboardは、人間によるブラインドテストを通じてLLMの対話性能を評価する、事実上の標準プラットフォームです。従来のベンチマークテストでは測れない、より実践的で総合的な能力を比較できるため、多くの開発者や企業がモデル選定の指標として活用しています。
最大の特徴は、匿名の2つのモデルから生成された回答をユーザーが比較投票し、その結果をEloレーティングという指標でランキング化する点にあります。このクラウドソーシング方式により、特定のタスクだけでなく、より自然な対話における性能が明らかになります。ただし、評価はあくまで人間の主観に基づくため、投票者の層によるバイアスの可能性は考慮する必要があります。
2026年に入り、コーディング能力に特化した「コーディング・アリーナ」や、高難度の論理パズルに特化した「High ELO Ranking」が導入され、モデルの能力をより多角的に評価できるようになりました。利用は無料で、誰でも最新モデルの性能比較に参加できます。
開発中のモデルの性能を客観的に把握したい研究者や、自社サービスに導入するLLMを実用的な視点で選びたい企業に最適なプラットフォームです。
3位:Japanese LLM Leaderboard
3位は、日本語LLMの性能を客観的に比較・評価できる指標である「Japanese LLM Leaderboard」です。これは特定のAIモデルではなく、様々な日本語特化モデルの性能を共通のベンチマークで測定し、スコア化したランキングサイトを指します。
最大の強みは、客観的なデータに基づき、自社の目的に最適なLLMを選定できる点です。「Nejumi LLM Leaderboard」や「オープン日本語LLMリーダーボード」などが存在し、質問応答や文章要約といったタスクごとの性能を横並びで比較できます。2026年に入り、コーディング能力やより高度な推論能力を測るベンチマークが導入されるなど、評価の解像度は継続的に向上しています。これらのリーダーボードは基本的に無料で公開されており、誰でも最新のランキングを確認することが可能です。
自社開発LLMの性能を客観的に測りたい企業や、プロジェクトに導入するオープンソースモデルを選定したい開発者にとって、不可欠な情報源となります。
4位:HELM (Holistic Evaluation of Language Models)
HELMは、スタンフォード大学が開発したLLMの総合評価フレームワークです。単なる正解率だけでなく、公平性や安全性といった多角的な視点からモデルの性能を客観的に評価することに特化しています。
最大の特徴は、正解率、公平性、堅牢性、効率性、バイアス、毒性といった複数の指標を用いて、LLMの能力とリスクを網羅的に評価できる点です。オープンソースであるため誰でも利用でき、公開されているリーダーボードで主要なモデルの性能を横並びで比較検討できます。一方で、評価シナリオの多くが英語中心であり、多言語モデルの評価には限界がある点や、大規模な評価には高い計算コストがかかる点は注意が必要です。
2026年1月には医療タスクに特化した「MedHELM」が発表されるなど、専門分野への拡張が進んでいます。フレームワーク自体の利用は無料ですが、評価実行には別途計算リソースが必要です。
複数のLLMを公平な基準で比較したい企業や、AIの潜在的リスクを定量的に把握し、責任あるAI開発を目指す研究者に最適なツールです。
5位:AlpacaFarm Leaderboard
AlpacaFarm Leaderboardは、スタンフォード大学が開発した、指示追従モデルの性能評価に特化したベンチマークです。高速かつ安価な自動評価システム「AlpacaEval」を採用しており、特にAI開発者や研究者の間で広く利用されています。RLHF(人間のフィードバックからの強化学習)の研究を低コストで促進するシミュレーターとしての側面も持ち合わせているのが特徴です。
最新の評価基盤である「AlpacaEval 2.0」では、評価の公平性を大きく向上させる「長さ制御付き勝率」が標準指標となりました。これは、単に長い回答が高く評価されてしまう「長さバイアス」を統計的に補正する仕組みです。このアップデートにより、人間による評価との相関が0.98へと大幅に向上し、より信頼性の高い比較が可能になっています。
このリーダーボードはオープンソースで公開されており、誰でも無料で利用できます。自社開発したモデルの性能を客観的な指標で比較したいAI開発者や、低コストでアライメント技術の研究を進めたい研究機関におすすめです。
6位:MMLU Leaderboard
MMLUは、LLMの幅広い分野における基礎知識を測定するための定番ベンチマークです。数学、歴史、法律、コンピュータサイエンスといった57の多様なテーマをカバーしており、モデルの汎用的な知識レベルを測る指標として長年活用されてきました。LLMの基礎学力を測る「共通テスト」のような存在だと考えてください。
しかし、2026年現在、多くの最先端モデルが90%以上のスコアを記録し、性能差が見えにくい「飽和状態」にあるのが実情です。この課題に対応するため、現在はより高難易度な後継指標「MMLU-Pro」が主流となっています。MMLU-Proは選択肢を4択から10択に増やし、大学院レベルの問題を含むことで、モデルの真の推論能力を評価する設計である点が大きな違いです。
リーダーボードは無料で閲覧できます。LLMの基礎知識レベルを確認したい方や、MMLU-Proのスコアと合わせてモデルの能力を多角的に評価したい研究者・開発者におすすめです。
7位:Big-Bench Leaderboard
Googleが主導する「Big-Bench」は、200以上の多様なタスクでLLMの能力を多角的に評価する、非常に大規模なベンチマークです。言語理解から常識推論、数学的能力まで、モデルの総合的な知性を測定するために設計されています。
このベンチマークの強みは、その圧倒的なタスクの多様性と階層的な難易度設定にあります。特に、高難易度のタスクのみを抽出した「Big-Bench Hard (BBH)」は、最先端モデルの高度な推論能力を比較する際の事実上の標準指標となっています。2026年現在、Big-Bench自体の大きな更新はありませんが、BBHですら性能が飽和しつつあるため、さらに困難な「BIG-Bench Extra Hard (BBEH)」といった派生ベンチマークが提案されるなど、評価の最前線は常に進化を続けています。
Big-Benchはオープンソースで利用は無料ですが、評価の実行には相応の計算リソースが必要です。自社開発モデルの性能を客観的に示したい研究機関や、モデルの得意・不得意を詳細に分析したい開発者におすすめします。
8位:EleutherAI LM Evaluation Harness
EleutherAIが開発したLM Evaluation Harnessは、LLMの性能評価におけるデファクトスタンダードのオープンソースフレームワークです。Hugging Faceの「Open LLM Leaderboard」のバックエンドとしても全面的に採用されています。
主な特徴は、60以上の学術的ベンチマークに対応し、統一された基準で公平な性能比較を実現できる点です。コマンドラインインターフェース(CLI)から柔軟に評価を実行でき、Hugging FaceモデルやvLLMなど多様なバックエンドをサポートする高い拡張性も強みとなります。
最近のアップデートでは、Windows ML Backendがサポートされ、Windows環境での利用がより容易になりました。また、インストールプロセスが軽量化され、pip install lm_eval[hf]のように必要なバックエンドのみを選択して導入する形式に変更されたため、環境構築が迅速になった点も大きな改善点です。オープンソースのため、誰でも無料で利用できます。
自社開発モデルの性能を客観的に測定したい企業や、複数のLLMを公平な基準で比較・選定したい開発者に最適なツールです。
9位:C-Eval Leaderboard
C-Evalは、中国語の大規模言語モデル(LLM)の知識と推論能力を多角的に評価するために設計された、包括的なベンチマークです。人文科学、社会科学、理工学など52の多様な分野をカバーする13,948個の多肢選択問題で構成されています。
このベンチマークの強みは、中国語のLLM評価における「標準的な物差し」として機能する点にあります。開発者はHugging Faceなどで公開されているテストセットを使い、ローカル環境で自社モデルの性能を客観的に測定可能です。ただし、最も重要な注意点として、公式サイトのリーダーボードは2025年7月26日をもって更新を停止しており、最新モデル同士のランキング比較には利用できません。これは、テストセットの公開に伴い、誰でも手元で評価できるようになったためです。データセットは無料で利用できます。
中国語対応のLLMを開発・研究しており、その基礎的な知識レベルを標準化された指標で評価したい開発者や企業に適しています。
10位:Evals (by OpenAI)
10位は、OpenAIが提供するLLM評価フレームワーク「Evals」です。これは、様々な大規模言語モデルの性能を客観的かつ体系的に測定するためのオープンソースのツールキットであり、モデル選定や品質管理の基盤となります。
Evalsの強みは、標準化されたベンチマークによる再現性の高い評価と、カスタム評価の柔軟性にあります。YAMLファイルを定義するだけで、自社の業務に特化した独自の評価セットを構築し、一般的な指標では測れないビジネス固有の性能を比較検証することが可能です。プロンプト変更やモデル更新時の性能低下を自動で検知するリグレッションテストにも活用できます。2026年3月にはAIの堅牢性をテストするツール「Promptfoo」の買収が発表されており、OpenAIがモデル評価や安全性テストへ注力していることがうかがえます。
フレームワーク自体は無料ですが、評価の実行にはOpenAI APIを呼び出すため、そのAPI利用料が別途発生する点には注意が必要です。
自社サービスに最適なLLMを選定したい企業や、継続的な品質管理・リグレッションテストの自動化を目指す開発チームに最適な評価基盤です。
LLMリーダーボードの落とし穴|スコアだけ見て選ぶと失敗する理由と注意点
ここからは、llm leaderboardのおすすめ10選を紹介します。それぞれの特徴やメリットを詳しく解説していますので、導入検討の参考にしてください。
総合スコアが高くても特定タスクでは使えない罠
Hugging Face Open LLM Leaderboardは、世界中のオープンソース大規模言語モデル(LLM)の性能を客観的な指標で比較・評価できる、開発者や研究者にとって必須のプラットフォームです。最新モデルの性能をリアルタイムで把握するための、事実上の標準となっています。
このリーダーボードの強みは、複数のベンチマークに基づいた平均スコアによって、多様なモデルの性能を公平に比較できる点にあります。モデルの規模や精度(量子化の有無など)、ファインチューニングの有無で結果を絞り込めるため、自身の用途に最適なモデルを効率的に探せます。
2026年3月現在、スコア算出方法は正規化スコア方式が採用されており、高難易度ベンチマークでの僅かな性能向上がスコアに反映されやすくなりました。また、専門家レベルの質問応答能力を測る「GPQA」など、より実践的な新ベンチマークの導入により、評価の信頼性がさらに向上しています。
このプラットフォームは完全無料で利用でき、アカウント登録も不要です。
自身のプロジェクトに最適なオープンソースLLMを探している開発者や、LLM開発の最新トレンドをいち早くキャッチしたい研究者の方に特におすすめします。
ベンチマークへの過剰最適化とスコアの信頼性
LLM性能比較の事実上の標準となっているのが、第2位の「Arena」です。かつて「LMSys Chatbot Arena」として知られたこのプラットフォームは、匿名のAI2モデルの回答を人間が比較投票するユニークな方式で、より実践的な対話能力を測定します。
理論上のベンチマークスコアではなく、実際の対話における「人間の好み」をEloレーティングで数値化している点が最大の特徴。これにより、最新の商用モデルから話題のオープンソースモデルまで、公平な土俵で性能を直感的に比較することが可能です。近年では総合評価に加え、「コーディング」など専門分野別のリーダーボードや、高難度プロンプトに特化した「High ELO Ranking」も導入され、特定の用途における最適なモデル選定がより容易になりました。
リーダーボードの閲覧やチャット評価への参加は無料であるため、誰でも気軽に最新のLLMトレンドを追うことができます。最新モデルの性能を客観的に把握したい開発者や、自社サービスに導入するAIを選定する際の信頼できる判断材料を探している企業に強く推奨します。
人間評価に潜むバイアスとランキング操作のリスク
Japanese LLM Leaderboardは、無数に存在する日本語LLM(大規模言語モデル)の性能を、客観的な指標で比較・評価するための公開ランキングです。開発者や研究者がモデルを選定する際の、信頼できる羅針盤として機能します。
このリーダーボードの最大の強みは、統一されたベンチマークに基づいて各モデルの能力をスコア化し、誰でも閲覧できる形で公開している点です。質問応答や文章要約といった基本的な能力に加え、コーディングや関数呼び出しといった、より実用的なアプリケーション開発能力も評価対象となっています。これにより、自社の用途に最適なモデルをデータに基づいて選定することが可能です。
2026年に入り、Weights & Biasesが運営する「Nejumi LLM Leaderboard 4」では、高難度の推論能力を測る評価基準が追加されるなど、最先端モデルの性能を正確に測るためのアップデートが継続的に行われています。これらのリーダーボードは基本的に無料で閲覧できるため、コストをかけずに最新のLLM開発動向を把握できる点も大きなメリットでしょう。
自社プロジェクトに導入するLLMを選定したい開発者や、開発したモデルの性能を客観的に測りたい研究機関におすすめです。
まとめ:自社の目的に合ったLLMリーダーボードで開発を加速させよう
本記事では、目的別に10種類のLLMリーダーボードを紹介しました。これらは単なる性能ランキングではなく、自社のAI開発プロジェクトの方向性を定めるための羅針盤となる重要なツールです。
例えば、最新オープンソースモデルの基礎性能を広く比較したいならHugging Face Open LLM Leaderboardを、ユーザーの体感に近い自然な対話能力を重視するならLMSys Chatbot Arena Leaderboardを確認しましょう。もちろん、日本語のビジネス利用を検討するならJapanese LLM Leaderboardの動向は無視できません。大切なのは、単一のスコアを鵜呑みにせず、自社のユースケースに照らし合わせて複数のリーダーボードを多角的に評価することです。
「どのモデルが自社の課題解決に最適か判断できない」「LLMを導入して具体的な成果に繋げたい」といった課題については、私たちOptiMaxがAI導入の戦略策定から開発・運用まで一気通貫で支援します。まずはお気軽にご相談ください。